内存脏数据下刷(linux2.6.18/linux.2.6.32)剖析
BDI机制原本主要是用于检测磁盘的繁忙程度等作用,从2.6.19内核开始,将此部分功能整合到了mm/backing_dev.c中,一直到2.6.31内核为止,其功能也只是在不段的完善,但是脏数据的下刷依然是依靠pdflush。自2.6.32内核开始,彻底取消了pdflush,而是将此部分功能添加到BDI机制中,并且是为每个设备创建了一个名为“flush-设备主次设备号”的线程,用于脏数据的下刷。
2 结构backing_dev_info
了解BDI机制,首先得清楚结构backing_dev_info,其定义在描述设备的结构gendisk->request_queue内。
2.1 Kernel-2.6.18
在2.6.18内核中其定义如下:
struct backing_dev_info {
unsigned long ra_pages; /* maxreadahead in PAGE_CACHE_SIZE units */
unsigned long state; /* Always use atomic bitops on this */
unsigned int capabilities; /*Device capabilities */
congested_fn *congested_fn; /*Function pointer if device is md/dm */
void *congested_data; /* Pointer to aux data for congested func */
void (*unplug_io_fn)(structbacking_dev_info *, struct page *);
void *unplug_io_data;
};
其对应的state状态有:
enum bdi_state {
BDI_pdflush, /* A pdflush thread is working thisdevice */
BDI_write_congested, /* Thewrite queue is getting full */
BDI_read_congested, /* Theread queue is getting full */
BDI_unused, /* Available bits start here */
};
其初始化在:
a) 函数blk_queue_make_request:初始化ra_pages、state、capabilities
b) 函数blk_alloc_queue_node:初始化unplug_io_fn、unplug_io_data
2.2 Kernel-2.6.32
在2.6.32内核中其定义如下:
struct backing_dev_info {
struct list_head bdi_list;
struct rcu_head rcu_head;
unsigned long ra_pages; /* maxreadahead in PAGE_CACHE_SIZE units */
unsigned long state; /* Always use atomic bitops on this */
unsigned int capabilities; /*Device capabilities */
congested_fn *congested_fn; /* Functionpointer if device is md/dm */
void *congested_data; /* Pointer to aux data for congested func */
void (*unplug_io_fn)(structbacking_dev_info *, struct page *);
void *unplug_io_data;
char *name; /* device_name */
struct percpu_counterbdi_stat[NR_BDI_STAT_ITEMS];
struct prop_local_percpucompletions;
int dirty_exceeded;
unsigned int min_ratio;
unsigned int max_ratio, max_prop_frac;
struct bdi_writeback wb; /* default writeback info for this bdi */
spinlock_t wb_lock; /* protects update side of wb_list */
struct list_head wb_list; /* theflusher threads hanging off this bdi */
struct list_head work_list;
struct device *dev;
#ifdef CONFIG_DEBUG_FS
struct dentry *debug_dir;
struct dentry *debug_stats;
#endif
};
其对应的state状态有:
enum bdi_state {
BDI_pending, /* On its way to being activated */
BDI_wb_alloc, /* Default embedded wb allocated */
BDI_async_congested, /* Theasync (write) queue is getting full */
BDI_sync_congested, /* Thesync queue is getting full */
BDI_registered, /* bdi_register() was done */
BDI_unused, /* Available bits start here */
};
用于sys接口计数统计的数值:
enum bdi_stat_item {
BDI_RECLAIMABLE,
BDI_WRITEBACK,
NR_BDI_STAT_ITEMS
};
其初始化在:
a) 函数blk_alloc_queue_node:初始化ra_pages、state、capabilities、unplug_io_fn、unplug_io_data、name
b) 函数blk_alloc_queue_node-->bdi_init:初始化其他的值
2.3 总结
