HAWQ + MADlib 玩转数据挖掘之(一)——安装
一、MADlib简介
MADlib是Pivotal公司与伯克利大学合作的一个开源机器学习库,提供了精确的数据并行实现、统计和机器学习方法对结构化和非结构化数据进行分析,主要目的是扩展数据库的分析能力,可以非常方便的加载到数据库中, 扩展数据库的分析功能,2015年7月MADlib成为Apache软件基金会的孵化项目,其最新版本为MADlib1.11,可以用在Greenplum、PostgreSQL和HAWQ等数据库系统中。官网地址:http://madlib.incubator.apache.org/。1. 设计思想
驱动MADlib架构的主要思想与Hadoop是一致的,主要体现在以下方面:- 操作数据库内的本地数据,不在多个运行时环境中进行不必要的数据移动。
- 充分利用数据库引擎的功能,但将机器学习逻辑从特定数据库的实现细节中分离出来。
- 利用MPP无共享技术提供的并行性和可扩展性,如Greenplum数据库和HAWQ。
- 执行的维护活动对Apache社区和正在进行的学术研究开放。
2. 特性
(1)分类如果所需的输出实质上是分类的,可以使用分类方法建立模型,预测新数据会属于哪一类。分类的目标是能够将输入记录标记为正确的类别。
分类的例子:假设有描述人口统计的数据,以及个人申请贷款和贷款违约历史数据,那么我们就能建立一个模型,描述新的人口统计数据集合贷款违约的可能性。此场景下输出的分类为“违约”和“正常”两类。
(2)回归
如果所需的输出具有连续性,我们使用回归方法建立模型,预测输出值。
回归的例子:如果有真实的描述房地产属性的数据,我们就可以建立一个模型,预测基于房屋已知特征的售价。因为输出反应了连续的数值而不是分类,所以该场景是一个回归问题。
(3)聚类
识别数据分组,一组中的数据项比其它组的数据项更相似。
聚类的例子:在客户细分分析中,目标是识别客户行为相似特征组,以便针对不同特征的客户设计各种营销活动,以达到市场目的。如果提前了解客户细分情况,这将是一个受控的分类任务。当我们让数据识别自身分组时,这就是一个聚类任务。
(4)主题建模
主题建模与聚类相似,也是确定彼此相似的数据组。但这里的相似通常特指在文本领域中,具有相同主题的文档。
(5)关联规则挖掘
又叫做购物篮分析或频繁项集挖掘。相对于随机发生,确定哪些事项更经常一起发生,指出事项之间的潜在关系。
关联规则挖掘的例子:在一个网店应用中,关联规则挖掘可用于确定哪些商品倾向于被一起售出。然后将这些商品输入到客户推荐引擎中,提供促销机会,如著名的啤酒与尿布的故事。
(6)描述性统计
描述性统计不提供模型,因此不被认为是一种机器学习方法。但描述性统计有助于向分析人员提供信息以了解基础数据,为数据提供有价值的解释,可能影响数据模型的选择。
描述性统计的例子:计算数据集中每个变量内的数据分布,可以帮助分析式理解哪些变量应被视为分类变量,哪些变量是连续性变量,以及值的分布情况。
(7)模型验证
如果不了解一个模型的准确性就开始使用它,会导致糟糕的结果。正因如此,理解模型存在的问题,并用测试数据评估模型的精度显得尤为重要。需要将训练数据和测试数据分离,频繁进行数据分析,验证统计模型的有效性,评估模型不过分拟合训练数据。N-fold交叉验证也经常被使用。
3. 功能
MADlib的功能特色如图1所示。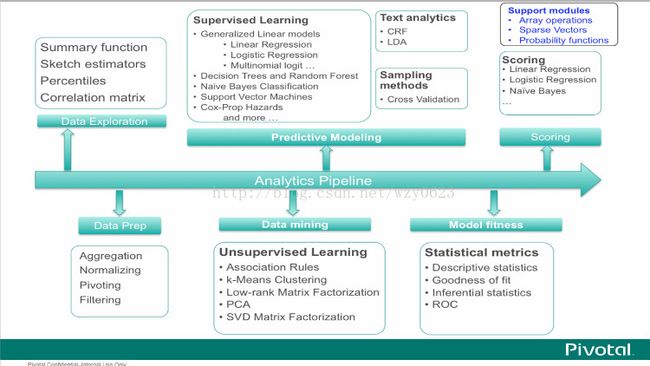
图1
• Data Types and Transformations(数据类型转换)
Arrays and Matrices(数组与矩阵)
o Array Operations(数组运算)
o Matrix Operations(矩阵运算)
o Matrix Factorization(低矩阵分解)
o Low-rank Matrix Factorization(低阶矩阵分解)
o Singular Value Decomposition(SVD,奇异值分解)
o Norms and Distance functions(规范和距离函数)
o Sparse Vectors(稀疏向量)
Dimensionality Reduction(降维)
o Principal Component Analysis(PCA主成分分析)
o Principal Component Projection(PCP主成分投影)
Encoding Categorical Variables(编码分类变量)
Stemming(切词)
• Model Evaluation(模型评估)
Cross Validation(交叉验证)
• Statistics(统计)
Descriptive Statistics(描述性统计)
o Pearson’s Correlation(皮尔斯相关性)
o Summary(摘要汇总)
Inferential Statistics(推断性统计)
o Hypothesis Tests(假设检验)
Probability Functions(概率函数)
• Supervised Learning(监督学习算法)
Conditional Random Field(条件随机场)
Regression Models(回归模型)
o Clustered Variance(聚类方差)
o Cox-Proportional Hazards Regression(Cox比率风险回归模型)
