leetcode sql 刷题记录
176.查找第二高的薪水纪录
Write a SQL query to get the second highest salary from the Employee table.
±—±-------+
| Id | Salary |
±—±-------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
±—±-------+
输出例子
±--------------------+
| SecondHighestSalary |
±--------------------+
| 200 |
±--------------------+
select ifnull
((select salary from employee
group by salary
order by salary desc
limit 1 offset 1),null)
as SecondHighestSalaryifnull(,null)如果逗号前面是null就输出null,题目要求第二高为空输出null而不是空
177.提交第n高的薪水
CREATE FUNCTION getNthHighestSalary(N INT)
RETURNS INT
BEGIN
set N=N-1;
IF N < 0
THEN RETURN NULL;
else RETURN (
# Write your MySQL query statement below.
select ifnull( (select distinct salary
from employee order by salary desc
limit N,1),null) );
end if;
END难点就在于不能limit n-1,1,要提前set n=n-1,主义严谨的地方n是从0开始的,所以有if n<0,最后也不能忘了end if。然后记得每一个完整的语句后面加分号
178.排名
mysql8.0以上直接用窗口函数,非常方便
窗口函数参考.
select score,
dense_rank() over (order by score desc) as rank
from Scores s LeetCode不支持8.0以上版本,考虑复表,也就是自己写rank()
select s1.score,count(distinct s2.score) as 'rank'
from scores s1,scores s2
where s1.score<=s2.score
group by s1.id
order by score desc 一定要按照s1.id 分类,才能数出比我大的有几个,不知道为什么leetcode里按照rank order by输不出
今天好累,明天继续2020-05-03
180.输出至少连续出现三次以上的数字
Write a SQL query to find all numbers that appear at least three times consecutively.
±—±----+
| Id | Num |
±—±----+
