软考-计算机组成原理与体系结构
目录
- 计算机组成原理与体系结构
- 一、计算机组成原理与体系结构前言
- 二、数据的表示(进制的转换)
- 1、任何进制的数转换为十进制
- 2、十进制转换任何进制数
- 3、二进制转八进制与十六进制
- 八进制与十六进制相互转换
- 三、数据的表示(源码、反码、补码、移码
- 1、原码
- 2、反码
- 3、补码
- 4、移码
- 5、数值的表示范围
- 四、数值的表示(浮点数运算)
- 1、浮点数的表示
- 2、计算方式
- 五、CPU结构(运算器与控制器的组成)
- 1、运算器
- 2、控制器
- 六、Flynn分类法简介
- 七、CISC和RISC
- 1、CISC(复杂指令集计算机)
- 2、RISC(精简指令集计算机)
- 流水机
- 1、流水线的基本概念
- 2、流水线周期及流水线执行时间计算(考试常考)
- 3、流水线吞吐率的计算
- 4、流水线加速比计算
- 5、流水线的效率
- 九、计算机层次存储结构
- Cache 的基本概念
- 1、Cache的功能
- 2、Cache的定位
- 3、Cache改善系统性能的依据
- 4、求使用“Cache+主存储器”的系统的平均周期时间
- 十一、时间局部性与空间局部性
- 1、局部性原理
- 2、时间局部性
- 3、空间局部性
- 十二、随机存储器与只读存储器
- 1、主存的分类
- 2、主存编址
- 十三、磁盘工作原理
- 十四、计算机总线
- 1、内部总线
- 2、系统总线
- 外部总线
- 十五、串联系统与并联系统可靠度的计算
- 1、串联系统
- 2、并联系统
- 3、模冗余系统(几乎不会考到)
- 4、混合系统(常考)
- 十六、校验码的概念
- 1、什么是检错和纠错
- 2、什么是码距
- 十七、循环校验码(CRC)
- 1、模2除法
- 2、CRC编码
- 十八、奇偶校验码
- 1、基本概念
- 2、应用举例
- 3、检错能力
- 4、奇校验还是偶校验
- 十九、海明校验码(难点考察频率高)
- 1、基本概念
- 2、 海明码的校验位数
- 3、校验码的位置
- 4、计算校验码的值
- 5、海明码的校验
转载: https://blog.csdn.net/Thanlon/article/details/100074645
计算机组成原理与体系结构
一、计算机组成原理与体系结构前言
内容概要:数据的表示、计算机结构、Flynn分类法、CISI与RISC、流水线技术、存储系统、总线系统、可靠性、校验码。
二、数据的表示(进制的转换)
1、任何进制的数转换为十进制
R(任何)进制转换成十进制使用按权展开法,其具体操作方式为:将R进制数的每一位数值用RK的方式表示,幂的底数是R,指数是K,K与该位置和小数点的距离有关。
当该位位于小数点左边,K值是该位和小数点之间数码的个数。
当该位位于小数点右边,K值为负值,其绝对值是该位和小数点之间数码的个数加1
二进制转十进制:101010.1010 = 1X25+1X23+1X21+1X2-1+1X2-3
七进制转十进制:123456 = 1X75+2X74+3X73+4X72+5X71+6X70
八进制转十进制:1234567 = 1X86+2X85+3X84+4X83+5X82+6X81+7X80
十六进制转十进制:123456789ABCDEF = 1X1614+2X1613+3X1612+4X1611+5X1610+6X169+7X168+8X167+9X166+10X165+11X164+12X163+13X162+14X161+15X160
2、十进制转换任何进制数
十进制转换任意进制采用短除法。十进制除以任意进制数,将得到的余数逆序排列
