Android二维码原理与优化方向
困惑
做过Android的二维码扫描的童鞋可能会遇到过,很多二维码识别不了,或者识别速度慢。一般造成这个识别不出来的原因,大概以下几点:
- Android手机配置不一样,手机像素高低也有不同,有的手机还不支持自动对焦
- 环境影响也特别大,亮光,反光、粉尘、灰尘、距离都会导致识别不佳
- A4纸张打印的标签二维码,本来打印就不是特别清晰,有些像素点,不一定都打印了出来
但是用微信扫一扫,却能很快的识别出上面几种情况造成的二维码;又或者用支付宝或者钉钉二维码扫描,一样也能识别出来;还有iOS也就是调用系统的扫描,也一样能够扫描出来,为啥我们自己的不行?老板不管这些,只是说了,别人的可以,为啥你的不可以,那就是你的问题…
于是网上找了很多各种几千个赞的第三方集成的二维码,发现也不怎么理想,总是比不上微信、支付宝等。Github上何种上千Star的第三方库都是基于ZXing或者ZBar,最后一圈下来你得出结论:ZXing和ZBar不行。你会想:这微信和支付宝都是基于啥开发的,如果能开源一下那就太好了。下面我们就聊一聊微信扫一扫与支付宝扫一扫的原理~
微信扫一扫
微信官方公众号“微信派”就特别介绍了微信二维码扫描功能的一些技术细节。
预判算法
微信扫码使用了自家开发的QBar引擎,并计入了预判算法,在识别条码之前会过滤无码图像,只识别有意义的内容(二维码和条形码)。
整个扫码预判模块位于核心识别引擎之前,不再需要对输入的视频中的每一帧图像进行检测识别,能实现快速过滤大量无码图像,减少后续不必要的定位和识别对扫码客户端造成的阻塞,使响应更加及时,增加扫码过程中的流畅度,而这就是微信扫码快速的关键原因。
微信团队分析数据显示,该引擎在识别正常图片时的解码速度,iOS可缩短至5毫秒,安卓也仅仅约12毫秒,当然这也和手机配置尤其是摄像头有很大关系。
容错性解码、多语言字符检测算法
QBar扫码引擎对二维码容错性解码算法、多语言字符检测算法等均使用进行了数十项优化,在识别率和识别速度上得到了提升。
一些二维码就算出现穿孔、污损或者弯折,还是一样可以识读,这是因为二维码中存储的信息通常都经过了纠错编码,是有冗余的。
一个二维码所能表示的比特数是固定的,包含的信息越多那么冗余度就越小,反之亦然。微信二维码中包含的信息量并不需要很大,这意味着编码的冗余度可以做得较高,所以即使损毁面积达到30%也依旧可以恢复。简单来说,QBar识别及解码的流程包括:
- 读取视频或图像,通过灰度化处理得到单张灰度图;
- 对灰度图进行处理得到二值图像(二值化是引擎在识别前把图像转换成01图像的过程);
- 将二值图输入不同的解码器识别是否存在二维码;
- 如果检测到存在某种编码,即通过相应的解码器进行解码,并返回解码结果。
在提高成功解码的概率上,微信的另一个做法就是给每个步骤做上“标签”,目的是找出错误信息,对失败信息再设置相应的二次检测流程,在失败的步骤处进行更”努力”地尝试,且越到后面的步骤,表明图中存在二维码的概率越大。
通过这样每步找错、多次识别解码,大大提高了手机扫描二维码的成功率。
什么是QBar
上面说的QBar好像很牛逼,微信又不开源,说的越牛逼越觉得坑爹:你这么牛逼我又用不了。
我们尝试着去窥探微信安装包,打开目录lib\armeabi。里面包涵了微信安卓应用所用到的C/C++动态链接库。大概扫一下,看到了libwechatQrMod.so,应该就是用于二维码的了。用atom打开,居然发现了这个:

微信的1D/2D barcode解码居然用的是开源的ZXing!突然对ZXing燃起了希望。没错,QBar的底层就是ZXing,不过微信团队做了非常多的优化。当然了,我们也是可以优化的,下一步可以好好研究优化方向了~~
支付宝扫一扫
支付宝扫一扫是基于libqrencode 库集成的,既然ZXing可以做到这个效果,libqrencode 就没必要再过多研究。
ZXing扫码优化
一般我们做二维码扫描的功能,会到https://github.com/zxing/zxing 拉代码,然后取出Android部分的demo运行,成功之后便开始移植到自己的工程。如果是这样,那么恭喜,你已经入坑了。官方的demo,扫码功能无可厚非是没问题的,但是因为是一个大而全的demo,更多考虑的是功能的集成。实际上我们每个项目的需求不同,当你的需求考虑上扫码速度与识别率的时候,官方的demo就会显得有点跟不上。你会发现:
微信扫一扫是基于ZXing,你的扫一扫也是基于ZXing,为啥识别速度与识别效率天差地别?