Kernel2.6.32想比kernel-2.6.18来说,在此结构中增加了一些与下刷有关的内容,也就是说在kernel2.6.32中,下刷相关的已经整合到BDI机制中。
用于描述设备bdi状态的信息,也略微做了调整:
1. 用于读写队列拥塞判断的标记只是名称改变了;
2. 由于下刷线程的调整,使得标记BDI_pdflush的功能已经变了,从名称改为BDI_pending也可以看出:
a) 在2.6.18中pdflush线程为全局的,在下刷哪个设备,可以给哪个设备设置上BDI_pdflush标记用来表示该设备正处于下刷中;
b) 在2.6.32中,flush线程因为整合到bdi机制中,每个设备有一个backing_dev_info结构,必然会导致每个设备一个flush线程,那么当这个设备处于下刷时,可以设置BDI_pending标记
3. 在2.6.18基础上,扩充了新的标记BDI_wb_alloc和BDI_registered,前者表示该设备上已经申请出一个下刷任务,后者表示该设备已经创建了flush线程。
由于backing_dev_info结构中描述每个设备的一些bdi状态信息,BDI中提供了一个sys接口,在/sys/kernel/debug/bdi目录下,每个设备以设备号区分,可以查看每个设备与bdi有关的状态等。
了解了2.6.32中下刷线程的改变,下面就以IO路径做为入口点开始调研。
3 写流程

对比以上2个流程可以看到:
1. 相同点:整体流程都一样,部分不一样的地方,也只是函数封装的不同,实现上都一样;
2. 不同点:在唤醒下刷脏数据的线程时,2.6.18调用pdflush线程,2.6.32调用的是bdi的workqueue。
从以上的不同点可以看出,在2.6.32内核中,下刷的工作已经交给了BDI机制。那么下面继续看两种内核中下刷线程是如何初始化以及下刷时机上有什么区别。
4 下刷线程初始化
4.1 Kernel-2.6.18
下刷线程初始化函数在mm/pdflush.c文件中。
在此文件中定义了如下两个宏:
1. MIN_PDFLUSH_THREADS 2
2. MAX_PDFLUSH_THREADS 8
初始化时,创建了MIN_PDFLUSH_THREADS个名为pdflush的线程,然后将线程加入链表pdflush_list中,线程执行函数为pdflush。
这里定义了结构pdflush_work来描述每一个pdflush线程:
struct pdflush_work {
structtask_struct *who; /* The thread */
void(*fn)(unsigned long); /* A callbackfunction */
unsignedlong arg0; /* Anargument to the callback */
structlist_head list; /* Onpdflush_list, when idle */
unsignedlong when_i_went_to_sleep;
};
在执行函数pdflush中,会有以下部分检测:
if (jiffies - last_empty_jifs > 1 *HZ) {
/* unlocked list_empty() test is OK here*/
if(list_empty(&pdflush_list)) {
/* unlocked test is OK here */
if(nr_pdflush_threads < MAX_PDFLUSH_THREADS)
start_one_pdflush_thread();
}
}
上面代码说明,如果在上次pdflush线程被唤醒时,导致了链表pdflush_list为空,本次线程被唤醒举例上次链表为空的时间大于1s,且链表依然为空,那么可以主动再创建一个pdflush线程。从判断上来看,最多可以创建8个pdflush线程。
每次下刷任务完成后,有如下判断:
if(list_empty(&pdflush_list))
continue;
if (nr_pdflush_threads <=MIN_PDFLUSH_THREADS)
continue;
pdf = list_entry(pdflush_list.prev,struct pdflush_work, list);
if (jiffies -pdf->when_i_went_to_sleep > 1 * HZ) {
/* Limit exit rate */
pdf->when_i_went_to_sleep = jiffies;
break; /* exeunt */
}
如果线程数大于2,并且当前线程距离上次被唤醒处理下刷任务的时间已经大于1s,那么可以认定当前下刷线程是比较空闲的,可以销毁。也就是说,当有写IO时,系统中最多时可以唤醒8个pdflush,当空闲时,系统只保留2个pdflush。
4.2 Kernel-2.6.32
4.2.1 系统启动时
在kernel启动时,会加载BDI模块,代码定义在文件mm/backing-dev.c中:
1. 创建名为sync_supers的线程,此线程由定时器来唤醒,此外无其他唤醒模式。每5s钟被唤醒执行一次函数sync_supers,用来下刷系统super_blocks链表中所有的元数据块信息。
2. 定义了一个默认的结构backing_dev_info,同时会创建一个线程bdi-default,此线程执行函数为bdi_forker_task。
a) 此函数为一个死循环,中途无任何退出条件。
b) 当有新的设备被创建时:
i. 会为每个设备定义一个结构backing_dev_info,然后将此结构挂到bdi_list链表尾;
ii. bdi-default线程会从bdi_list链表中获取每个设备的结构bdi信息,将之从bdi_list链表中删除,再加入bdi_pending_list;
iii. 然后从bdi_pending_list链表中获取每个设备的bdi信息,同时将此设备的bdi信息从bdi_pending_list链表中删除;
iv. 为每个设备创建一个下刷线程“flush-主设备号:次设备号”,描述线程信息的结构为bdi_writeback,其执行函数为bdi_start_fn;
v. 当flush线程执行起来后,会再次将设备的bdi信息加入链表bdi_list尾,这样每个设备的flush线程就可以从bdi_list上找到并唤醒了。
c) 当bdi_pending_list链表为空时会睡眠5s,然后再自我唤醒,继续运行。
下面为结构bdi_writeback的定义:
struct bdi_writeback {
struct list_head list; /* hangs off the bdi */
struct backing_dev_info *bdi; /* our parent bdi */
unsigned int nr;
unsigned long last_old_flush; /* last old data flush */
struct task_struct *task; /* writeback task */
struct list_head b_dirty; /* dirty inodes */
struct list_head b_io; /* parked for writeback */
structlist_head b_more_io; /* parked for more writeback */
};
4.2.2 设备创建时
当有新设备创建时,每个设备都有自己的gendisk--> request_queue --> backing_dev_info结构,在调用函数block/genhd.c:add_disk函数时,会调用bdi_register_dev函数,为每个设备申请结构device并初始化此结构信息,最终会调用函数bdi_register,将此设备bdi信息加入链表bdi_list中。之后就如同上面一样,bdi-default线程会为该设备创建线程flush。
每个设备flush线程的执行函数为bdi_start_fn,其核心流程在函数bdi_writeback_task内,流程如下:

上面流程中线程空闲时间的判断,是线程每5s被唤醒时,都没有脏数据被下刷,则认为线程已经空闲,当空闲>300HZ,则会退出此函数,即线程被注销了。从这里也可以看出每个设备的flush线程并不常存在,只有需要时才创建出来。
5 下刷时机
5.1 Kernel-2.6.18
在2.6.18内核中,有同步下刷和异步下刷两种情况。
5.1.1 异步下刷
在kernel-2.6.18中,触发异步下刷流程的函数有pdflush_operation和wakeup_pdflush。
函数mm/pdflush.c:pdflush_operation被调用地方:
1. fs/super.c:emergency_remount --> pdflush_operation(do_emergency_remount, 0)
函数do_emergency_remount真正要做的并不是下刷数据,而是要以只读的形式remount文件系统,可通过给sysrq发信号调用。
2. fs/buffer.c:emergency_sync --> pdflush_operation(do_sync, 0)
函数do_sync会依次调用以下wakeup_pdflush(0)sync_inodes(0) sync_supers() sync_filesystems(0)等命令,sync模式下刷整个系统的数据,可通过给sysrq发信号调用。
3. mm/page-writeback.c:
a) balance_dirty_pages -->pdflush_operation(background_writeout, 0)
函数background_writeout,正常的下刷函数,上面函数第二个参数表示下刷任务,一般为0表示此次下刷到水位值,此部分流程同cbd中下刷部分。
b) wakeup_pdflush(nr_pages) -->pdflush_operation(background_writeout, nr_pages)
下刷指定个page的数据块。
c) wb_timer_fn --> pdflush_operation(wb_kupdate, 0)
定时触发的下刷方式,每次被触发后,都会下刷到水位值为止。默认5s钟调用一次。
d) laptop_timer_fn -->pdflush_operation(laptop_flush, 0)
函数laptop_flush也是会被定时触发,此函数会调用do_sync(1)函数,此函数只有在laptop_mode值为1时会被主动触发一次,一般在系统停止运行时触发。
函数mm/page-writeback.c:wakeup_pdflush被调用地方:
1. fs/buffer.c:
a) wakeup_pdflush(0):上面的do_sync函数调用,用于下刷当前所有的脏数据
b) wakeup_pdflush(1024):在函数free_more_memory中调用,当使用函数alloc_page_buffers申请page时,可能会触发此次下刷,希望先下刷一部分脏数据,以能够申请更多的page
2. mm/vmscan.c: wakeup_pdflush(laptop_mode ? 0 :total_scanned)
回收流程中触发的下刷,当前脏数据过多,需要先下刷一部分脏数据才能完成回收任务。
5.1.2 同步下刷
为了了解同步下刷在哪些地方调用,需要注意结构writeback_control的使用地方,
此结构在真正要下刷数据时(包括同步下刷和异步下刷),都会先初始化,用来指导当次以何种方式下刷,下刷多少数据等。
结构定义如下:
struct writeback_control {
struct backing_dev_info*bdi; /* If !NULL, only write back this
queue */
enum writeback_sync_modessync_mode;
unsigned long *older_than_this;/* If !NULL, only write back inodes
older than this */
long nr_to_write; /* Write this many pages, anddecrement
thisfor each page written */
long pages_skipped; /* Pages which were not written */
/*
* Fora_ops->writepages(): is start or end are non-zero then this is
* a hint that thefilesystem need only write out the pages inside that
* byterange. The byte at `end' is included in the writeoutrequest.
