ZooKeeper的系统模型(数据模型、节点特性、版本、Watcher、ACL)
一、数据模型
ZooKeeper的视图结构和标准的Unix文件系统非常类似,但没有引入传统文件系统中目录和文件等相关概念,而是使用了其特有的“数据节点”概念,我们称之为ZNode.ZNode是ZooKeeper中数据的最小单元,每个ZNode上都可以保存数据,同时还可以挂载子节点,因此构成了一个层次化的命名空间,我们称之为树。
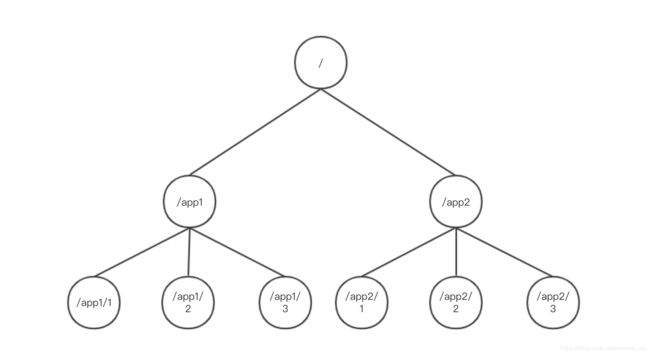
1.1 树
ZooKeeper中,每- -个数据节点都被称为-一个ZNode,所有ZNode按层次化结构进行组织,形成- - 棵树。ZNode 的节点路径标识方式和Unix文件系统路径非常相似,都是由一系列使用斜杠(/) 进行分割的路径表示,开发人员可以向这个节点中写入数据,也可以在节点下面创建子节点。如图。
1.2 事务ID(ZXID)
1.2.1 什么是事务
事务是对物理和抽象的应用状态上的操作集合。在现在的计算机科学中,狭义上的事务通常指的是数据库事务,一 般包含了一系列
对数据库有序的读写操作,这些数据库事务具有所谓的ACID特性,即原子性(Atomic)、一致性(Consistency)、隔离性(Isolation) 和持久性(Durability)。
1.2.2 ZooKeeper中的事务
在ZooKeeper中,事务是指能够改变ZooKeeper服务器状态的操作,我们也称之为事务操作或更新操作,一般包括数据节点创建与删除、数据节点内容更新和客户端会话创建与失效等操作。对于每一个事务请求,ZooKeeper都会为其分配一个全局唯一的事务 ID,用ZXID来表示,通常是一个64位的数字。每一个ZXID对应一次更新操作,从这些ZXID中可以间接地识别出ZooKeeper处理这些更新操作请求的全局顺序。
二、节点特性
2.1 节点类型
在ZooKeeper中,每个数据节点都是有生命周期的,其生命周期的长短取决于数据节点的节点类型。在ZooKeeper中,**节点类型可以分为持久节点(PERSISTENT)、临时节点(EPHEMERAL)、顺序节点(SEQUENTIAL)**三大类,具体在节点创建过程中,通过组合使用,可以生成以下四种组合型节点类型:
2.1.1 持久节点(PERSISTENT)
持久节点是ZooKeeper中最常见的一种节点类型。所谓持久节点,是指该数据节点被创建后,就会一直存在于ZooKeeper服务器上,直到有删除操作来主动清除这个节点。
2.1.2 持久顺序节点(PERSISTENT_ SEQUENTIAL)
持久顺序节点的基本特性和持久节点是-致的,额外的特性表现在顺序性上。在ZooKeeper中,每个父节点都会为它的第一级子节点维护一份顺序,用于记录下每个子节点创建的先后顺序。基于这个顺序特性,在创建子节点的时候,可以设置这个标记,那么在创建节点过程中,ZooKeeper 会自动为给定节点名加上一个数字后缀,作为一个新的、完整的节点名。另外需要注意的是,这个数字后缀的上限是整型的最大值。
2.1.3 临时节点(EPHEMERAL)
和持久节点不同的是,临时节点的生命周期和客户端的会话绑定在一起,也就是说,如果客户端会话失效,那么这个节点就会被自动清理掉。注意,这里提到的是客户端会话失效,而非TCP连接断开。另外,ZooKeeper规定了不能基于临时节点来创建子节点,即临时节点只能作为叶子节点。
2.1.4 临时顺序节点(EPHEMERAL_ SEQUENTIAL)
临时顺序节点的基本特性和临时节点也是一致的,同样是在临时节点的基础上,添加了顺序的特性。
2.2 状态信息
可以针对ZooKeeper上的数据节点进行数据的写人和子节点的创建。事实上,每个数据节点除了存储了数据内容之外,还存储了数据节点本身的一些状态信息。