o Elastic Net Regularization(Elastic Net 回归)
o Generalized Linear Models
o Linear Regression(线性回归)
o Logistic Regression(逻辑回归)
o Marginal Effects(边际效应)
o Multinomial Regression(多项式回归)
o Ordinal Regression(有序回归)
o Robust Variance(鲁棒方差)
Support Vector Machines(SVM,支持向量机)
Tree Methods(树模型)
o Decision Tree(决策树)
o Random Forest(随机森林)
• Time Series Analysis(时间序列分析)
ARIMA(自回归积分滑动平均模型)
• Unsupervised Learning(无监督学习)
Association Rules(关联规则)
o Apriori Algorithm(Apriori算法)
Clustering(聚类)
o k-Means Clustering(k-Means)
Topic Modelling(主题模型)
o Latent Dirichlet Allocation(LDA)
• Utility Functions(效用函数)
Developer Database Functions(开发者数据库函数)
Linear Solvers(线性求解器)
o Dense Linear Systems(稠密线性系统)
o Sparse Linear Systems(稀疏线性系统)
Path Functions(路径函数)
PMML Export(PMML输出)
Text Analysis(文本分析)
o Term Frequency(词频,TF)
二、安装
1. 确定安装平台
MADlib最新发布版本是1.11,可以安装在PostgreSQL、Greenplum和HAWQ中,在不同的数据库中安装过程也不尽相同。我是安装在HAWQ2.1.1.0中。2. 下载MADlib二进制安装压缩包
下载地址为: https://network.pivotal.io/products/pivotal-hdb。2.1.1.0版本的HAWQ提供了四个安装文件,如图2所示。经过测试,只有MADlib 1.10.0版本的文件可以正常安装。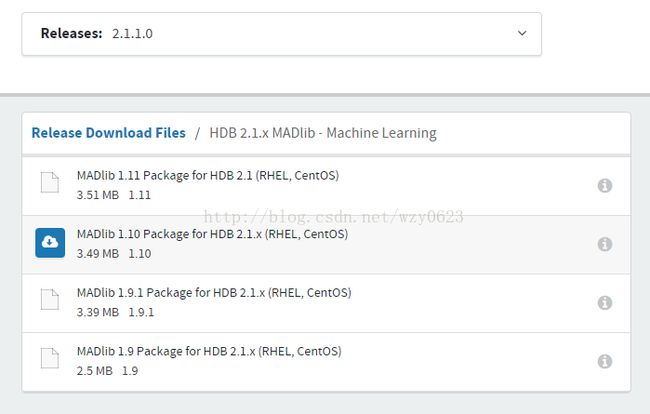
图2
3. 安装MADlib
以下命令需要使用gpadmin用户,在HAWQ的master主机上执行。(1)解压缩
tar -zxvf madlib-ossv1.10.0_pv1.9.7_hawq2.1-rhel5-x86_64.tar.gzgppkg -i madlib-ossv1.10.0_pv1.9.7_hawq2.1-rhel5-x86_64.gppkg(3)在指定数据库中部署MADlib
$GPHOME/madlib/bin/madpack install -c /dm -s madlib -p hawqdm=# set search_path=madlib;
SET
dm=# \dt
List of relations
Schema | Name | Type | Owner | Storage
--------+------------------+-------+---------+-------------
madlib | migrationhistory | table | gpadmin | append only
(1 row)
dm=# \ds
List of relations
Schema | Name | Type | Owner | Storage
--------+-------------------------+----------+---------+---------
madlib | migrationhistory_id_seq | sequence | gpadmin | heap
(1 row)
dm=# select type,count(*)
dm-# from (select p.proname as name,
dm(# case when p.proisagg then 'agg'
dm(# when p.prorettype = 'pg_catalog.trigger'::pg_catalog.regtype then 'trigger'
dm(# else 'normal'
dm(# end as type
dm(# from pg_catalog.pg_proc p, pg_catalog.pg_namespace n
dm(# where n.oid = p.pronamespace and n.nspname='madlib') t
dm-# group by rollup (type);
type | count
--------+-------
agg | 135
normal | 1324
| 1459
(3 rows)(4)验证安装
$GPHOME/madlib/bin/madpack install-check -c /dm -s madlib -p hawq[gpadmin@hdp3 Madlib]$ $GPHOME/madlib/bin/madpack install-check -c /dm -s madlib -p hawq