*/
loff_t range_start;
loff_t range_end;
unsigned nonblocking:1; /* Don't get stuck on request queues*/
unsigned encountered_congestion:1;/* An output: a queue is full */
unsigned for_kupdate:1; /* A kupdate writeback */
unsigned for_reclaim:1; /* Invoked from the page allocator */
unsigned for_writepages:1; /* This is a writepages() call */
unsigned range_cyclic:1; /* range_start is cyclic */
};
初始化此结构时,有时候只需要使用部分数值。
下面再看看哪些函数初始化了结构writeback_control(只列出几个核心的函数):
1. 函数mm/vmscan.c::shrink_page_list:回收时,发现某个page为脏,会试图以sync模式先将此page下刷下去
2. 函数mm/filemap.c::__filemap_fdatawrite_range:当是direct模式写数据时,会调用到此函数
3. 函数mm/page-writeback.c::write_one_page:此函数只用于写一个page,一般也是需要同步的写数据时调用
4. 函数mm/page-writeback.c::balance_dirty_pages:函数在写IO路径中被调用,主要是元数据的写
5. 函数fs/fs-writeback.c::write_inode_now:此函数多用于元数据的下刷
6. 函数fs/fs-writeback.c::sync_inode_sb:此函数也是用于元数据的下刷
5.2 Kernel-2.6.32
在Kernel-2.6.32中,同样有同步下刷和异步下刷两种情况。
5.2.1 异步下刷
使用异步下刷的地方,都定义了结构wb_writeback_work,但是反过来条件并不成立,下面具体来讲解。
此结构定义在fs/fs-writeback.c文件中,用来描述一次下刷任务的信息,如该次下刷任务以何种模式下刷,下刷多少数据等,多用在唤醒下刷线程之前定义。
结构信息如下:
struct wb_writeback_work {
long nr_pages;
struct super_block *sb;
enum writeback_sync_modessync_mode;
int for_kupdate:1;
int range_cyclic:1;
int for_background:1;
struct list_head list; /* pending work list */
struct completion *done; /* setif the caller waits */
};
触发下刷的操作时,可以将此work挂到一个工作队列中,由下刷线程来完成任务;也可以用此结构的信息,指导结构writeback_control中的值,然后直接调用下刷函数,完成工作任务。
下面可以看看哪些函数初始化了结构wb_writeback_work:
1. 函数__bdi_start_writeback,调用此函数的地方有以下几处:
a) 函数bdi_start_writeback:此函数没有被使用;
b) 函数bdi_start_background_writeback:此函数只在之前讲的写流程时的那个位置使用。
c) 函数wakeup_flusher_threads:此函数调用地方只有以下几处:
i. fs/buffer.c:wakeup_flusher_threads(1024)
同2.6.18一样,在函数free_more_memory中被调用,在申请page时,有时候想要申请更多的pages,但是当前系统剩余的page达不到要申请的数值,这个时候就会尝试调用回收函数,回收部分脏page。
ii. fs/sync.c:wakeup_flusher_threads(0)
函数SYSCALL_DEFINE0(sync),即sys_sync函数中被调用,当执行sync命令时,会被触发。