[zk: localhost:2181(CONNECTED) 7] get /user
xiaoming
cZxid = 0x4
ctime = Sun Jan 26 18:36:52 CST 2020
mZxid = 0x4
mtime = Sun Jan 26 18:36:52 CST 2020
pZxid = 0x4
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 8
numChildren = 0
上面是我创建了一个zk的节点。关于zk的安装与使用,可以参考我的博客 Zookeeper的安装与基本使用
| 状态属性 | 说 明 |
|---|---|
| czxid | 即Created ZXID,表示该数据节点被创建时的事务ID |
| mzxid | Modified ZXID,表示该节点最后一次被更新时的事务ID |
| ctime | CreatedTime,表示节点被创建的时间 |
| mtime | Modified Time,表示该节点最后一次被更新的时间数据节点的版本号。 |
| cversion | 子节点的版本号 |
| aclVersion | 节点的ACL版本号 |
| dataVersion | 数据的版本号 |
| ephemeralOwner | 创建该临时节点的会话的sessionID。如果该节点是持久节点,那么这个属性值为0 |
| datalength | 数据内容的长度 |
| numChildren | 当前节点的子节点个数 |
| pzxid | 表示该节点的子节点列表最后一次被修改时的事务ID。注意,只有子节点列表变更了才会变更pzxid,子节点内容变更不会影响pzxid |
三、版本—保证分布式数据原子性操作
ZooKeeper中为数据节点引入了版本的概念,每个数据节点都具有三种类型的版本信息,对数据节点的任何更新操作都会引起版本号的变化。
Zookeeper中的版本
ZooKeeper中的版本概念和传统意义上的软件版本有很大的区别,它表示的是对数据节点的数据内容、子节点列表,或是节点ACL信息的修改次数,我们以其中的version这种版本类型为例来说明。在一个数据节点/zk-book被创建完毕之后,节点的version值是0,表示的含义是“当前节点自从创建之后,被更新过0次”。如果现在对该节点的数据内容进行更新操作,那么随后,version的值就会变成1。同时需要注意的是,在上文中提到的关于version的说明,其表示的是对数据节点数据内容的变更次数,强调的是变更次数,因此即使前后两次变更并没有使得数据内容的值发生变化,version
的值依然会变更。
和乐观锁的版本一样。
四、Watcher —数据变更的通知
4.1 Watcher的作用
ZooKeeper提供了分布式数据的发布/订阅功能。一个典型的发布/订阅模型系统定义了一种一对多的订阅关系,能够让多个订阅者同时监听某一个主题对象,当这个主题对象自身状态变化时,会通知所有订阅者,使它们能够做出相应的处理。在ZooKeeper中,引入了Watcher机制来实现这种分布式的通知功能。
ZooKeeper允许客户端向服务端注册一个Watcher监听,当服务端的一些指定事件触发了这个Watcher,那么就会向指定客户端发送一个事件通知来实现分布式的通知功能。
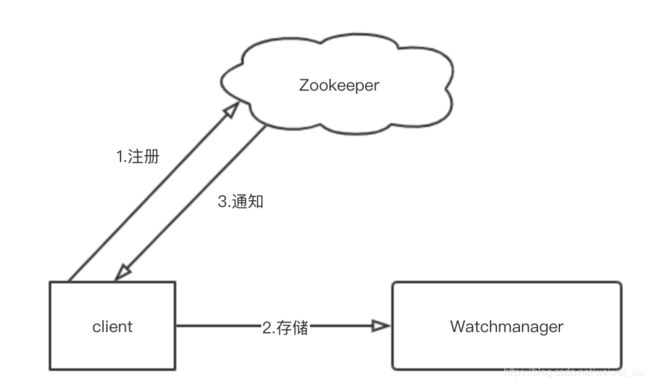
从上图中,可以看到,ZooKeeper 的Watcher 机制主要包括客户端线程、WatchManager和ZooKeeper服务器三部分。
4.2 Watcher工作流程
在具体工作流程上,简单地讲,客户端在向ZooKeeper服务器注册Watcher的同时,会将Watcher对象存储在客户端的