3、二进制转八进制与十六进制
每三个二进制对应一个八进制,需要将二进制从右向左划分,没三位一组,高位位数不足补0
010 001 110 转换成八进制:2 1 6
1000 1110 转十六进制:8 E
同理,八进制或者16进制转成二进制
2 1 6 转换成二进制: 010 001 110
8 E 转换成二进制:1000 1110
八进制与十六进制相互转换
八进制转十六进制:可以先将八进制转成二进制,再将二进制转成十六进制
十六进制转八进制:同理,可以先将十六进制转为二进制,再将二进制转成八进制
三、数据的表示(源码、反码、补码、移码
1、原码
原码是将一个数转成二进制表达式,如果用一个字节存储原码不足8位高位补0。带符号的情况下,最高位代表符号位表示正负。为正数时,最高位为0;为负数时,最高位为1。原码是不可以在机器中做运算的,会出错。为了可以达到计算目的,引入接下来的几种码。
2、反码
- 正数的反码:原码相同
- 负数的反码:符号位不变,其它位按位取反
| 数值1 | 数值-1 | 1-1 | |
|---|---|---|---|
| 原码 | 0000 0001 | 1000 0001 | 1000 0010 |
| 反码 | 0000 0001 | 1111 1110 | 1111 1111 |
反码 1111 1111 的原码 是 1000 0000 , 是-0。但0不分正负
3、补码
- 正数的补码:与原码反码相同
- 负数的补码:在原来反码的基础上加1
| 数值1 | 数值-1 | 1-1 | |
|---|---|---|---|
| 原码 | 0000 0001 | 1000 0001 | 1000 0010 |
| 反码 | 0000 0001 | 1111 1110 | 1111 1111 |
| 补码 | 0000 0001 | 1111 1111 | 0000 0000 |
补码 0000 0000 的原码也是 0000 0000,是0。所以补码可以在计算机中做数值运算
4、移码
移码是在补码的基础上产生的
- 正数的移码:补码首位(最高位)取反
- 负数的移码:补码首位(最高位)取反
| 数值1 | 数值-1 | 1-1 | |
|---|---|---|---|
| 原码 | 0000 0001 | 1000 0001 | 1000 0010 |
| 反码 | 0000 0001 | 1111 1110 | 1111 1111 |
| 补码 | 0000 0001 | 1111 1111 | 0000 0000 |
| 移码 | 1000 0001 | 0111 1111 | 1000 0000 |
移码 1000 0000的原码也是 0000 0000,是0
5、数值的表示范围
| 整数 | |
|---|---|
| 原码 | -(2n-1-1)~2n-1-1 |
| 反码 | -(2n-1-1)~2n-1-1 |
| 补码 | -2n-1~2n-1-1 |
n 表示位数
原码、反码与补码表示范围不同的原因是:原码、反码中正 0 和 负0是不同的编码方式,而补码中正0和负0是相同的编码方式。正0是 0000 0000 ,补码是 0000 0000。负0是1000 0000,补码是 0000 0000,正0 和负0 有相同的编码方式。故补码的取值范围是要比原码和反码少占用一个码,取值范围就要比原码和反码多一个
四、数值的表示(浮点数运算)
1、浮点数的表示
N = M * Re
其中M是尾数,R是基数,e是指数
2、计算方式
- 对阶:对阶数化为一致,低阶向高阶化
- 尾数计算:位数计算
- 结果格式化:将计算后的结果格式化,小数点左边需要为1位
五、CPU结构(运算器与控制器的组成)