iii. mm/page-writeback.c:wakeup_flusher_threads(0)
定时器laptop_timer_fn中调用,此定时器也以任务的形式加入到系统event工作队列中,当此任务被唤醒时,其会下刷当前检测到的所有脏数据。在函数blk_finish_request中被调用,当且仅当laptop_mode=1时才会被触发。在系统运行中laptop_mode=0,当执行reboot等操作时,此值会变成1。
iv. mm/vmscan.c:wakeup_flusher_threads(laptop_mode ? 0 : total_scanned)
回收线程中调用,触发时机和2.6.18一样。
2. 函数wb_check_old_data_flush:
此函数通过函数bdi_start_fn --> bdi_writeback_task --> wb_do_writeback调用,而bdi_start_fn为线程flush(每个设备有一个)的执行函数 。
3. 函数writeback_inodes_sb_nr:
此函数经过一系列的封装,在sync_filesystem(执行sync时会调用,不等待元数据下刷完成)和btrfs中函数shrink_delalloc(回收元数据函数)调用,此函数仅限于下刷元数据信息。
4. 函数sync_inodes_sb:
此函数在sync_filesystem(执行sync时会调用,需等待元数据下刷完成)中调用。
说明:上面的函数writeback_inodes_sb_nr和函数sync_inodes_sb虽然初始化了结构wb_writeback_work,但是也只是用来指导当前如何下刷元数据信息而已,其实并不能归纳到异步下刷章节,只是为了便于讲解,才放在这里。
5.2.2 同步下刷
一般在真正进行下刷数据之前都会定义结构writeback_control,所以此函数在异步下刷和同步下刷真正下刷数据时都会定义,而同步下刷用此结构的地方非常多,所以此章通过查询哪些函数定义了此结构,来确定哪里进行了同步下刷操作。
此结构定义在include/linux/writeback.h中,用来指导当前下刷如何进行,多在线程被唤醒后或者需要进行同步下刷时定义。
结构信息如下:
struct writeback_control {
enum writeback_sync_modessync_mode;
unsigned long *older_than_this;/* If !NULL, only write back inodes
older than this */
unsigned long wb_start; /* Time writeback_inodes_wb was
called. This is needed to avoid
extra jobs and livelock */
long nr_to_write; /* Write this many pages, anddecrement
this for each pagewritten */
long pages_skipped; /* Pages which were not written */
/*
* Fora_ops->writepages(): is start or end are non-zero then this is
* a hint that thefilesystem need only write out the pages inside that
* byterange. The byte at `end' is included in the writeoutrequest.
*/
loff_t range_start;
loff_t range_end;
unsigned nonblocking:1; /* Don't get stuck on request queues*/
unsignedencountered_congestion:1; /* An output: a queue is full */
unsigned for_kupdate:1; /* A kupdate writeback */
unsigned for_background:1; /* A background writeback */