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 2 |
| 7 | 2 |
±—±----+
前面要加distinct,因为可能会有多条记录,但是是同一数字
select distinct l1.num from
Logs l1,logs l2,logs l3
where l1.id+1=l2.id and l2.id+1=l3.id
and l1.num=l2.num and l2.num=l3.num181.收入超过经理的员工
The Employee table holds all employees including their managers. Every employee has an Id, and there is also a column for the manager Id.
±—±------±-------±----------+
| Id | Name | Salary | ManagerId |
±—±------±-------±----------+
| 1 | Joe | 70000 | 3 |
| 2 | Henry | 80000 | 4 |
| 3 | Sam | 60000 | NULL |
| 4 | Max | 90000 | NULL |
±—±------±-------±----------+
select e1.name as 'Employee'
from employee e1,employee e2
where e1.salary>e2.salary
and e2.id=e1.managerid183.从不订购的用户
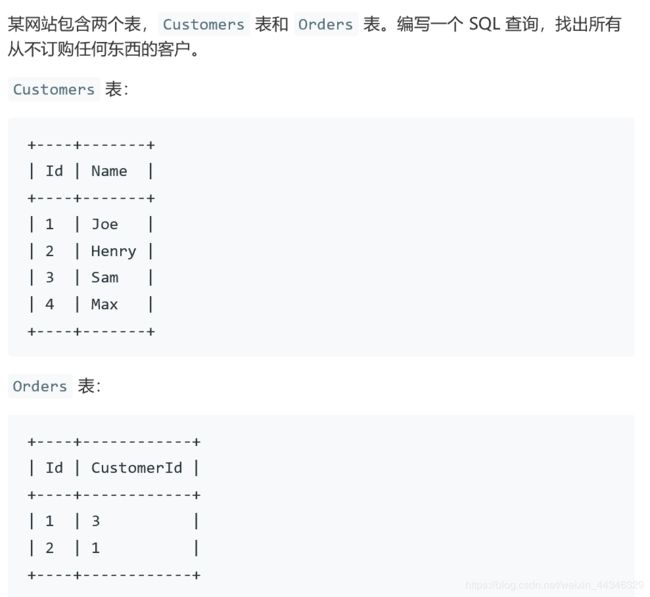
方法一:not in
select c.name as 'Customers' from Customers c
where C.Id not in
(select distinct o.customerId from Orders o)这个方法开始我没有在o.customerid前面加distinct,然后有一个数据是orders表为空,结果就应该输出c表里面所有人的名字,但是最后输出为空
方法二:利用左连接
select c.name as 'Customers'
from Customers C left join orders o
on c.id=o.Customerid
where o.customerid is null方法三:exists语句
select c.name as 'Customers'
from Customers C
where not exists
(select 1 from Orders o where o.CustomerId = c.id)184.部门工资最高的员工
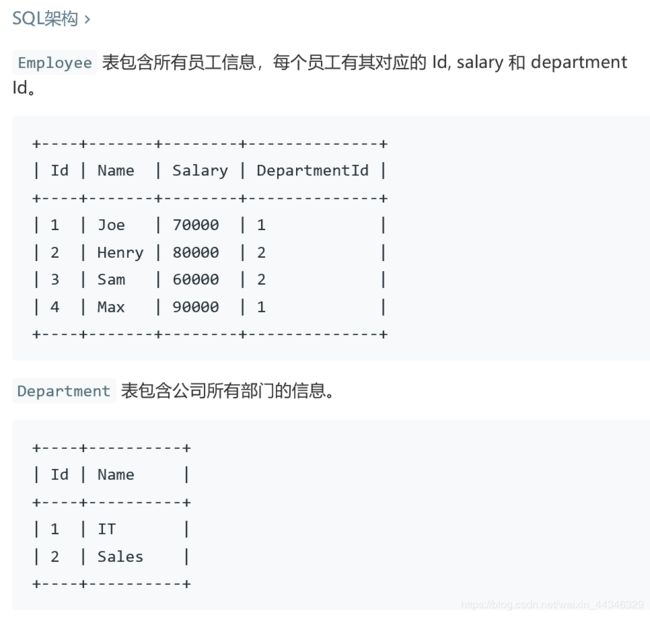
select d.name "Department",e.name "Employee",
m.s "Salary"
from Department d,employee e,
(select max(salary) s,DepartmentId
