超赞,大神总结的Java内存模型与指令重排!
你知道的越多,不知道的就越多,业余的像一棵小草!
你来,我们一起精进!你不来,我和你的竞争对手一起精进!
编辑:业余草
来源:cnblogs.com/xdecode/p/8988246.html
推荐:https://www.xttblog.com/?p=5062
本文暂不深入讲解 JMM(Java 内存模型)中的主存、工作内存以及数据如何在其中流转等。因为这些本身还牵扯到硬件内存架构,直接上手容易绕晕。先从以下几个点探索JMM:
原子性;
有序性;
可见性;
指令重排:CPU 指令重排、编译器优化重排;
Happen-Before 规则。
原子性
原子性是指一个操作是不可中断的。即使多个线程一起执行,一个操作一旦开始,就不会被其它线程干扰。例如 CPU 中的一些指令属于原子性的,又或者变量直接赋值操作 (i = 1) 也是原子性的。即使有多个线程对 i 赋值相互也不会干扰。
而 i++ 则不是原子性的, 因为实际上它等价于 i = i + 1。若有多个线程操作 i,结果将不可预期。

有序性
有序性是指,在单线程环境中程序是按序依次执行的。而多线程环境中, 程序的执行可能因为指令重排而出现乱序,下文会有详细讲述。
class OrderExample {
int a = 0;
boolean flag = false;
public void writer() {
// 以下两句执行顺序可能会在指令重排等场景下发生变化
a = 1;
flag = true;
}
public void reader() {
if (flag) {
int i = a + 1;
……
}
}
}

可见性
可见性是指,当一个线程修改了某一个共享变量的值,其他线程是否能够立即知道这个修改。有多个场景会影响到可见性:
CPU 指令重排
多条汇编指令执行时, 考虑性能因素会导致执行乱序。下文会有详细讲述。
硬件优化(如写吸收、批操作)
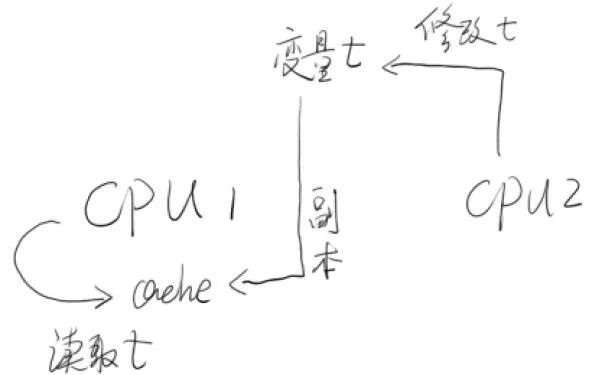
CPU2 修改了变量 T,而 CPU1 却从高速缓存 cache 中读取了之前 T 的副本,导致数据不一致。
编译器优化
主要是 Java 虚拟机层面的可见性,下文会有详细讲述。
指令重排
指令重排是指在程序执行过程中,为了性能考虑编译器和 CPU 可能会对指令重新排序。
CPU指令重排
一条汇编指令的执行是可以分为很多步骤得,分为不同的硬件执行:
取指 IF;
译码和取寄存器操作数 ID;
执行或者有效地址计算 EX(ALU 逻辑计算单元);
存储器访问 MEM;
写回 WB(寄存器)。
既然指令可以被分解为很多步骤,那么多条指令就不一定依次序执行。
因为每次只执行一条指令依次执行效率太低了。假设上述每一个步骤都要消耗一个时钟周期,那么依次执行的话一条指令要5个时钟周期,两条指令要占用10个时钟周期,三条指令消耗15个时钟。
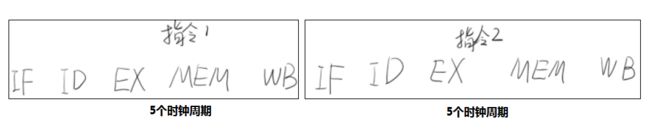
而如果硬件空闲即可执行下一步,类似于工厂中的流水线,一条指令要5个时钟周期。两条指令只需要6个时钟周期。因为是错位流水执行,三条指令消耗7个时钟。