所以我们需要做大量的定制型优化。
减少解码格式提高解码速度
ZXing默认支持15种格式,支持格式有QR Code、Aztec、Code 128、Code 39、EAN-8 等等。然后我们在实际中用不到这么多解码样式,我们常见的二维码格式是QR Code,一维码格式为Code 128, 如果无特殊要求,这两种格式就能满足一般的条码与二维码的需求。 在解码过程中减少一种解码,就会减少解析时间,提高解码速度。所以我们在实践过程中可以根据实际减少解码样式,提高解码速度,如果app实际只有二维码扫码,甚至可以只保留QR Code这一种解码格式。
ZXing 我们可以修改DecodeFormatManager 及DecodeThread这两个类减少解码种类
//DecodeFormatManager.java 只保留二维码相关
static {
...
QR_CODE_FORMATS = new Vector<BarcodeFormat>(1);
QR_CODE_FORMATS.add(BarcodeFormat.QR_CODE);
...
}
//DecodeThread.java 只保留二维码相关
if (decodeFormats == null || decodeFormats.isEmpty()) {
decodeFormats = new Vector<BarcodeFormat>();
decodeFormats.addAll(DecodeFormatManager.QR_CODE_FORMATS);
}
解码算法优化
目前我们在Zxing我们能看到HybridBinarizer及GlobalHistogramBinarizer,HybridBinarizer继承自GlobalHistogramBinarizer,在其基础上做了功能改进。这两个类都是Binarizer的实现类,都是基于二值化,将图片的色域变成黑白两个颜色,然后提取图形中的二维码矩阵。
官网上介绍GlobalHistogramBinarizer算法适合低端设备,对手机CPU和内存要求不高。但它选择了全部的黑点来计算,因此无法处理阴影和渐变这两种情况。HybridBinarizer的算法在执行效率上要慢于GlobalHistogramBinarizer算法,但识别相对更加有效,它专门以白色为背景的连续黑块二维码图像解析而设计,也更适合来解析更具有严重阴影和渐变的二维码图像。
zxing项目官方默认使用的是HybridBinarizer二值化方法。然而目前的大部分二维码都是黑色二维码,白色背景的。不管是二维码扫描还是二维码图像识别,使用GlobalHistogramBinarizer算法的效果要稍微比HybridBinarizer好一些,识别的速度更快,对低分辨的图像识别精度更高。可以在DecodeHandler 中更改算法:
private void decode(byte[] data, int width, int height) {
//优先GlobalHistogramBinarizer解码,解码失败转为HybridBinarizer解码
BinaryBitmap bitmap = new BinaryBitmap(new GlobalHistogramBinarizer(source));
if(bitmap == null){
bitmap = new BinaryBitmap(new HybridBinarizer(source));
}
}
便提下,微信扫码使用了自家开发基于ZXing的QBar引擎,并导入了预判算法,在识别条码之前会过滤无码图像,只识别有意义的内容——二维码和条形码。整个扫码预判模块位于核心识别引擎之前,不再需要对输入的视频中的每一帧图像进行检测识别,能实现快速过滤大量无码图像,减少后续不必要的定位和识别对扫码客户端造成的阻塞,使响应更加及时,增加扫码过程中的流畅度,而这就是微信扫码快速的关键原因。
减少解码数据
现在的手机拍照的照片像素都很高,目前市场上好一点手机像素都上千万,拍摄一张照片的就十几M, 这个大的数据量对解码很有压力,我们在开发过程有必要采取措施减少解码数据量。
官方为了减少解码的数据,提高解码效率和速度,利用扫码区域范围来裁剪裁剪无用区域,减少解码数据。我们在开发过程可以调整好扫码区域,减少解码的数据量。
private void decode(byte[] data, int width, int height) {
//只识别的识别框的区域
scanBoxAreaRect = mScanBoxView.getScanBoxAreaRect(height);
PlanarYUVLuminanceSource = new PlanarYUVLuminanceSource(