1、运算器
- 算术逻辑单元ALU:与算法相关
- 累加寄存器AC:运算过程中需要存储一些用到的值的时候需要用到他,不止加法运算需要用到它,减法运算也需要用到它
- 数据缓存寄存器DR:对内存储器进行读写操作的时候,用来存数据的
- 状态条件寄存器PSW(经常考到):用于存储计算过程中相关的标志位,标志位是运算时候的进位,有些运算会溢出
2、控制器
- 程序计算器PC:调解下一个命令的位置,如果是顺序执行,可以在原地基础上加指定
- 指令寄存器IR
- 指令编译器
- 时序部件
这部分要清楚哪些是运算器的部分,哪些是控制器的部分
六、Flynn分类法简介
考察的问题一般是:给你一个代表性的说辞,问是哪一个体系结构,哪一种体系结构不具备一下那些特征。
| 体系结构类型 | 结构 | 关键特性 | 代表 |
|---|---|---|---|
| 单指令流单数据流SISID | 控制器部分:一个,处理器部分:一个,驻村模块:一个 | 单处理器系统 | |
| 单指令流多数据流SIMD | 控制器部分:一个,处理器:多个主存模块:多个 | 各处理器以异步的形式执行同一条命令 | 并列处理机,阵列处理机,超级向量处理机 |
| 多指令流单数据流 | 控制器部分:多个,处理器:一个,主存模块:多个 | 被证明不可能,至少是不实际的 | 目前没有,有文献称流水线计算机为此类 |
| 多指令多数据流 | 控制器部分:多个,处理器:多个,主存模块:多个 | 能够实现作业、任务、指令等各级全面并行 | 多处理机系统多计算机 |
七、CISC和RISC
考察频率比较高,考察的问题一般只有一个形式:对于CISC和RISC哪种说法是正确的?哪些说法是错误的?或者哪些不是CISC/RISC的特点
| 指令系统类型 | 指令 | 寻址方式 | 实现方式 | 其他 |
|---|---|---|---|---|
| CISC(复杂) | 数量多,使用频率差别很大,可变长格式 | 支持多种 | 微程序控制技术(微码) | 研制周期长 |
| RISC(精简) | 数量少,使用频率接近,定长格式,大部分为单周期指令,操作寄存器,中有Load/Store操作内存 | 支持方式少 | 增加通用寄存器,硬布线逻辑控制为主,适合采用l流水线 | 优化编译,有效支持高级语言 |
1、CISC(复杂指令集计算机)
CISC在计算机还没有大规模通用化的时候提出来的,需要根据不同用户做不同的指令,那么指令数量就会相当多。有的指令可能不经常用,有的指令却经常使用,所以使用频率差别大。指令都会有对应的二进制编码,指令的编码长度很可能不同,所以需要使用可变长的格式
2、RISC(精简指令集计算机)
如果想买一台计算机装在软件上跑,人们需要考虑把指令精简化,让计算机适应能力要强一些,如果把复杂的系统做简化,把复杂的指令用最基本的操作替代。比如一个乘法指令,可以看做多个加法指令的累加。在RISC中,指令的数量少,使用的频率也接近,使用定长格式就可以了。为了提高效率,引入了寄存器,只有读取和存储操作内存。又增加了硬布线逻辑控制,相对于软件,虽然设计复杂,但效率高。
流水机
考察的问题一般是:主要是机器相关的问题
1、流水线的基本概念
- 流水线
流水线是指在执行时多条指令重复进行操作的一种准并行处理实现技术。各种部分同时处理是针对不同指令不言的。它们可同时为多条指令的不同部分进行工作,以提高各部分的利用率和指令的平均执行速度 - 没有使用流水线
执行一条指令需要经过取址、分析、执行

