Spark Core源码精读计划 | SparkContext组件初始化
目录
前言
SparkContext类的构造方法
SparkContext初始化的组件
SparkConf
LiveListenerBus
AppStatusStore
SparkEnv
SparkStatusTracker
ConsoleProgressBar
SparkUI
(Hadoop)Configuration
HeartbeatReceiver
SchedulerBackend
TaskScheduler
DAGScheduler
EventLoggingListener
ExecutorAllocationManager
ContextCleaner
总结
前言
SparkContext在整个Spark Core中的地位毋庸置疑,可以说是核心中的核心。它存在于Driver中,是Spark功能的主要入口,如果没有SparkContext,我们的应用就无法运行,也就无从享受Spark为我们带来的种种便利。
由于SparkContext类的内容较多(整个SparkContext.scala文件共有2900多行),因此我们不追求毕其功于一役,而是拆成三篇文章来讨论。本文主要研究SparkContext初始化过程中涉及到的那些Spark组件,并对它们进行介绍。
SparkContext类的构造方法
SparkContext类接收SparkConf作为构造参数,并且有多种辅助构造方法的实现,比较简单,不多废话了。
代码#2.1 - o.a.s.SparkContext类的辅助构造方法
class SparkContext(config: SparkConf) extends Logging {
// ...
def this() = this(new SparkConf())
def this(master: String, appName: String, conf: SparkConf) =
this(SparkContext.updatedConf(conf, master, appName))
def this(
master: String,
appName: String,
sparkHome: String = null,
jars: Seq[String] = Nil,
environment: Map[String, String] = Map()) = {
this(SparkContext.updatedConf(new SparkConf(), master, appName, sparkHome, jars, environment))
}
private[spark] def this(master: String, appName: String) =
this(master, appName, null, Nil, Map())
private[spark] def this(master: String, appName: String, sparkHome: String) =
this(master, appName, sparkHome, Nil, Map())
private[spark] def this(master: String, appName: String, sparkHome: String, jars: Seq[String]) =
this(master, appName, sparkHome, jars, Map())
// ...
}而其主构造方法主要由一个巨大的try-catch块组成,位于SparkContext.scala的362~586行,它内部包含了很多初始化逻辑。
SparkContext初始化的组件
在上述try-catch块的前方,有一批预先声明的私有变量字段,且基本都重新定义了对应的Getter方法。它们用于维护SparkContext需要初始化的所有组件的内部状态。下面的代码清单将它们预先整理出来。
代码#2.2 - SparkContext中的组件字段及Getter
private var _conf: SparkConf = _
private var _listenerBus: LiveListenerBus = _
private var _env: SparkEnv = _
private var _statusTracker: SparkStatusTracker = _
private var _progressBar: Option[ConsoleProgressBar] = None
private var _ui: Option[SparkUI] = None
private var _hadoopConfiguration: Configuration = _
private var _schedulerBackend: SchedulerBackend = _
private var _taskScheduler: TaskScheduler = _
private var _heartbeatReceiver: RpcEndpointRef = _
@volatile private var _dagScheduler: DAGScheduler = _
private var _eventLogger: Option[EventLoggingListener] = None
private var _executorAllocationManager: Option[ExecutorAllocationManager] = None
private var _cleaner: Option[ContextCleaner] = None
private var _statusStore: AppStatusStore = _
private[spark] def conf: SparkConf = _conf
private[spark] def listenerBus: LiveListenerBus = _listenerBus
private[spark] def env: SparkEnv = _env
def statusTracker: SparkStatusTracker = _statusTracker
private[spark] def progressBar: Option[ConsoleProgressBar] = _progressBar
private[spark] def ui: Option[SparkUI] = _ui
def hadoopConfiguration: Configuration = _hadoopConfiguration
private[spark] def schedulerBackend: SchedulerBackend = _schedulerBackend