unsigned for_reclaim:1; /* Invoked from the page allocator */
unsigned range_cyclic:1; /* range_start is cyclic */
unsigned more_io:1; /* more io to be dispatched */
/* reserved for RedHat */
unsigned long rh_reserved[5];
};
当需要向下层写数据或者下刷数据时,都可以预先定义此结构,将此结构传给真正写数据的函数,下刷函数会根据此结构初始化的值,完成当次写数据任务。
初始化此结构时,有时候只需要使用部分数值。
下面再看看哪些函数初始化了结构writeback_control(只列出几个核心的函数):
1. 函数mm/vmscan.c::shrink_page_list:回收时,发现某个page为脏,会试图以sync模式先将此page下刷下去
2. 函数mm/filemap.c::__filemap_fdatawrite_range:当是direct模式写数据时,会调用到此函数
3. 函数mm/page-writeback.c::write_one_page:此函数只用于写一个page,一般也是需要同步的写数据时调用
4. 函数mm/page-writeback.c::balance_dirty_pages:函数在写IO路径中被调用,主要是元数据的写
5. 函数fs/fs-writeback.c::write_inode_now:此函数多用于元数据的下刷
6. 函数fs/fs-writeback.c::sync_inode_metadata:此函数也是用于元数据的下刷
7. 函数fs/fs-writeback.c::wb_writeback:此函数被flush线程调用,前面讲过
5.3 下刷时机总结
综合前两节:
1. 对于元数据,一般都需要直接写下去,所以这个时候可以直接初始化结构writeback_control,调用writepage等函数将元数据写下去;
2. 对于一般的写IO流程、回收线程中的脏数据下刷流程,可以使用pdflush/flush线程完成下刷任务;
3. 相比2.6.18内核,在2.6.32中少了一个定时器的触发flush线程的机制,不过此部分是以另外一种实现方式来实现了同样的功能:
a) 在bdi初始化时,创建了一个线程sync_supers,此线程只是每隔5s被定时器唤醒,将当前的元数据下刷到底层磁盘
b) 在flush线程中,函数bdi_writeback_task和wb_check_old_data_flush中均有对下刷时间的判断:
i. 函数wb_check_old_data_flush中,如果此次下刷距离上次下刷不足5s,本次直接退出
ii. 函数bdi_writeback_task中,每隔5s,会自动进行一次下刷操作;另外,还会检测如果长达60s的时间,都没有脏数据被下刷,此函数会退出(意味着flush线程将被注销)。
6 下刷方式
6.1 Kernel-2.6.18
1. 对于元数据下刷、某个page的下刷,都是可以通过page或者inode找到要下刷的设备或者文件等;
2. 由水位触发的下刷、回收时触发的下刷,是通过调用函数wakeup_pdflush,此函数并没有指定下刷哪个设备,而是先从全局链表super_blocks中获取一个structsuper_block *sb,再在此结构中定义的链表sb->s_dirty和sb->s_io中查找下刷的数据,当任务完成,下刷任务终止。
说明:上面的实现逻辑可以看出当下刷某个设备的脏数据时,该设备上的脏数据没有下刷完毕,是不会下刷下一个设备的脏数据的,但是系统中又设计了2-8个pdflush,避免下刷任务在一个设备上停留很长时间;从设计上看,一次最多可以同时下刷8个设备的脏数据。
6.2 Kernel-2.6.32
1. 对于元数据下刷、某个page的下刷,都是可以通过page或者inode找到要下刷的设备或者文件等,最终都可以找到其backing_dev_info结构。
2. 由水位触发的下刷、回收时触发的下刷,是通过调用函数wakeup_flusher_threads,此函数并没有指定下刷哪个设备,而且通过查找mm/backing-dev.c中定义的全局链表bdi_list,找到链表上的每一个结构bdi,然后才逐个的唤醒每个设备上的flush线程进行下刷。