顺序执行的时候,有大量部分的时间片是处于空闲状态

- 使用流水线
流水线所做的工作是把这些空闲的片给利用起来,在第一条指令做分析的同时,第二条指令开始做取址。原来是在第一条指令取址、分析、执行都做完后才开始第二条指令。但使用流水线,第一条指令取址后,第二条指令就可以取址了。流水线不仅仅只应用在相应的计算机领域,还应用在相应的工作领域,如汽车制造

2、流水线周期及流水线执行时间计算(考试常考)
流水线周期:(取址、分析、执行三个时间中)执行时间最长的一段
流水线计算公式 : 一条指令的执行时间 +(指令条数 -1 流水线周期*
1)理论公式:(t1+t2+…+tk)+(n-1)*△t(△t表示流水线周期)
2)实践公式:(K+n-1)*△t(第一条指令分几段,K就是几)
例题:若指令流水线把一条指令分为取址、分析和执行三部分,且三部分的时间分别是 取址2ns,分析2ns,执行1ns。那么,流水线周期是多少?100条指令全部执行完毕需要的时间是多少?
1)取址、分析、执行三个时间中执行的时间最长的是取址和分析,都是2ns,所以流水线周期是2ns
2)
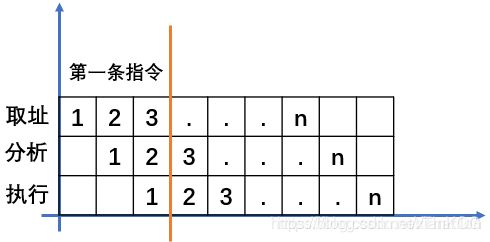
使用理论公式计算: 2+2+1+(100-1)*2 = 203ns
第一条指令执行的时候, 把每一段都看做是一个流水线周期。使用实践公式计算:(3+100-1)*2 = 204ns
3、流水线吞吐率的计算
-
流水线的吞吐率
流水线的吞吐率(Tough Put rate,TP)是指在单位时间内流水线所完成的任务数量或输出的结果数量。计算流水线吞吐率的最基本公式是:
TP = 指令条数 / 流水线执行时间
按照上述例子,计算流水线的吞吐率:
TP = 100 / 203 -
流水线最大吞吐率
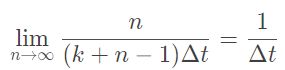
1 是指 :1条指令,△t : 一个流水线周期
理想状态下,忽略流水线建立时间比平常执行时间多消耗的时间,建立之后每一条流水线的周期就会完成一条指令的执行
4、流水线加速比计算
完成同样的任务,不使用流水线所用的时间和使用流水线所用的时间之比称为流水线的加速比。计算流水线的加速比的基本公式如下:

接着2中的例题,计算流水线的加速度比:
S = (2+2+1)*100/203 = 500/203
加速度比越高,使用流水线产生的效果越好
5、流水线的效率
流水线的效率是指流水线的设备利用率。在时空图上,流水线的效率定义为n个任务占用的时空区与K个流水段总的时空区比:

有四个任务,分别是s1、s2、s3、s4,分别占用△t、△t、△t、3△t时间,连续处理四个数据的时空区图如下所示,求流水线的效率
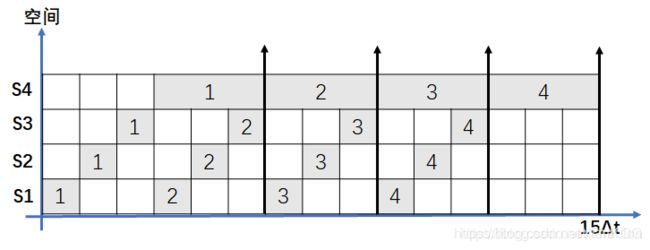
流水线的效率可以这样求:

每一个工作段,时常是相等的情况下,效率才是最高的
九、计算机层次存储结构

需要运行的数据,先从外存调到内存。在CPU与内存交互之间加入Cache。Cache可以将CPU与内存频繁交互的数据暂且放入Cache。当CPU与内存重复交互相同的数据时,CPUR会直接从Cache中拿到数据,不需要再与内存交互,从Cache获取数据时比从内存中快得多。引入Cache 是一种性价比方案,提高速度的同时,没有增加太大的成本。另外,Cache是按照内容存储的,在Cache中不同的内容存入不同的区域。按内容存储的存储器也叫做相连存储器,它的效率要远高于按地址存储。
Cache 的基本概念
1、Cache的功能
提高CPU数据输入和输出的效率,突破吗诺依曼瓶颈,即CPU与存储器系统数据传输带宽限制
2、Cache的定位
在计算机的存储系统体系中,Cache是访问速度最快的层次(考题中,如果没有寄存器,就选择Cache)
3、Cache改善系统性能的依据
使用Cache改善系统性能的依据是程序的局部性原理
4、求使用“Cache+主存储器”的系统的平均周期时间
如果以代表对Cache的访问命中率,t1 表示Cache的周期时间,t2表示主寄存器周期时间,以读操作为例,使用“Cache+主存储器”的系统的平均周期时间为t3,则:
t3 = ht1+(1-h)t1 ,其中 (1-h)又称为失效率(未命中率)
如访问Cache能够获取数据的概率(命中率)是 h = 95%,Cache和主存储器的周期时间分别是1ns、1000ns。如果不适用Cache时平均周期是1000ns,如果使用Cache,平均周期是 1ns95%+1000ns (1-95%) = 50.95ns。显而易见,使用Cache可以大大提高效率。
十一、时间局部性与空间局部性
1、局部性原理
计算机在处理数据和程序时,一般会有某一个时段集中去访问某些指令或者说某个时刻集中读取某些空间的数据。在多级存储体系中,可以用来解决存储量与存储速度之间的矛盾。速度快的成本太高、代价太大,只能做小容量。成本低的,速度慢,有了局部性原理可以得到最合适的性价比
2、时间局部性
刚刚访问完的数据,再次访问,再次访问时直接在Cache中调用数据,而不是从内存中。
3、空间局部性
访问一个空间,再次访问它邻近的空间。如果对数组的初始化、先访问索引为0的数组,再访问索引为1的数组
十二、随机存储器与只读存储器
1、主存的分类
考察的问题一般是:主存的分类和主存的编址,主存的编址考察概率比较高
- 随机存取存储器