from employee e1 group by DepartmentId) m
where m.DepartmentId=d.id and
e.departmentid=m.DepartmentId and e.salary = m.s有点乱,评论里面用in 感觉更清晰
185.题目描述同上,找出每个部门工资前三的员工
思路:
首先按照部门分组,找出排名前三的员工,存到一个子表
再与department表连接,找到部门名称
排名前三的员工如果不用开窗函数,可以用复表,e1,e2,找出工资比我高的,having count(salary)<=2,不超过两个,肯定是前三
1)找出部门排名前三的员工信息
select e1.salary,e1.departmentId,e1.Id from employee e1,employee e2
where e1.salary<=e2.salary
and e1.departmentid=e2.departmentid
group by e1.id
having count(distinct e2.salary)<=3看一下用departmentid连接是什么效果
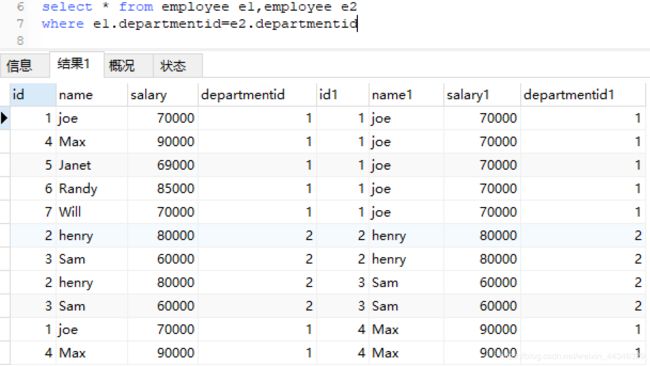
只要是一个部门的,都会比较一遍,可以达到想要的效果,前面做到过一题,只要找排名前三的员工,不按照部门分组,当时使用复表,没有用连接
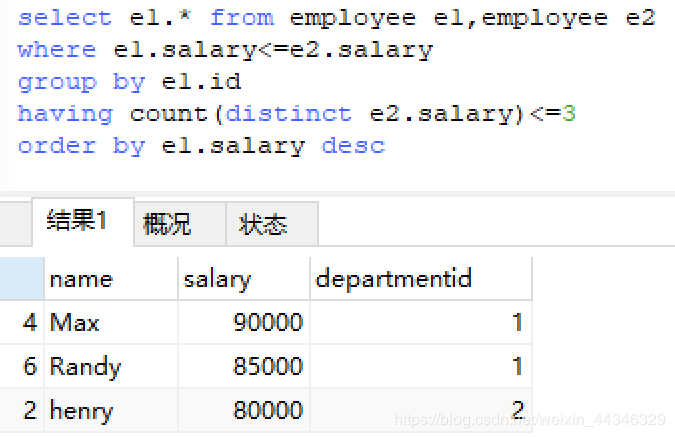
2)连接
select d.Name as "Department",t.Name as "Employee",t.salary as"Salary"from
(select e1.salary,e1.name,e1.departmentId,e1.Id
from employee e1,employee e2
where e1.salary<=e2.salary
and e1.departmentid=e2.departmentid
group by e1.id
having count(distinct e2.salary)<=3) t,department d
where t.departmentid = d.Id196.删除重复的邮箱
这道题的重点在于删除delete,我一直在那select 半天
delete p1 from person p1 inner join person p2
on p1.id>p2.id and p1.email=p2.email197.温度比昨天高的所有ID

要点:datediff(date1,date2)
我开始使用的date1-date2=1怎么都通不过,原理是正确的,但是这样消耗的内存太大
select w1.ID "Id"from weather w1,weather w2
where w2.temperature<w1.temperature
and datediff(w1.RecordDate,w2.RecordDate)=1
group by w1.RecordDate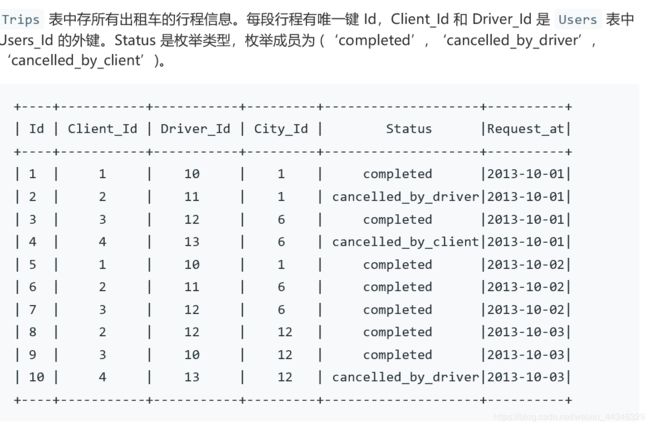
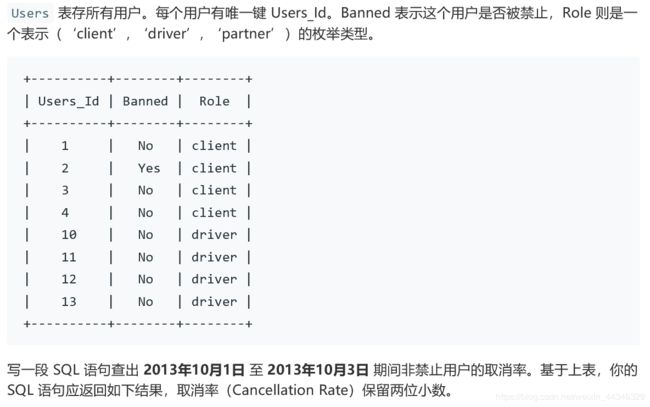