private[spark] def taskScheduler: TaskScheduler = _taskScheduler
private[spark] def taskScheduler_=(ts: TaskScheduler): Unit = {
_taskScheduler = ts
}
private[spark] def dagScheduler: DAGScheduler = _dagScheduler
private[spark] def dagScheduler_=(ds: DAGScheduler): Unit = {
_dagScheduler = ds
}
private[spark] def eventLogger: Option[EventLoggingListener] = _eventLogger
private[spark] def executorAllocationManager: Option[ExecutorAllocationManager] = _executorAllocationManager
private[spark] def cleaner: Option[ContextCleaner] = _cleaner
private[spark] def statusStore: AppStatusStore = _statusStore下面,我们按照SparkContext初始化的实际顺序,依次对这些组件作简要的了解,并且会附上一部分源码。
SparkConf
SparkConf在文章#1已经详细讲过。它其实不算初始化的组件,因为它是构造SparkContext时传进来的参数。SparkContext会先将传入的SparkConf克隆一份副本,之后在副本上做校验(主要是应用名和Master的校验),及添加其他必须的参数(Driver地址、应用ID等)。这样用户就不可以再更改配置项,以保证Spark配置在运行期的不变性。
LiveListenerBus
LiveListenerBus是SparkContext中的事件总线。它异步地将事件源产生的事件(SparkListenerEvent)投递给已注册的监听器(SparkListener)。Spark中广泛运用了监听器模式,以适应集群状态下的分布式事件汇报。
除了它之外,Spark中还有多种事件总线,它们都继承自ListenerBus特征。事件总线是Spark底层的重要支撑组件,之后会专门分析。
AppStatusStore
AppStatusStore提供Spark程序运行中各项监控指标的键值对化存储。Web UI中见到的数据指标基本都存储在这里。其初始化代码如下。
代码#2.3 - 构造方法中AppStatusStore的初始化
_statusStore = AppStatusStore.createLiveStore(conf)
listenerBus.addToStatusQueue(_statusStore.listener.get)代码#2.4 - o.a.s.status.AppStatusStore.createLiveStore()方法
def createLiveStore(conf: SparkConf): AppStatusStore = {
val store = new ElementTrackingStore(new InMemoryStore(), conf)
val listener = new AppStatusListener(store, conf, true)
new AppStatusStore(store, listener = Some(listener))
}
可见,AppStatusStore底层使用了ElementTrackingStore,它是能够跟踪元素及其数量的键值对存储结构,因此适合用于监控。另外还会产生一个监听器AppStatusListener的实例,并注册到前述LiveListenerBus中,用来收集监控数据。
SparkEnv
SparkEnv是Spark中的执行环境。Driver与Executor的运行都需要SparkEnv提供的各类组件形成的环境来作为基础。其初始化代码如下。
代码#2.5 - 构造方法中SparkEnv的初始化
_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkEnv.set(_env)代码#2.6 - o.a.s.SparkContext.createSparkEnv()方法
private[spark] def createSparkEnv(
conf: SparkConf,
isLocal: Boolean,
listenerBus: LiveListenerBus): SparkEnv = {
SparkEnv.createDriverEnv(conf, isLocal, listenerBus, SparkContext.numDriverCores(master))
}可见,SparkEnv的初始化依赖于LiveListenerBus,并且在SparkContext初始化时只会创建Driver的执行环境,Executor的执行环境就是后话了。在创建Driver执行环境后,会调用SparkEnv伴生对象中的set()方法保存它,这样就可以“一处创建,多处使用”SparkEnv。
通过SparkEnv管理的组件也有多种,比如SparkContext中就会出现的安全性管理器SecurityManager、RPC环境RpcEnv、存储块管理器BlockManager、监控度量系统MetricsSystem。在SparkContext构造方法的后方,就会藉由SparkEnv先初始化BlockManager与启动MetricsSystem。
代码#2.7 - 构造方法中BlockManager的初始化与MetricsSystem的启动
_env.blockManager.initialize(_applicationId)
_env.metricsSystem.start()
_env.metricsSystem.getServletHandlers.foreach(handler => ui.foreach(_.attachHandler(handler)))由于SparkEnv的重要性和复杂性,后面会专门写文章来讲解它,这里只需要有个大致的了解即可。
SparkStatusTracker
SparkStatusTracker提供报告最近作业执行情况的低级API。它的内部只有6个方法,从AppStatusStore中查询并返回诸如Job/Stage ID、活跃/完成/失败的Task数、Executor内存用量等基础数据。它只能保证非常弱的一致性语义,也就是说它报告的信息会有延迟或缺漏。
ConsoleProgressBar
ConsoleProgressBar按行打印Stage的计算进度。它周期性地从AppStatusStore中查询Stage对应的各状态的Task数,并格式化成字符串输出。它可以通过spark.ui.showConsoleProgress参数控制开关,默认值false。