内存一旦断电,数据就会丢失(被清除) - 只读存储器

断电后,也可以存储数据。存储BIOS的芯片就是ROM的存储芯片
2、主存编址
- 两个84位的存储器,可以组成一个88位的存储器,也可以组成16*16位的存储器

编址练习题:
内存从AC000H到C7FFFH,共有(1)K个地址单元,如果该内存按字编址,由28片存储器芯片构成。已知构成此内存芯片每片有16K个存储单元,则该芯片每个存储单元存储(2)位?
十三、磁盘工作原理
存取时间 = 寻道时间 + 等待时间(平均定位时间+转动延迟)
注意:寻道时间是指磁头移动到磁道所需要的时间;等待时间是指等待读写的扇区转到磁头下方所用的时间
例题:假设某磁盘的某个磁道划分成11个物理块,每块存放1个逻辑记录。逻辑记录R0,R1,,,R9,R10存放在同一磁道上,记录的存放顺序上下表所示:
| 物理块 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 逻辑记录 | R0 | R1 | R2 | R3 | R4 | R5 | R6 | R7 | R8 | R9 | R10 |
如果磁盘旋转周期是33ms,磁头当前处于R0的开始处。若系统使用单缓冲区顺序处理这些记录,每个记录处理事件是33ms,则处理这11个记录最长时间是多少?若对信息存储进行优化分布后,处理11个记录的最少时间是多少?
十四、计算机总线
1、内部总线
微机内部各个外围芯片与处理器之间的总线,是芯片级别的总线
2、系统总线
系统总线是微机中各个插件版和系统版之间的总线,属于插件版级别。比如PCI、VGA接口
- 数据总线
数据总线是用来传输数据的,如果再64bit的计算机中,一个字就是64bit。总线的宽度就是64bit,一个周期能够传输的数据量是64bit - 地址总线
如果地址总线是32位,地址的空间是22,也就是4G的宽度。如果用的操作系统是32位,那么它能够管理的内存只有4G。如果用到的内存超过4G,就可以考虑使用64位的操作系统,否则操作系统是管理不了这么多的内存空间的。系统总线只有那么宽,那么可管理的内存空间就只有那么大。我们的操作系统之所以能够装64位系统,来管理更大的空间,是因为硬件有这个宽度支持 - 控制总线
适用于发送控制信号的总线
外部总线
微机与外部设备的总线
十五、串联系统与并联系统可靠度的计算
考察的问题一般是:主要是计算,给你一个串并联交织在一起的模型,你要能够计算出它响应的可靠度
1、串联系统
![]()
n个子系统串联在一起、形成了一个大的系统。再串联系统中,所有的子系统都必须正常运行,整个系统才正常。只要有一个系统出问题了,整个系统就不能运行了
- 可靠度的计算
R : 表示可靠度
总可靠度R = R1 x R1 x R2 x…x Rn,也就是把每个子系统的可靠度相乘 - 失效率的计算
λ : 表示失效率
总是效率 λ = λ1+λ2+λ3+…+λn,也就是把所有子系统的失效率加起来
2、并联系统