在前言部分提出了如下问题,在bwraid中当底层设备上还有asd、bwcache、cbd设备时,系统如何处理这些设备的下刷?
前面也已经提到,当新创建一个设备时,就会将设备对应的bdi信息挂到全局链表bdi_list尾,而在调用下刷函数wakeup_flusher_threads时,则是从bdi_list链表的头逐个唤醒设备的flush线程,所以同一时刻,多个设备可能同时进行脏数据下刷的操作。
7 下刷流程
在这里所说的流程主要是说writepages函数是如何实现的。单独列出此函数是因为在kernel-2.6.18和kernel-2.6.32有一点小区别,且这个函数类似cbd里的destage_blocks函数,主要就是做下刷工作的。
7.1 Kernel-2.6.18
在文件fs/block_dev.c中writepages函数被注册为generic_writepages函数,然后调用函数mpage_writepages完成一次下刷任务。
函数mpage_writepages输入参数有:
1. struct address_space *mapping:和cbd中的cache_space结构类似;
2. struct writeback_control *wbc:描述一次下刷任务、下刷模式的结构,同cbd中的writeback_ctrl结构;
3. get_block_t get_block:专门为文件系统(如:ext2,hfs,jfs,fat等)提供的一个函数指针,用于在下刷流程中执行特定的操作。本文以块设备为例,此参数传入为NULL,如果为NULL,在下刷某一个page时,就会调用a_ops->writepage(块设备中定义为函数blkdev_writepage)。
函数mpage_writepages流程如下:
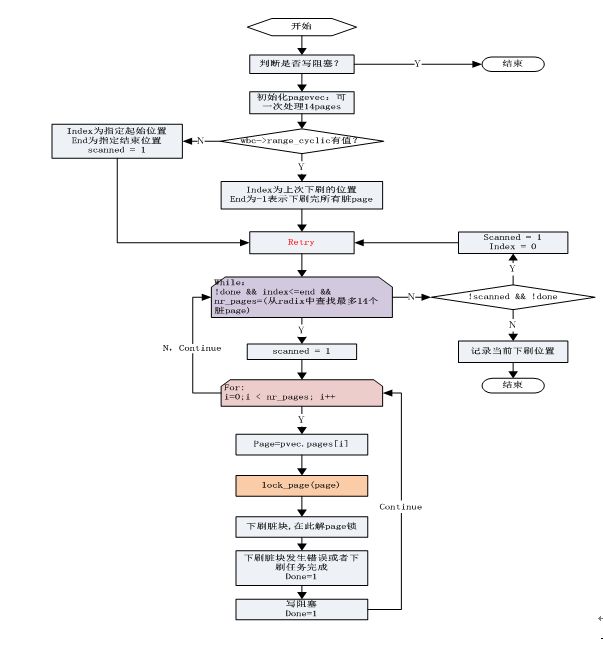
说明:在while循环中,上来先设置scanned = 1,使得在while循环结束后,一定会退出此次下刷任务。
7.2 Kernel-2.6.32
在文件fs/block_dev.c中writepages函数被注册为generic_writepages函数,然后调用函数write_cache_pages完成一次下刷任务。
函数write_cache_pages支持的传入参数有:
1. struct address_space *mapping:和cbd中的chache_space结构类似;
2. struct writeback_control *wbc:描述一次下刷任务、下刷模式的结构,同cbd中的writeback_ctrl结构;
3. writepage_t writepage:可以传入用来下刷一个page的函数,在这里传入的函数为__writepage;
4. void *data:可以定义一个自己的指针,做为函数__writepage其中一个参数,在函数__writepage中最终会调用mapping->a_ops->writepage(page, wbc) (块设备中定义为函数blkdev_writepage)。
函数write_cache_pages流程如下:
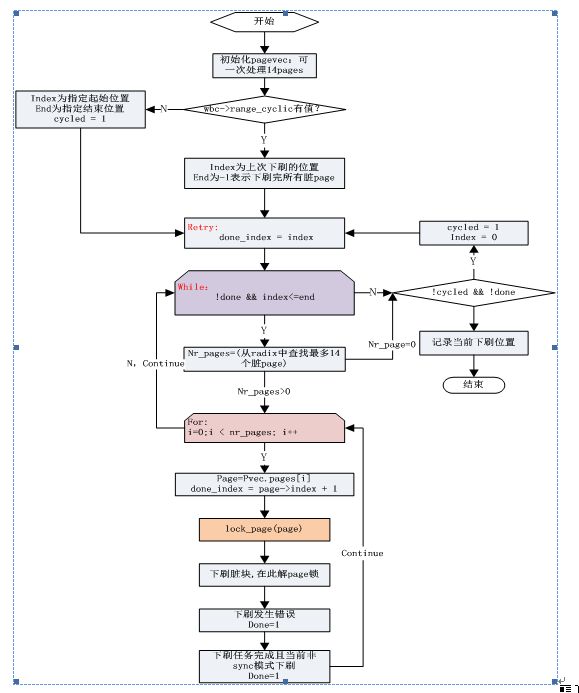
说明:
1. 取消了写阻塞的判断
2. 当sync模式下刷时,可能会刷到radix tree尾部之后再次从头部开始查找脏块继续刷一遍
7.3 下刷流程总结
两个内核下刷流程的对比,在kernel-2.6.32中,脏数据每次下刷不会判断写阻塞,而且其可能还会从raidix tree中查找两遍脏数据。一次下刷任务,比kernel-2.6.18下刷更多的数据。
8 总结
通过以上的调研可以知道,在2.6.32内核BDI机制中,在其功能基础上增加了脏数据下刷的部分,其管理着系统中设备的元数据的下刷、脏数据的下刷等。
相比2.6.18的全局pdflush,在2.6.32中每个设备都有一个flush线程,当有多个设备都有写IO时,2.6.32内核中下刷的效率就比2.6.18高,脏数据能够被更快的被下刷下去。
当底层磁盘处理io的速度非常高时,加大脏数据的下刷,可以使更多的写IO能够被及时的处理。但是在某些应用中,这么高效率的下刷脏数据,使得下刷脏数据不能进行更长的合并,下刷的脏数据就不够长。每个设备都在下刷数据时,也会造成磁盘更大的抖动。