SparkUI
SparkUI维护监控数据在Spark Web UI界面的展示。它的样子在文章#0的图中已经出现过,因此不再赘述。其初始化代码如下。
代码#2.8 - 构造方法中SparkUI的初始化
_ui =
if (conf.getBoolean("spark.ui.enabled", true)) {
Some(SparkUI.create(Some(this), _statusStore, _conf, _env.securityManager, appName, "",
startTime))
} else {
None
}
_ui.foreach(_.bind())可以通过spark.ui.enabled参数来控制是否启用Spark UI,默认值true。然后调用SparkUI的父类WebUI的bind()方法,将Spark UI绑定到特定的host:port上,如文章#0中的localhost:4040。
(Hadoop)Configuration
Spark可能会依赖于Hadoop的一些组件运行,如HDFS和YARN,Spark官方也有针对Hadoop 2.6/2.7的预编译包供下载。
SparkContext会借助工具类SparkHadoopUtil初始化一些与Hadoop有关的配置,存放在Hadoop的Configuration实例中,如Amazon S3相关的配置,和以“spark.hadoop.”为前缀的Spark配置参数。
HeartbeatReceiver
HeartbeatReceiver是心跳接收器。Executor需要向Driver定期发送心跳包来表示自己存活。它本质上也是个监听器,继承了SparkListener。其初始化代码如下。
代码#2.9 - 构造方法中HeartbeatReceiver的初始化
_heartbeatReceiver = env.rpcEnv.setupEndpoint(
HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))可见,HeartbeatReceiver通过RpcEnv最终包装成了一个RPC端点的引用,即代码#2.2中的RpcEndpointRef。
Spark集群的节点间必然会涉及大量的网络通信,心跳机制只是其中的一方面而已。因此RPC框架同事件总线一样,是Spark底层不可或缺的组成部分。
SchedulerBackend
SchedulerBackend负责向等待计算的Task分配计算资源,并在Executor上启动Task。它是一个Scala特征,有多种部署模式下的SchedulerBackend实现类。它在SparkContext中是和TaskScheduler一起初始化的,作为一个元组返回。
TaskScheduler
TaskScheduler即任务调度器。它也是一个Scala特征,但只有一种实现,即TaskSchedulerImpl类。它负责提供Task的调度算法,并且会持有SchedulerBackend的实例,通过SchedulerBackend发挥作用。它们两个的初始化代码如下。
代码#2.10 - 构造方法中SchedulerBackend与TaskScheduler的初始化
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts下面这个方法比较长,但就当做是提前知道一下Spark的几种Master设置方式吧。它包括有三种本地模式、本地集群模式、Standalone模式,以及第三方集群管理器(如YARN)提供的模式。
代码#2.11 - o.a.s.SparkContext.createTaskScheduler()方法
private def createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler) = {
import SparkMasterRegex._
// When running locally, don't try to re-execute tasks on failure.
val MAX_LOCAL_TASK_FAILURES = 1
master match {
case "local" =>
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, 1)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_N_REGEX(threads) =>
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
// local[*] estimates the number of cores on the machine; local[N] uses exactly N threads.
val threadCount = if (threads == "*") localCpuCount else threads.toInt
if (threadCount <= 0) {
throw new SparkException(s"Asked to run locally with $threadCount threads")
}
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_N_FAILURES_REGEX(threads, maxFailures) =>
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
// local[*, M] means the number of cores on the computer with M failures
// local[N, M] means exactly N threads with M failures
val threadCount = if (threads == "*") localCpuCount else threads.toInt
val scheduler = new TaskSchedulerImpl(sc, maxFailures.toInt, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler)
case SPARK_REGEX(sparkUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_CLUSTER_REGEX(numSlaves, coresPerSlave, memoryPerSlave) =>
// Check to make sure memory requested <= memoryPerSlave. Otherwise Spark will just hang.