madpack.py : INFO : Detected HAWQ version 2.1.
TEST CASE RESULT|Module: array_ops|array_ops.sql_in|PASS|Time: 1851 milliseconds
TEST CASE RESULT|Module: bayes|gaussian_naive_bayes.sql_in|PASS|Time: 24222 milliseconds
TEST CASE RESULT|Module: bayes|bayes.sql_in|PASS|Time: 70634 milliseconds
TEST CASE RESULT|Module: crf|crf_train_small.sql_in|PASS|Time: 27186 milliseconds
TEST CASE RESULT|Module: crf|crf_train_large.sql_in|PASS|Time: 32602 milliseconds
TEST CASE RESULT|Module: crf|crf_test_small.sql_in|PASS|Time: 22410 milliseconds
TEST CASE RESULT|Module: crf|crf_test_large.sql_in|PASS|Time: 21711 milliseconds
TEST CASE RESULT|Module: elastic_net|elastic_net_install_check.sql_in|PASS|Time: 931563 milliseconds
TEST CASE RESULT|Module: graph|sssp.sql_in|PASS|Time: 18174 milliseconds
TEST CASE RESULT|Module: linalg|svd.sql_in|PASS|Time: 72105 milliseconds
TEST CASE RESULT|Module: linalg|matrix_ops.sql_in|PASS|Time: 58312 milliseconds
TEST CASE RESULT|Module: linalg|linalg.sql_in|PASS|Time: 2836 milliseconds
TEST CASE RESULT|Module: pmml|table_to_pmml.sql_in|PASS|Time: 34508 milliseconds
TEST CASE RESULT|Module: pmml|pmml_rf.sql_in|PASS|Time: 35993 milliseconds
TEST CASE RESULT|Module: pmml|pmml_ordinal.sql_in|PASS|Time: 15540 milliseconds
TEST CASE RESULT|Module: pmml|pmml_multinom.sql_in|PASS|Time: 12546 milliseconds
TEST CASE RESULT|Module: pmml|pmml_glm_poisson.sql_in|PASS|Time: 7321 milliseconds
TEST CASE RESULT|Module: pmml|pmml_glm_normal.sql_in|PASS|Time: 8597 milliseconds
TEST CASE RESULT|Module: pmml|pmml_glm_ig.sql_in|PASS|Time: 8861 milliseconds
TEST CASE RESULT|Module: pmml|pmml_glm_gamma.sql_in|PASS|Time: 26212 milliseconds
TEST CASE RESULT|Module: pmml|pmml_glm_binomial.sql_in|PASS|Time: 12977 milliseconds
TEST CASE RESULT|Module: pmml|pmml_dt.sql_in|PASS|Time: 9401 milliseconds
TEST CASE RESULT|Module: prob|prob.sql_in|PASS|Time: 1917 milliseconds
TEST CASE RESULT|Module: sketch|support.sql_in|PASS|Time: 143 milliseconds
TEST CASE RESULT|Module: sketch|mfv.sql_in|PASS|Time: 720 milliseconds
TEST CASE RESULT|Module: sketch|fm.sql_in|PASS|Time: 7301 milliseconds
TEST CASE RESULT|Module: sketch|cm.sql_in|PASS|Time: 19777 milliseconds
TEST CASE RESULT|Module: svm|svm.sql_in|PASS|Time: 205677 milliseconds