WatchManager中。当ZooKeeper服务器端触发Watcher事件后,会向客户端发送通知,客户端线程从WatchManager中取出对应的Watcher对象来执行回调逻辑。
4.3 Watcher的特性
4.3.1 一次性
无论是服务端还是客户端,一旦一个Watcher 被触发,ZooKeeper都会将其从相应的存储中移除。因此,开发人员在Watcher的使用上要记住的一点是需要反复注册。这样的设计有效地减轻了服务端的压力。试想,如果注册一个 Watcher之后一直有效,那么,针对那些更新非常频繁的节点,服务端会不断地向客户端发送事件通知,这无论对于网络还是服务端性能的影响都非常大。
4.3.2 客户端串行执行
客户端Watcher回调的过程是一个串行同步的过程,这为我们保证了顺序,同时需要开发人员注意的一点是,千万不要因为一个Watcher 的处理逻辑影响了整个客户端的Watcher回调。
4.3.3 轻量
WatchedEvent是ZooKeeper整个Watcher通知机制的最小通知单元,这个数据结构中只包含三部分内容:通知状态、事件类型和节点路径。也就是说,Watcher通知非常简单,只会告诉客户端发生了事件,而不会说明事件的具体内容。例如针对NodeDataChanged事件, ZooKeeper的Watcher只会通知客户端指定数据节点的数据内容发生了变更,而对于原始数据以及变更后的新数据都无法从这个事件中直接获取到,而是需要客户端主动重新去获取数据一这 也是ZooKeeper的Watcher机制的一个非常重要的特性。
另外,客户端向服务端注册Watcher的时候,并不会把客户端真实的Watcher对象传递到服务端,仅仅只是在客户端请求中使用boolean类型属性进行了标记,同时服务端也仅仅只是保存了当前连接的ServerCnxn对象。如此轻量的Watcher机制设计,在网络开销和服务端内存开销上都是非常廉价的。
五、ACL—保障数据的安全
ZooKeeper 作为一个分布式协调框架,其内部存储的都是一些关乎分布式系统运行时状态的元数据,尤其是一些涉及分布式锁、Master选举和分布式协调等应用场景的数据,会直接影响基于ZooKeeper进行构建的分布式系统的运行状态。因此,如何有效地保障ZooKeeper中数据的安全,从而避免因误操作而带来的数据随意变更导致的分布式系统异常就显得格外重要了。所幸的是,ZooKeeper提供了一套完善的ACL(Access Control List)权限控制机制来保障数据的安全。
5.1 UGO权限控制
提到权限控制,我们首先来看看大家都熟悉的、在Unix/Linux 文件系统中使用的,也是目前应用最广泛的权限控制方式一一UGO (User. Group 和Others)权限控制机制。简单地讲,UGO就是针对一个文件或目录,对创建者(User)、 创建者所在的组(Group)和其他用户(Other) 分别配置不同的权限。从这里可以看出,UGO其实是一种粗粒度的文件系统权限控制模式,利用UGO只能对三类用户进行权限控制,即文件的创建者、创建者所在的组以及其他所有用户,很显然,UGO无法解决下面这个场景:
用户U,创建了文件F,希望U所在的用户组G拥有对F读写和执行的权限,另一个用户组G2拥有读权限,而另外一个用户U3则没有任何权限。接下去我们来看另外一种典型的权限控制方式: ACL。ACL,即访问控制列表,是一种相对来说比较新颖且更细粒度的权限管理方式,可以针对任意用户和组进行细粒度的权限控制。目前绝大部分Unix系统都已经支持了ACL方式的权限控制,Linux 也从2.6版本的内核开始支持这个特性。
5.2 ACL介绍