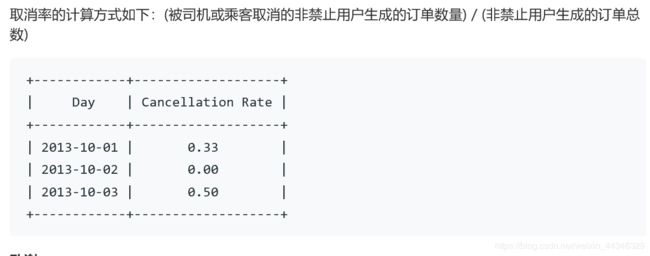
select request_at as 'day',
round(count(if(status!='completed',status,null))/count(status),2) as 'Cancellation Rate'
from trips t left join users u1on
t.client_id = u1.users_id
left join users u2
on t.driver_id = u2.users_id
where u1.Banned ='no' and u2.Banned='no'
and t.request_at>='2013-10-01' and t.request_at<='2013-10-03'
group by t.request_at学到了if(A,B,C)
如果A,则B,否则C
601.连续三条记录
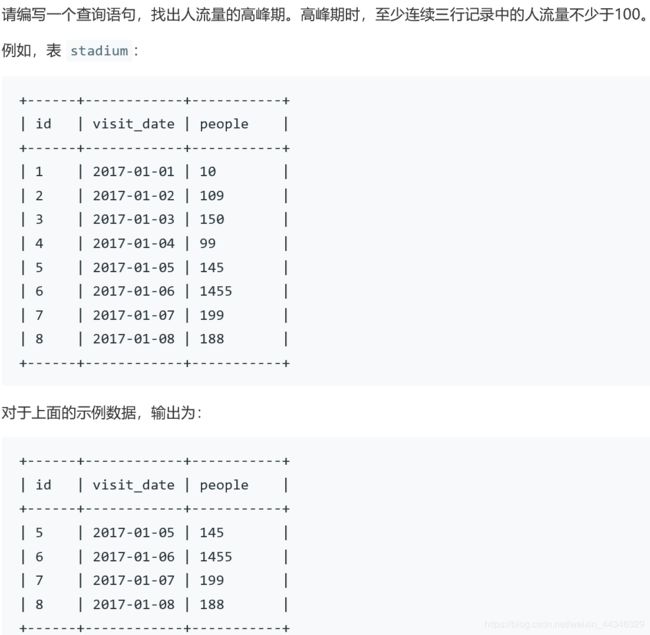
使用三张复表,筛选id连续,日期可能存在月份差等问题,评论中有两种处理筛选的问题
select s1.* from stadium s1,stadium s2,stadium s3
where s1.people>=100 and s2.people>=100 and s3.people>=100
and s1.id+1=s2.id and s2.id+1=s3.id
group by s1.id这是我一开始的写法,问题是只能输出最开始一天的记录,后面的两天怎么筛
select s4.* from
stadium s1,stadium s2,stadium s3 ,stadium s4
where s1.people>=100 and s2.people>=100 and s3.people>=100 and s1.id+1=s2.id and s2.id+1=s3.id
and s4.id in (s1.id,s2.id,s3.id)
group by s4.id再加一个表,s4.id为s1/s2/s3中的任意一个,对s4.id group by,否则会输出重复的记录
评论里还有一个方法,把中间的date分情况
select s1.* from stadium s1,stadium s2,stadium s3
where s1.people>=100 and s2.people>=100 and s3.people>=100
and ((s1.id+1=s2.id and s2.id+1=s3.id)
or (s1.id-1=s2.id and s1.id+1=s3.id)
or (s1.id-1=s2.id and s2.id-1=s3.id))
group by s1.id
order by s1.id626.交换相邻id学生座位

这题不会,看了评论解答,是我想不到的思路
方法1:
select a.id,ifnull(b.student,a.student) student
from seat a left join seat b on
if(a.id&1,a.id=b.id-1,a.id=b.id+1)