TEST CASE RESULT|Module: tsa|arima_train.sql_in|PASS|Time: 75680 milliseconds
TEST CASE RESULT|Module: tsa|arima.sql_in|PASS|Time: 76236 milliseconds
TEST CASE RESULT|Module: conjugate_gradient|conj_grad.sql_in|PASS|Time: 6757 milliseconds
TEST CASE RESULT|Module: knn|knn.sql_in|PASS|Time: 9835 milliseconds
TEST CASE RESULT|Module: lda|lda.sql_in|PASS|Time: 20510 milliseconds
TEST CASE RESULT|Module: stats|wsr_test.sql_in|PASS|Time: 2766 milliseconds
TEST CASE RESULT|Module: stats|t_test.sql_in|PASS|Time: 3686 milliseconds
TEST CASE RESULT|Module: stats|robust_and_clustered_variance_coxph.sql_in|PASS|Time: 17499 milliseconds
TEST CASE RESULT|Module: stats|pred_metrics.sql_in|PASS|Time: 14032 milliseconds
TEST CASE RESULT|Module: stats|mw_test.sql_in|PASS|Time: 1852 milliseconds
TEST CASE RESULT|Module: stats|ks_test.sql_in|PASS|Time: 2465 milliseconds
TEST CASE RESULT|Module: stats|f_test.sql_in|PASS|Time: 2358 milliseconds
TEST CASE RESULT|Module: stats|cox_prop_hazards.sql_in|PASS|Time: 39932 milliseconds
TEST CASE RESULT|Module: stats|correlation.sql_in|PASS|Time: 10520 milliseconds
TEST CASE RESULT|Module: stats|chi2_test.sql_in|PASS|Time: 3581 milliseconds
TEST CASE RESULT|Module: stats|anova_test.sql_in|PASS|Time: 1801 milliseconds
TEST CASE RESULT|Module: svec_util|svec_test.sql_in|PASS|Time: 14043 milliseconds
TEST CASE RESULT|Module: svec_util|gp_sfv_sort_order.sql_in|PASS|Time: 3399 milliseconds
TEST CASE RESULT|Module: utilities|text_utilities.sql_in|PASS|Time: 6579 milliseconds
TEST CASE RESULT|Module: utilities|sessionize.sql_in|PASS|Time: 3901 milliseconds
TEST CASE RESULT|Module: utilities|pivot.sql_in|PASS|Time: 15634 milliseconds
TEST CASE RESULT|Module: utilities|path.sql_in|PASS|Time: 9321 milliseconds
TEST CASE RESULT|Module: utilities|encode_categorical.sql_in|PASS|Time: 7665 milliseconds
TEST CASE RESULT|Module: utilities|drop_madlib_temp.sql_in|PASS|Time: 153 milliseconds
TEST CASE RESULT|Module: assoc_rules|assoc_rules.sql_in|PASS|Time: 31975 milliseconds
TEST CASE RESULT|Module: convex|lmf.sql_in|PASS|Time: 66775 milliseconds
TEST CASE RESULT|Module: glm|poisson.sql_in|PASS|Time: 19117 milliseconds
TEST CASE RESULT|Module: glm|ordinal.sql_in|PASS|Time: 23446 milliseconds
TEST CASE RESULT|Module: glm|multinom.sql_in|PASS|Time: 18780 milliseconds
TEST CASE RESULT|Module: glm|inverse_gaussian.sql_in|PASS|Time: 20931 milliseconds
