task2 EDA探索性数据分析

1、赛题数据
赛题以预测二手车的交易价格为任务,数据集报名后可见并可下载,该数据来自某交易平台的二手车交易记录,总数据量超过40w,包含31列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取15万条作为训练集,5万条作为测试集A,5万条作为测试集B,同时会对name、model、brand和regionCode等信息进行脱敏
2、评测标准
评价标准为MAE(Mean Absolute Error)。

MAE越小,说明模型预测得越准确。
赛事官网:
零基础入门数据挖掘 - 二手车交易价格预测
3、具体步骤
3.1、环境:pycharm + python3
3.2、读取数据
下面展示一些 内联代码片。
// An highlighted block
var foo = 'bar';
#读取数据并#切分数据
dataset = pd.read_csv(r'C:\python3\envs\pytorch\atest_torch\data\used_car_train_20200313.csv', sep=' ')
# print(dataset)
# print(dataset.columns.values)
X = dataset[['SaleID', 'name', 'regDate', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'power', 'kilometer',
'notRepairedDamage', 'regionCode', 'seller', 'offerType', 'creatDate', 'v_0', 'v_1', 'v_2',
'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13', 'v_14']]
Y = dataset['price']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
#需要注意:因为该csv文件数据是按一个空格隔开的,在读取时需要用sep=’ '来分割开来。
3.2.2查看各列数据类型
#查看各列数据类型
print([X[column].dtypes for column in X])
- 1
- 2
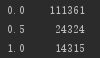
发现notRepairedDamage数据存在异常,该特征为汽车有尚未修复的损坏:是:0,否:1。
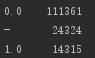
我将“-”进行缺失值处理,赋值为0.5
更新时间:2020年3月17日
3.3拆分数据集与测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.33, random_state=7)
- 1
3.4xgboost构建模型