多个子系统并联在一起,并联系统中多个子系统只要有一个子系统能够运行,整个系统都能运行
- 可靠度计算
R = 1-(1-R1)x(1-R2)x… x(1-Rn) - 失效率的计算
λ = 1-R
3、模冗余系统(几乎不会考到)
4、混合系统(常考)
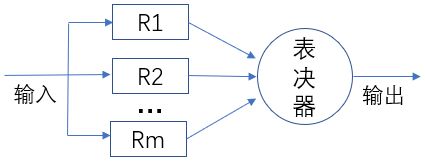
将串联和并联联合到一起,求系统的可靠度。先从总体上看是串行还是并行,然后再确定下计算那一部分,再计算哪一部分
十六、校验码的概念
1、什么是检错和纠错
- 检错:检查出错误
- 纠错:不但要检查出错误,还需要纠正错误
2、什么是码距
一个编码系统的码距是整个编码系统中任意(所有)两个码字的最小距离
例如:
若用一位长度的二进制编码,若A = 1,B = 0,A 与B之间的码距为1(A需要修改一位才能变成B)
若用两位长度的二进制编码,以A=11,B=00为例,A与B之间的码距为2(A需要修改2位才能变成B)
若用三位长度的二进制编码,以A=111,B=000为例,可选用A=111,B=000作为合法编码,A与B之间的码距为3(A需要修改3位才能变成B)
十七、循环校验码(CRC)
循环校验码是一种可以做检错但是不能纠错的一种编码
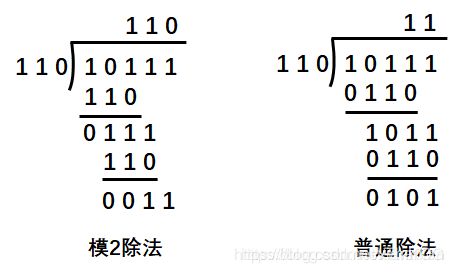
1、模2除法
模2除法是指在做除法运算的过程中不计其进位的除法
2、CRC编码
例题:原始报文为:11001010101,其生成多项式为 :x4+x3+x+1,对其进行CRC编码后的结果为?
- 将生成的多项式转换成二进制形式:x4+x3+x+1也就是 11011
- 在原始报文的后面加上生成多项式位数减去1个0,也就是4个0(其实是补余数的位数)
- 模2除法,模2除法得到4位余数,将4位余数替换刚刚补上的4个0,就得到了CRC编码
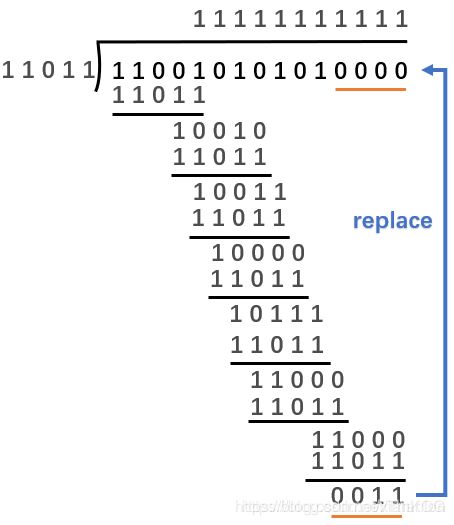
得到的结果是 11001010101 0011 。 将得到的结果与11011做模2运算,得到的结果应该是0, 就对了
十八、奇偶校验码
1、基本概念
奇偶校验码也是一种校验码,它用来检测数据传输过程中是否发生错误,是众多校验码中最为简单的一种。
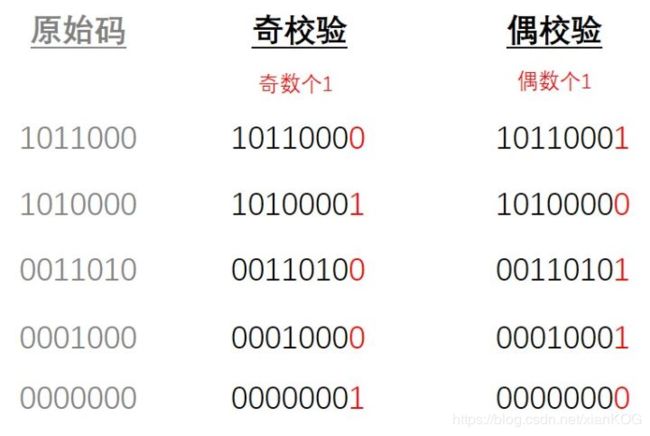
它有两种校验方法:奇校验 和 偶校验
跟CRC类似,也是在原始的码流后面,加上校验位,不同的是,它的校验位只有一位,要么是0,要么是1,并且它的校验位还可以放在码流的前面。
校验位的作用是保持码流中的1的个数满足(奇数个 或者 偶数个)
奇校验:原始码流+校验位 总共有奇数个1
偶校验:原始码流+校验位 总共有偶数个1
2、应用举例
奇偶校验码一个最常见的应用场合就是 ASCII码
ASCII码占用一个字符,低7位是有效位,最高位用作奇偶校验