val memoryPerSlaveInt = memoryPerSlave.toInt
if (sc.executorMemory > memoryPerSlaveInt) {
throw new SparkException(
"Asked to launch cluster with %d MB RAM / worker but requested %d MB/worker".format(
memoryPerSlaveInt, sc.executorMemory))
}
val scheduler = new TaskSchedulerImpl(sc)
val localCluster = new LocalSparkCluster(
numSlaves.toInt, coresPerSlave.toInt, memoryPerSlaveInt, sc.conf)
val masterUrls = localCluster.start()
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
backend.shutdownCallback = (backend: StandaloneSchedulerBackend) => {
localCluster.stop()
}
(backend, scheduler)
case masterUrl =>
val cm = getClusterManager(masterUrl) match {
case Some(clusterMgr) => clusterMgr
case None => throw new SparkException("Could not parse Master URL: '" + master + "'")
}
try {
val scheduler = cm.createTaskScheduler(sc, masterUrl)
val backend = cm.createSchedulerBackend(sc, masterUrl, scheduler)
cm.initialize(scheduler, backend)
(backend, scheduler)
} catch {
case se: SparkException => throw se
case NonFatal(e) =>
throw new SparkException("External scheduler cannot be instantiated", e)
}
}
}DAGScheduler
DAGScheduler即有向无环图(DAG)调度器。DAG的概念在文章#0中已经讲过,用来表示RDD之间的血缘。DAGScheduler负责生成并提交Job,以及按照DAG将RDD和算子划分并提交Stage。每个Stage都包含一组Task,称为TaskSet,它们被传递给TaskScheduler。也就是说DAGScheduler需要先于TaskScheduler进行调度。
DAGScheduler初始化是直接new出来的,但在其构造方法里也会将SparkContext中TaskScheduler的引用传进去。因此要等DAGScheduler创建后,再真正启动TaskScheduler。
代码#2.12 - 构造方法中DAGScheduler的初始化和TaskScheduler的启动
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
_taskScheduler.start()SchedulerBackend、TaskScheduler与DAGScheduler是Spark调度逻辑的主要组成部分,之后会深入探索它们的细节。
值得注意的是,代码#2.2中只有TaskScheduler与DAGScheduler还定义了Setter方法,目前只在内部测试方法中调用过。
EventLoggingListener
EventLoggingListener是用于事件持久化的监听器。它可以通过spark.eventLog.enabled参数控制开关,默认值false。如果开启,它也会注册到LiveListenerBus里,并将特定的一部分事件写到磁盘。
ExecutorAllocationManager
ExecutorAllocationManager即Executor分配管理器。它可以通过spark.dynamicAllocation.enabled参数控制开关,默认值false。如果开启,并且SchedulerBackend的实现类支持这种机制,Spark就会根据程序运行时的负载动态增减Executor的数量。它的初始化代码如下。
代码#2.13 - 构造方法中ExecutorAllocationManager的初始化
val dynamicAllocationEnabled = Utils.isDynamicAllocationEnabled(_conf)
_executorAllocationManager =
if (dynamicAllocationEnabled) {
schedulerBackend match {
case b: ExecutorAllocationClient =>
Some(new ExecutorAllocationManager(
schedulerBackend.asInstanceOf[ExecutorAllocationClient], listenerBus, _conf,
_env.blockManager.master))
case _ =>
None
}
} else {
None
}
_executorAllocationManager.foreach(_.start())ContextCleaner
ContextCleaner即上下文清理器。它可以通过spark.cleaner.referenceTracking参数控制开关,默认值true。它内部维护着对RDD、Shuffle依赖和广播变量(之后会提到)的弱引用,如果弱引用的对象超出程序的作用域,就异步地将它们清理掉。
总结
本文从SparkContext的构造方法入手,按顺序简述了十余个Spark内部组件及其初始化逻辑。这些组件覆盖了Spark机制的多个方面,我们之后在适当的时机还要深入研究其中的一部分,特别重要的如事件总线LiveListenerBus、执行环境SparkEnv、调度器TaskScheduler及DAGScheduler等。
最后用一张图来概括吧。
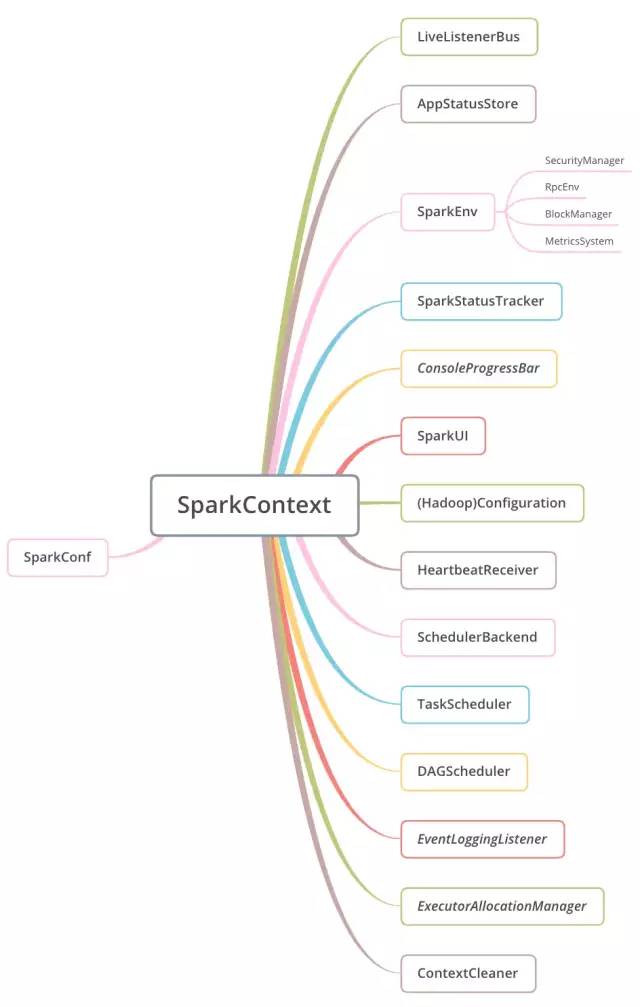
除了组件初始化之外,SparkContext内还有其他一部分有用的属性。并且在初始化的主流程做完之后,也有不少善后工作要做。下一篇文章就会分析它们。
— THE END —
