转自:
http://www.gxitsky.com/2019/05/01/springcloud-14-tracing-sleuth-zipkin-principle/
Sleuth 通过 traceId 实现了对分布式系统调用链路的跟踪。在一次服务请求链路中,会保持并传递一个 traceId,从而将不同服务的请求跟踪信息串联起来,不同服务的 traceId 相同表示处在同一请求链中。
基于 HTTP 请求的数据传递有两种方式:一种是做为参数传递,另一种是做为头信息传递。而 Sleuth 的 traceId 属于附加信息,不参与实际的业务,所以做为参数传递并不合适,实际也是作为头信息来传递的。
Request Header
参考 Spring Cloud系列(十三):分布式服务链路跟踪 Sleuth 中的示例项目,Sleuth 会在请求的 Header 中增加实现跟踪需的信息,给远程调用接口打上断点,使用 request.getHeaderNames() 取出所有头信息。
Headers
1 |
["x-b3-spanid","x-b3-parentspanid","x-b3-sampled","x-b3-traceid","accept","user-agent","host","connection"] |
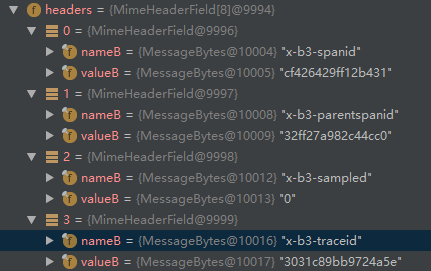
可以看到,在请求头信息中多了 4 个属性:
- x-b3-spanid:一个工作单元(rpc 调用)的唯一标识。
- x-b3-parentspanid:当前工作单元的上一个工作单元,Root Span(请求链路的第一个工作单元)的值为空。
- x-b3-traceid:一条请求链条(trace) 的唯一标识。
- x-b3-sampled:是否被抽样为输出的标志,1 为需要被输出,0 为不需要被输出。
日志跟踪接入
Sleuth 会把跟踪数据 (appname、traceId、spanId、exportable) 添加到 Slf4J MDC 中,因此您可以从日志聚合器中的给定跟踪或跨度中提取所有日志,如以下示例日志中所示:
1 |
2016-02-02 15:30:57.902 INFO [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ... |
MDC 的实现实际是将需要记录到日志的信息设置到当前线程的上下文(ThreadContext)中。
MDC 中的信息:[appname,traceId,spanId,exportable]
- appname:应用名称,即 spring.application.name 的值。
- tranceId:整个请求链路的唯一ID。
- spanId:基本的工作单元,一个 RPC 调用就是一个新的 span。启动跟踪的初始 span 称为 root span ,此 spanId 的值与 traceId 的值相同。
- exportable:是否将数据导入到 Zipkin 中,true 表示导入成功,false 表示导入失败。
Sleuth 跟踪原理
分布式系统中的服务调用链路跟踪在理论上并不复杂,主要有个关键点,一个是为请求链路创建唯一跟踪标识,二个统计各个处理单元的延迟时间。
- 为了实现请求链路跟踪,当请求发送到分布式系统的入口时,只需要在服务跟踪框架为该请求创建唯一的跟踪标识,并保证该标识在在分布式系统内部流转,直到返回请求为止。该标识即为 traceId,通过该标识,就能将不同服务调用的日志串联起来。
- 为了统计各处理单元(应用服务)的延迟,当请求到达或处理逻辑达到某个状态时,也通过一个唯一标识来标记开始、具体过程及结束(标识一个服务内请求进入、处理到结束),该标识即为 spanId。对于每个 spanId 来说,必须有开始和结束两个节点,通过计算开始 span 和 结束 span 的时间戳,就能统记出该 span 的时间延迟。
Sleuth 采样比例
跟踪信息收集默认是 0.1(10%) 的采样比例,可通过 probability 属性修改;或可采用每秒速率来控制采集数据,属性是 rate。
1 |
# 跟踪信息收集采样比例,默认 0.1,为 1 是即 100%,收集所有 |
Brave 分布式跟踪
从版本 2.0.0 开始,Spring Cloud Sleuth 使用 Brave 作为跟踪库。 因此,Sleuth 不再负责存储上下文,而是将该工作委托给 Brave。
由于 Sleuth 与 Brave 有不同的命名和标记惯例,我们决定从现在开始遵循 Brave 的惯例。 但是,如果要使用传统的侦听方法,可以将 spring.sleuth.http.legacy.enabled 属性设置为 true。
Span 上下文传播
Span Context(上下文) 必须传播到跨进程边界的任何 子 Span 状态。Span Context 还是一部分是 Baggage。Trace ID 和 Span ID 是 Span Context 必需的,Baggage 是可选的。
Baggage 是一组存储在 Span Context 中的 key:value(键值对)。Baggage 与 Traceg 一起移动并附在每个 Span 上。Spring Cloud Sleuth 可以识别以 baggage- 为前缀的 HTTP 头,这是与 baggage 相关的头,消息传递以 baggage_ 开始。
目前,Baggage 的数量和大小没有限制。但是,太多会降低系统吞吐量或增加 RPC 延迟。在极端情况下,过多的 Baggage 会导致应用程序崩溃,因为超过了传输级别的消息或报头容量。
在 Span Context 中设置 Baggage 示例:
1 |
Span initialSpan = this.tracer.nextSpan().name("span").start(); |
Baggage 与 Span Tags
Baggage 跟随 Trace 一起移动(每个子 span 都包含 父 span 的 Baggage)。Zipkin 不知道 baggage ,也不接收这些信息。
注意:从 Sleuth 2.0.0 开始,必须在项目配置中明确传递 baggage 钥匙名称。
Tags 附加到指定的 span ,也就是该标签只在指定的 span 呈现。但是,如果包含 Tag 的 span 存在,则可以根据 Tag 搜索 trace。
如果希望能够根据 baggage 查找 span*,则应在 *root span 中添加相应的元素作为 Tag。
baggage 集成示例:
1 |
spring.sleuth.baggage-keys=baz,bizarrecase |
1 |
initialSpan.tag("foo",ExtraFieldPropagation.get(initialSpan.context(), "foo")); |