order by id使用复表,把b的id顺序交换再和a连接,筛选a的id,b的student名字
if(a.id&1,a.id=b.id-1,a.id=b.id+1)这一句交换相邻id,a.id&1的意思是判断是否是奇数,这个是用二进制计算的,有点复杂,就只有记住了。如果是奇数,就按照a.id=b.id-1进行连接,如果是偶数,按照a.id=b.id+1进行连接
这样的话,如果有奇数个id,最后一个id就会出现空,所以筛选的时候如果为空,就用a.student
ifnull(b.student,a.student)我只能说一句妙啊
方法二:直接调换id的顺序,再按照id排序
select (CASE
when id%2=1 and id=(select count(*) from seat) then id
when id%2=1 then id+1
else id-1
end) as id,student
from seat
order by id627.交换性别
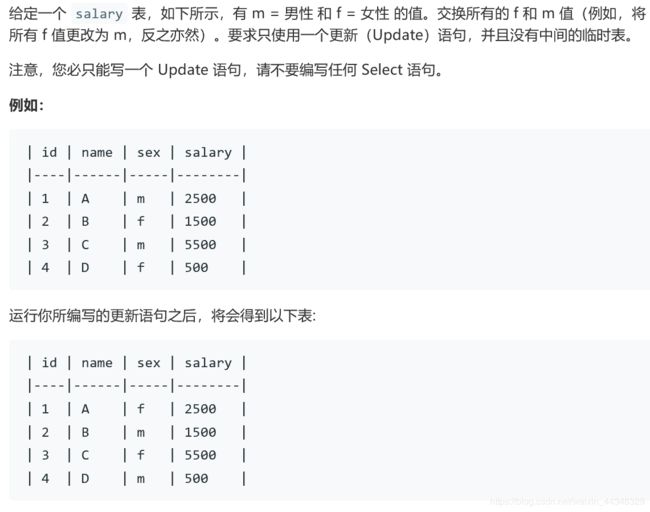 方法一:
方法一:
case when语句
update salary set sex=
(case when sex='m' then 'f'
when sex='f' then 'm'
end) 方法二:if语句
update salary set sex=if(sex='m','f','m')1179.类似行转列,重新格式化表格
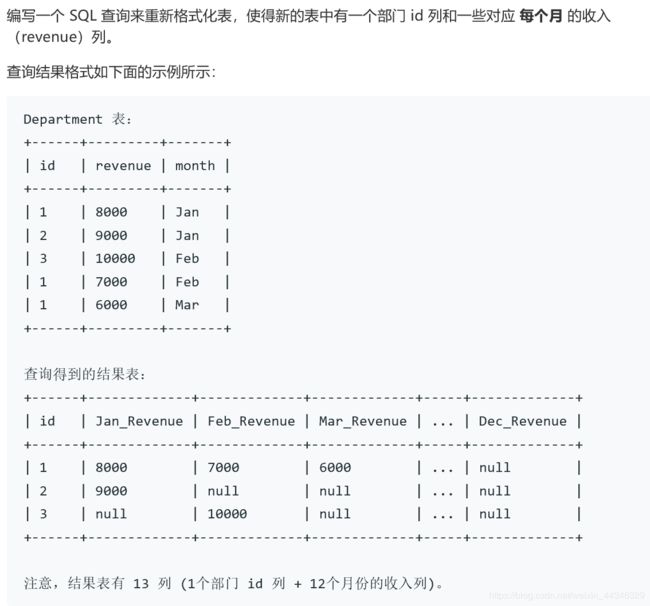
这和之前做的拼多多的行转列的题很像,要用到group by聚合函数,我开始没有使用sum,就只有里面的if语句,对于group by之后它只会默认返回第一条查到的记录
select id,sum(if(month='Jan',revenue,null))Jan_Revenue,
sum(if(month='Feb',revenue,null))Feb_Revenue,
sum(if(month='Mar',revenue,null))Mar_Revenue,
sum(if(month='Apr',revenue,null))Apr_Revenue,
sum(if(month='May',revenue,null)) May_Revenue,
sum(if(month='Jun',revenue,null))Jun_Revenue,
sum(if(month='Jul',revenue,null))Jul_Revenue,
sum(if(month='Aug',revenue,null)) Aug_Revenue,
sum(if(month='Sep',revenue,null)) Sep_Revenue,
sum(if(month='Oct',revenue,null)) Oct_Revenue,
sum(if(month='Nov',revenue,null)) Nov_Revenue,
sum(if(month='Dec',revenue,null)) Dec_Revenue
from department group by id