TEST CASE RESULT|Module: glm|gaussian.sql_in|PASS|Time: 23795 milliseconds
TEST CASE RESULT|Module: glm|gamma.sql_in|PASS|Time: 43365 milliseconds
TEST CASE RESULT|Module: glm|binomial.sql_in|PASS|Time: 39437 milliseconds
TEST CASE RESULT|Module: linear_systems|sparse_linear_sytems.sql_in|PASS|Time: 5405 milliseconds
TEST CASE RESULT|Module: linear_systems|dense_linear_sytems.sql_in|PASS|Time: 3331 milliseconds
TEST CASE RESULT|Module: recursive_partitioning|random_forest.sql_in|PASS|Time: 294832 milliseconds
TEST CASE RESULT|Module: recursive_partitioning|decision_tree.sql_in|PASS|Time: 91311 milliseconds
TEST CASE RESULT|Module: regress|robust.sql_in|PASS|Time: 55325 milliseconds
TEST CASE RESULT|Module: regress|multilogistic.sql_in|PASS|Time: 25330 milliseconds
TEST CASE RESULT|Module: regress|marginal.sql_in|PASS|Time: 73750 milliseconds
TEST CASE RESULT|Module: regress|logistic.sql_in|PASS|Time: 76501 milliseconds
TEST CASE RESULT|Module: regress|linear.sql_in|PASS|Time: 7517 milliseconds
TEST CASE RESULT|Module: regress|clustered.sql_in|PASS|Time: 40661 milliseconds
TEST CASE RESULT|Module: sample|sample.sql_in|PASS|Time: 890 milliseconds
TEST CASE RESULT|Module: summary|summary.sql_in|PASS|Time: 14644 milliseconds
TEST CASE RESULT|Module: kmeans|kmeans.sql_in|PASS|Time: 52173 milliseconds
TEST CASE RESULT|Module: pca|pca_project.sql_in|PASS|Time: 229016 milliseconds
TEST CASE RESULT|Module: pca|pca.sql_in|PASS|Time: 523230 milliseconds
TEST CASE RESULT|Module: validation|cross_validation.sql_in|PASS|Time: 33685 milliseconds
[gpadmin@hdp3 Madlib]$三、卸载
卸载过程基本上是安装的逆过程。1. 删除madlib模式
方法1,使用madpack部署应用程序。$GPHOME/madlib/bin/madpack uninstall -c /dm -s madlib -p hawqdrop schema madlib cascade;2. 删除其它遗留数据库对象
(1)删除模式如果测试中途出错,数据库中可能包含测试的模式,这些模式名称的前缀都是madlib_installcheck_,只能手工执行SQL命令删除这些模式,如:
drop schema madlib_installcheck_kmeans cascade;如果存在遗留的测试用户,则删除它。
drop user if exists madlib_1100_installcheck;3. 删除MADlib rpm包
(1)查询包名gppkg -q --all[gpadmin@hdp3 Madlib]$ gppkg -q --all
20170630:16:19:53:076493 gppkg:hdp3:gpadmin-[INFO]:-Starting gppkg with args: -q --all
madlib-ossv1.10.0_pv1.9.7_hawq2.1gppkg -r madlib-ossv1.10.0_pv1.9.7_hawq2.1参考:
MADlib官网数据库数据分析扩展—MADlib
MADlib
一张图看懂MADlib能干什么
Apache MADlib Installation Guide
How to install or uninstall MADlib