ZooKeeper的ACL权限控制和Unix/Linux操作系统中的ACL有一些区别,可以从三个方面来理解ACL机制,分别是:权限模式(Scheme)、授权对象(ID)和权限(Permission),通常使用“scheme:id:permission” 来标识一个有效的ACL信息。
5.2.1 权限模式: Scheme
权限模式用来确定权限验证过程中使用的检验策略。在ZooKeeper中,开发人员使用最多的就是以下四种权限模式。
5.2.1.1 IP
IP模式通过IP地址粒度来进行权限控制,例如配置了“ip:192.168.0.110”, 即表示权限控制都是针对这个IP地址的。同时,IP模式也支持按照网段的方式进行配置,例如“ip: 192.168.0.1/24”表示针对192.168.0.*这个IP段进行权限控制。
5.2.1.2 Digest
Digest是最常用的权限控制模式,也更符合我们对于权限控制的认识,其以类似于“username:password"形式的权限标识来进行权限配置,便于区分不同应用来进行权限控制。
当我们通过“ username:password”形式配置了权限标识后,ZooKeeper 会对其先后进行两次编码处理,分别是SHA-1算法加密和BASE64 编码,其具体实现由
DigestAuthenticationProvider.generateDigest(String idPassword)函数进行封装。
5.2.1.3 World
World是一种最开放的权限控制模式,从其名字中也可以看出,事实上这种权限控制方式几乎没有任何作用,数据节点的访问权限对所有用户开放,即所有用户都可以在不进行任何权限校验的情况下操作ZooKeeper,上的数据。另外,World模式也可以看作是一种特殊的Digest模式,它只有一个权限标识,即“ world:anyone"。
5.2.1.4 Super
Super模式,顾名思义就是超级用户的意思,也是一种特殊的Digest模式。在Super模式下,超级用户可以对任意ZooKeeper上的数据节点进行任何操作。
5.2.2 授权对象: ID
授权对象指的是权限赋予的用户或一一个指定实体,例如IP地址或是机器等。在不同的权限模式下,授权对象是不同的。
各个权限模式和授权对象之间的对应关系
| 权限模式 | 授权对象 |
|---|---|
| ip | 通常是一个IP地址或是IP段,例如“192.168.0.110” 或“192.168.0.1/24” |
| Digest | 自定义,通常是“username:BASE64(SHA-1(username:password))”,例如‘ foo: kWN6aNSbjcKWPqjiV7cg0N24raU=" |
| World | 只有一个ID:“ anyone’ |
| Super | 与Digest 模式一致 |
5.2.3 权限: Permission
权限就是指那些通过权限检查后可以被允许执行的操作。在ZooKeeper中,所有对数据的操作权限分为以下五大类:
CREATE(C):数据节点的创建权限,允许授权对象在该数据节点下创建子节点。DELETE(D):子节点的删除权限,允许授权对象删除该数据节点的子节点。READ(R):数据节点的读取权限,允许授权对象访问该数据节点并读取其数据内容或子节点列表等。WRITE(W):数据节点的更新权限,允许授权对象对该数据节点进行更新操作。ADMIN (A):数据节点的管理权限,允许授权对象对该数据节点进行ACL相关的设置操作。
5.3 设置ACL的方法
通过zkCli脚本登录ZooKeeper服务器后,可以通过两种方式进行ACL的设置。
一种是在数据节点创建的同时进行ACL权限的设置,命令格式如下:
create [-s] [-e] path data acl
另一种方式则是使用setAcl命令单独对已经存在的数据节点进行ACL设置:
setAcl path acl