举个例子 A = B + C 需要如下指令:
指令1 : 加载 B 到寄存器 R1中;
指令2 : 加载 C 到寄存器 R2 中;
指令3 : 将 R1 与 R2 相加,得到 R3;
指令4 : 将 R3 赋值给 A。
注意下图红色框选部分:指令1、2独立执行,互不干扰。指令3依赖于指令1、指令2加载结果,因此红色框选部分表示在等待指令1、指令2结束。待指令1、指令2都已经走完 MEM 部分。数据加载到内存后,指令3继续执行计算 EX。同理,指令4需要等指令3计算完才可以拿到 R3,因此也需要错位等待。

再来看一个复杂的例子:
a = b + c
d = e - f
具体指令执行步骤如下图,不再赘述。与上图类似,在执行过程中同样会出现等待。

这边框选的 X 统称一个气泡。有没有什么方案可以削减这类气泡呢?
答案自然是可以的。我们可以在出现气泡之前执行其他不相干指令来减少气泡。例如,可以将第五步的加载 e 到寄存器提前执行,消除第一个气泡。同理,将第六步的加载 f 到寄存器提前执行,消除第二个气泡。

经过指令重排后,整个流水线会更加顺畅,无气泡阻塞执行。

原先需要14个时钟周期的指令,重排后只需要12个时钟周期即可执行完毕。指令重排只可能发生在毫无关系的指令之间,如果指令之间存在依赖关系则不会重排。例如:指令1为 a = 1,指令2为 b = a - 1。则指令1、指令2 不会发生重排。
编译器优化
主要指 JVM 层面,如下面代码:在 JVM Client 模式很快就跳出了 while 循环;而在 Server 模式下运行,永远不会停止。
/**
* Created by Administrator on 2018/5/3/0003.
*/
public class VisibilityTest extends Thread {
private boolean stop;
public void run() {
int i = 0;
while (!stop) {
i++;
}
System.out.println("finish loop,i=" + i);
}
public void stopIt() {
stop = true;
}
public boolean getStop() {
return stop;
}
public static void main(String[] args) throws Exception {
VisibilityTest v = new VisibilityTest();
v.start();
Thread.sleep(1000);
v.stopIt();
Thread.sleep(2000);
System.out.println("finish main");
System.out.println(v.getStop());
}
}
以32位 JDK 1.7.0_55为例,可以通过修改 JAVA_HOME/jre/lib/i386/jvm.cfg 将 JVM 调整为 Server 模式验证。修改内容如下图所示,将 -server 调整到 -client 的上面。
-server KNOWN
-client KNOWN
-hotspot ALIASED_TO -client
-classic WARN
-native ERROR
-green ERROR
修改成功后 java -version 会产生如下变化:

两者区别在于:当 JVM 运行在 -client 模式的时候,使用的是一个代号为 C1 的轻量级编译器;而 -server 模式启动的虚拟机采用相对更重量级的 C2 的编译器。C2 比 C1 编译器编译得相对彻底。虽然这会导致程序启动慢,但服务起来之后性能更高,同时有可能带来可见性问题。
将上述代码运行的汇编代码打印出来,打印方法也简单提一下。给主类运行时加上 VM Options:
-XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly
此时会提示:
Could not load hsdis-i386.dll; library not loadable; PrintAssembly is disabled
因为打印汇编需要给 JDK 安装一个插件,可能需要自己编译 hsdis。不同平台不太一样:Windows 下32位 JDK 需要的是 hsdis-i386.dll;64位 JDK 需要 hsdis-amd64.dll。把编译好的 hsdis-i386.dll 放到 JAVA_HOME/jre/bin/server 以及 JAVA_HOME/jre/bin/client 目录中运行代码。控制台会把代码对应的汇编指令一起打印出来。
输出会有很多行,只需要搜索 run 方法对应的汇编。搜索 'run' '()V' in 'VisibilityTest' 可以找到对应的指令。如下面的代码所示,从第26、27行注释的部分可以看出:只有第一次进入循环之前检查了下 stop 的值;不满足条件进入循环后,不再检查 stop, 一直在做循环 i++。
public void run() {
int i = 0;
while (!stop) {
i++;
}
System.out.println("finish loop,i=" + i);
}
# {method} 'run' '()V' in 'VisibilityTest'
......
0x02d486e9: jne 0x02d48715
// 获取stop的值
0x02d486eb: movzbl 0x64(%ebp),%ecx ; implicit exception: dispatches to 0x02d48703
0x02d486ef: test %ecx,%ecx
// 进入while之前, 若stop满足条件, 则跳转到0x02d48703, 不执行while循环
0x02d486f1: jne 0x02d48703 ;*goto
; - VisibilityTest::run@12 (line 10)
// 循环体内, i++
0x02d486f3: inc %edi ; OopMap{ebp=Oop off=52}
;*goto
; - VisibilityTest::run@12 (line 10)
0x02d486f4: test %edi,0xe00000 ;*goto
; - VisibilityTest::run@12 (line 10)
; {poll}
// jmp, 无条件跳转到0x02d486f3, 一直执行i++操作, 根本不检查stop的值
// 导致死循环
0x02d486fa: jmp 0x02d486f3
0x02d486fc: mov $0x0,%ebp
0x02d48701: jmp 0x02d486eb
// 跳出循环
0x02d48703: mov $0xffffff86,%ecx
......
解决方案也很简单,只要给 stop 加上 volatile 关键字。再次输出汇编代码,发现每次都会检查 stop 值,不再出现无限循环了。
// 给stop加上volatile后
public void run() {
int i = 0;
while (!stop) {
i++;
}
System.out.println("finish loop,i=" + i);
}
# {method} 'run' '()V' in 'VisibilityTest'
......
0x02b4895c: mov 0x4(%ebp),%ecx ; implicit exception: dispatches to 0x02b4899d
0x02b4895f: cmp $0x5dd5238,%ecx ; {oop('VisibilityTest')}
// 进入while判断
0x02b48965: jne 0x02b4898d ;*aload_0
; - VisibilityTest::run@2 (line 9)
// 跳转到0x02b48977获取stop
0x02b48967: jmp 0x02b48977
0x02b48969: nopl 0x0(%eax) // 循环体内, i++
0x02b48970: inc %ebx ; OopMap{ebp=Oop off=49}
;*goto
; - VisibilityTest::run@12 (line 10)
0x02b48971: test %edi,0xb30000 ;*aload_0
; - VisibilityTest::run@2 (line 9)
; {poll}
// 循环过程中获取stop的值
0x02b48977: movzbl 0x64(%ebp),%eax ;*getfield stop
; - VisibilityTest::run@3 (line 9)
// 验证stop的值
0x02b4897b: test %eax,%eax
// 若stop不符合条件, 则继续跳转到0x02b48970: inc, 执行i++, 否则中断循环
0x02b4897d: je 0x02b48970 ;*ifne
; - VisibilityTest::run@6 (line 9)
0x02b4897f: mov $0x33,%ecx
0x02b48984: mov %ebx,%ebp
0x02b48986: nop
// 跳出循环, 执行System.out.print打印
0x02b48987: call 0x02b2cac0 ; OopMap{off=76}
;*getstatic out
; - VisibilityTest::run@15 (line 12)
; {runtime_call}
0x02b4898c: int3
0x02b4898d: mov $0xffffff9d,%ecx
......
再来看两个 Java 语言规范中的例子,同样涉及到编译器优化重排。这里不再做详细解释,只介绍结果:例子1中有可能出现 r2 = 2 并且 r1 = 1 的情况。

例子2中是 r2,r5 值因为都等于 r1.x,编译器会使用向前替换,把 r5 指向到 r2。最终可能导致 r2=r5=0,r4 = 3;

Happen-Before 先行发生规则
如果光靠 sychronized 和 volatile 来保证程序执行过程中的原子性、有序性、可见性,那么代码将会变得异常繁琐。JMM 提供了 Happen-Before 规则来约束数据之间是否存在竞争,线程环境是否安全。具体如下:
顺序原则
一个线程内保证语义的串行性:a = 1; b = a + 1;
volatile 规则
volatile 变量的写先发生于读,从而保证了 volatile 变量的可见性。
锁规则
解锁(unlock)必然发生在随后的加锁(lock)前。
传递性
A 先于 B,B 先于 C,那么 A 必然先于 C。
线程启动、中断、终止
线程的 start() 方法先于它的每一个动作;
线程的中断 interrupt() 先于被中断线程的代码;
线程的所有操作先于线程的终结 Thread.join()。
对象终结
对象的构造函数执行结束先于 finalize() 方法。
