快速定位线上CPU100%原因
引言
最近项目部门反应有个系统特别卡顿,很多页面都打不开了,开发人员告诉我说最近没有进行代码升级,我登录到对应的服务器上执行了top命令,发现cpu飙升到100%,对于这种问题我们应该快速的定位到问题,否则会影响线上系统的正常作业。
对于造成这种问题的可能原因,迅速的在头脑中闪过四种情况:
1、某个接口响应时间超长,并且可能被频繁调用
2、产生了过大的对象,造成频繁FGC
3、代码出现死循环
4、线程出现死锁
下面是小编的定位问题的步骤:
1)top
2)top -Hp 2848
3)printf "%x" 2925
4)jstack 2848 | grep 0xb6d -C50 --color
第一、执行top命令,结果如下

我们根据top结果发现,有java进程CPU占用超过100%,说明这个进程中的代码出现问题了
第二、执行top -Hp 2848 查看该pid详情

从上面结果,我们基本可以排除产生大对象的情况,因为如果有大对象产生,这个时候的结果应该是有多个进程CPU占用都会超过80%,其中有多个进程在在进行GC,从而造成CPU飙升。
第三 执行 printf "%x" 2925 转换为 十六进制

第四 执行 jstack 2848 | grep 0xb6d -C50 --color 查看具体的信息,由于我们项目使用daemon用户启动,所以我执行的命令为
/sbin/runuser -s /bin/bash daemon -c "jstack 2848 | grep 0xb6d -C50 --color"

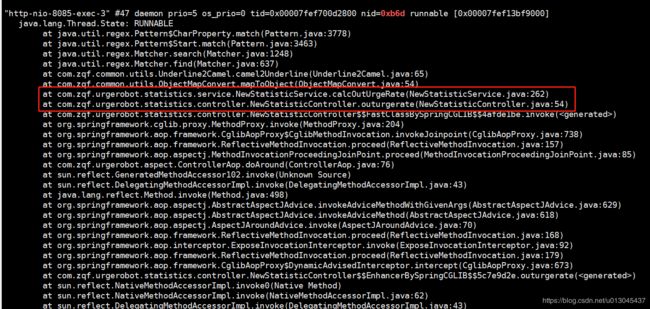
上图中红色的nid就是我们查看的进行对应的详细代码信息,从上面我们就可以很快的定位到具体的代码行,我们系统此处代码是一个统计的方法,由于前端传递的时间跨度非常大,并且多个人在频繁的刷新造成系统卡死。
注意:我们执行jstack的时候,执行用户需要和进程启动用户一直,否则会提示下面错误
Unable to open socket file: target process not responding or HotSpot VM not loaded
The -F option can be used when the target process is not responding
********************下面我们分析一下 代码执行过程中产生 "超大对象" 出现的现象***************************************
1、top
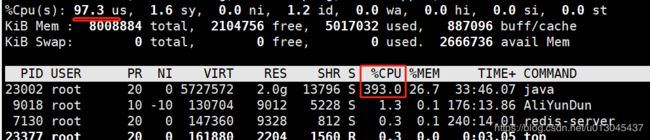
2、 执行命令 top -Hp 23002

我们发现有很多的进程cpu占用都查过了90%,这种情况很可能是多个进程在进行FGC,为了验证这种情况我们执行下面命令
3、jstat -gcutil 23002 2000 5
上面命令是 输出该进程在jvm中的占用情况 每2000毫秒执行一次 一共执行5次

从输出信息可以看出,Eden区内存占用100%,Old区内存占用99.97%,Full GC的次数高达170次,并且频繁Full GC,Full GC的持续时间也特别长,平均每次Full GC耗时5.93秒(1009.445/170)。根据这些信息,基本可以确定是程序代码上出现了问题,可能存在不合理创建对象的地方
4、将上面的对应的四个线程号十进制转换为 十六进制
5、执行命令 jstack 23002 |grep "0x59dd" -C50 --color 查看对应的线程信息
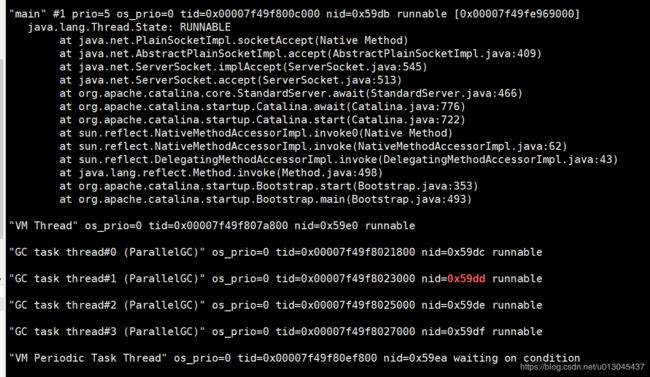
由上图可见,cpu使用率高的线程都在GC task,JVM的GC线程一直在占用大量CPU
6、也可以执行命令jstack -l 23002 >/data1/23002.statck 将对应的进程号的栈信息输入到指定目录
7、在23002.statck中就行过滤查询
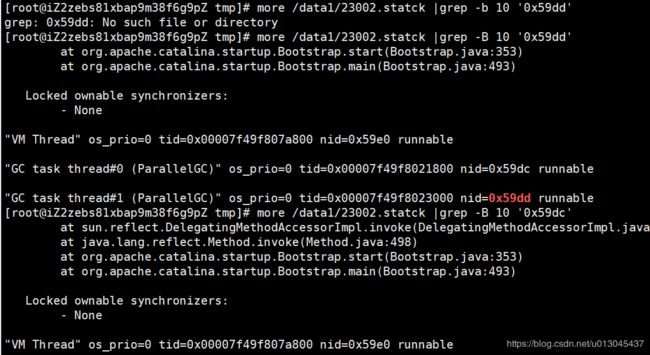
7、过滤搜索一下 我们项目名称,就可以看到具体的代码位置

8、然后根据具体的代码分析一下,出现 问题的具体原因
小结
线上出现cpu100%问题需要我们在最短的是时间内解决该问题,其中最重要的是我们能快速的定位到问题出现的具体代码位置,然后我们才能在最短的时间内解决,对于一些不是很重要的统计功能,我们可以先暂停该功能,首先保证主要流程正常使用,待服务恢复正常以后,我们在 优化具体的代码。