3、检错能力
只能检测出原始码流中的出错了奇数个错误
例如还是 ASCII码 大写字母A
奇校验 正确码流 11000001(校验位是保证码流中的1个数为奇数个)
错1位 11000011 变成了偶数个,能检测出错误
错2位 11000010 变成了奇数个,不能检测出错误
错3位 11001010 变成了偶数个,能检测出错误
偶校验 正确码流 01000001
错1位 01000011 变成了奇数个1,能检测出错误
错2位 01000010 变成了偶数个1,不能检测出错误
错3位 01001010 变成了奇数个1,能检测出错误
4、奇校验还是偶校验
在实际应用中,到底是选择奇校验还是选择偶校验?其实都是有应用的
奇校验一个重要的特征是产生不了全0代码,所以在实际操作过程中选择的时候要考虑到这一点
十九、海明校验码(难点考察频率高)
1、基本概念
海明码j具有检错和纠错双功能,它基于奇偶校验原理,只能检查出某一位错码的位置。当有多位错码时,它就不适用了。
异或运算
异或运算,相异为1,相同为0。它也叫模2和、模2加法,本质上是不带进位的加法 ,数学符号是 ⊕;
计算机符号 “xor”;
C语言中异或符号是 ^;
常用的公式是: (a ^ b) ^ a = b,即两个数异或结果在与其中一个数异或得到的是另一个数。
常用的应用:多用在一些加密算法中,将要加密的数据和一些已知的数进行异或运算,得到加密后的数据。
2、 海明码的校验位数
下面本例以 1010110 为例进行海明码编码
第一步先确定需要多少位校验码位数。
设数据有n位,校验码有x位。则校验码一共有2x中取值方式。其中需要一种取值方式表示数据正确,剩下2x-1中取值方式表示有一种数据出错。因为编码后的二进制串有n+x位,因此x应该满足:
2x-1 >= n + x
使不等式成立的x的最小值就是校验码的位数。在本例中,n
=7,解得 x =4。
信息码和校验码的对应关系如下表:

3、校验码的位置
校验码在二进制中的位置为2的整数幂,即 1、2、4、8、16…剩下的位置是信息码,如图,绿色为校验位:
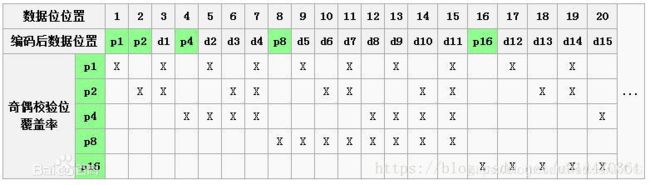
本例的校验码位置如下图:

4、计算校验码的值
由于奇偶校验原理一样,偶校验的计算更为简单,实际中多为偶校验,本例中也以偶校验进行计算
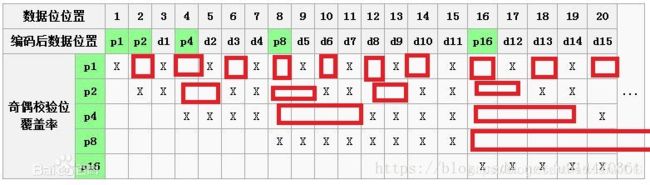
如图中:
第一行中每个X跳过1位;第一行所有的X值进行异或是0;第一行的X对应的数据位位置转化为二进制最后一位都是1,即是xxx1这种形式
第二行中每2个X跳过2位;第二行所有的X值进行异或是0;第二行的X对应的数据位位置转化为二进制倒数第二位一位都是1,即是xx1x这种形式;
第三行中每4个X跳过4位,第三行所有的X值进行异或是0,;第三行的X对应的数据位位置转化为二进制倒数第三位一位都是1,即是x1xx这种形式
第四行中每8个X跳过8位,第四行所有的X值进行异或是0;第四行的X对应的数据位位置转化为二进制倒数第四位一位都是1,即是1xxx这种形式
下面计算本例,将表格中的位置用二进制表示:

x1的计算:
x1是第一个校验码,位置对应栏所有最后一位为1(xxx1格式)的异或为0,即
x1 ⊕ 1 ⊕ 0 ⊕ 0 ⊕ 1 ⊕ 0 = 0
则x1 = 0;
x2计算:
x2是第二个校验码,位置对应栏中所有倒数第二位为1(xx1x格式)的异或为0,即
x2 ⊕ 1 ⊕ 1 ⊕ 0 ⊕ 1 ⊕ 0 = 0;
则x2 = 1;
x3计算:
x3是第三个校验码,位置对应栏所有倒数第三位为1(x1xx格式)的异或为0,即:
x3 ⊕ 0 ⊕ 1 ⊕ 0 = 0;
则x3 = 1;
x4计算:
x4是第四个校验位,位置对应栏所有倒数第四位为1(1xxx格式)的异或为0,即:
x4 ⊕ 1 ⊕ 1 ⊕ 0 = 0;
则x4 = 0;
**所以最终 海明码为 0 1 1 1 010 0110
5、海明码的校验
假设位置为1011的数据传输错误,由0变成1,则校验纠错的过程为:
将所有位置形如 xxx1,xx1x,x1xx,1xxx的数据分别异或。
xxx1:0 ⊕ 1 ⊕ 0 ⊕ 0 ⊕ 1 ⊕ 1 = 1
xx1x:1 ⊕ 1 ⊕ 1 ⊕ 0 ⊕ 1 ⊕ 1 = 1
x1xx:1 ⊕ 0 ⊕ 1 ⊕ 0 = 0
1xxx:0 ⊕ 1 ⊕ 1 ⊕ 1 = 1
那么出错数据的位置为 1011,这样便可得到出错的位置
假设同时有两个位置出错,本例中设位置 为 1010 对应数据1-> 0,位置 1011 对应位置 0-> 1,则推出校验纠错过程:
xxx1 : 0 ⊕ 1 ⊕ 0 ⊕ 0 ⊕ 1 ⊕ 1 = 1
xx1x: 1 ⊕ 1 ⊕ 1 ⊕ 0 ⊕ 0 ⊕ 1 = 0
x1xx: 1 ⊕ 0 ⊕ 1 ⊕ 0 = 0
1xxx: 0 ⊕ 1 ⊕ 0 ⊕ 1 = 0
那么校验出的错误位是 0001 ,即第一位;但实际上是倒数第二位和倒数第一位都有错误,说明海明码不能校验两位及以上出错的数据,即 海明码只能检测并纠正一位错误
例题:求 1011的海明码
已知数据位数 n = 4,校验位x
又 2x-1 >= n + x ,得 x = 3
或者直接由图可知:
则
| 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 |
|---|---|---|---|---|---|---|
| x1 | x2 | 1 | x3 | 0 | 1 | 1 |
由 x1 ⊕ 1 ⊕ 0 ⊕ 1 = 0 得 x1 = 0
由 x2 ⊕ 1 ⊕ 1 ⊕ 1 = 0 得 x2 = 1
由 x3 ⊕ 0 ⊕ 1 ⊕ 1 = 0 得 x3 = 0
则海明码为:0110011