data,
width,
height,
scanBoxAreaRect.left,
scanBoxAreaRect.top,
scanBoxAreaRect.width(),
scanBoxAreaRect.height(),
false
);
}
将处理相机帧从串行改为并行
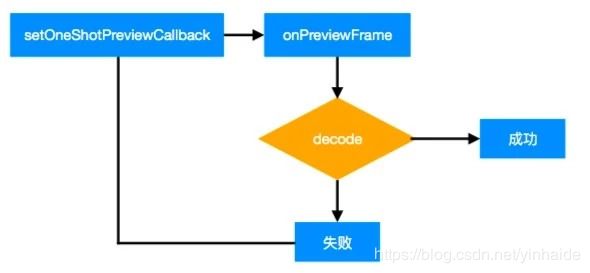
ZXing的demo每次从onPreviewFrame()中获取一帧数据,发送R.id.decode的handler消息队列,然后调用zxing的decode解析二维码,如果成功,则返回;如果失败,则调用setOneShotPreviewCallback( ),重新调用一次onPreviewFrame( )。
缺点是如果处理一帧数据时间很长,会阻碍下一帧的处理,比如上一帧是没有二维码的,而下一帧是有二维码的,如果上一帧处理时间较长,那么虽然用户对准了二维码,但是实际处理的还是上一帧,因此不太合理。
//DecodeHandler.java
@Override
public void handleMessage(Message message) {
if (message.what == R.id.decode) {
decode((byte[]) message.obj, message.arg1, message.arg2);
}
}
我们将串行处理改成并行处理,一旦从onPreviewFrame( )获取一帧数据,将decode任务丢进线程池,并立即调用setOneShotPreviewCallback( )获取下一帧数据。一旦某个任务检测到二维码,立即将isSuccess变量置为true,忽略其他任务。这样能够大大加快二维码检测的速度。
@Override
public void onPreviewFrame(final byte[] data, final Camera camera) {
...
mProcessDataTask = new ProcessDataTask(camera, data, this,HDQRCodeUtil.isPortrait(getContext())).perform();
}
优化相机设置
二维码扫描解码除了上述因素外,还有一个重大的相关因素就是相机设置方面的。如果我们预览的图片模糊、或者二维码拉伸、图片过小、图片旋转或者扭曲等,都会导致很难定位到二维码,解析二维码困难。
选择最佳预览尺寸/图片尺寸
如果手机摄像头生成的预览图片宽高比和手机屏幕像素宽高比(准确地说是和相机预览屏幕宽高比)不一样的话,投影的结果肯定就是图片被拉伸。现在基本上每个摄像头支持好几种不同的预览尺寸(parameters.getSupportedPreviewSizes()),我们可以根据屏幕尺寸来选择相机最适合的预览尺寸,当然如果相机支持的预览尺寸与屏幕尺寸一样更好,否则就找到宽高比相同,尺寸最为接近的。
//一下算法是:比例优先 尺寸接近次之
Camera.Size mCameraResolution = findCloselySize(displayMetrics.widthPixels, displayMetrics.heightPixels,parameters.getSupportedPreviewSizes());
Camera.Parameters parameters = camera.getParameters();
parameters.setPreviewSize(mCameraResolution.width, mCameraResolution.height);
camera.setParameters(parameters );
/**
* 通过对比得到与宽高比最接近的尺寸(如果有相同尺寸,优先选择)
*
* @param surfaceWidth 需要被进行对比的原宽
* @param surfaceHeight 需要被进行对比的原高
* @param preSizeList 需要对比的预览尺寸列表
* @return 得到与原宽高比例最接近的尺寸
*/
protected Camera.Size findCloselySize(int surfaceWidth, int surfaceHeight, List<Camera.Size> preSizeList) {
Collections.sort(preSizeList, new SizeComparator(surfaceWidth, surfaceHeight));
return preSizeList.get(0);
}
/**
* 预览尺寸与给定的宽高尺寸比较器。首先比较宽高的比例,在宽高比相同的情况下,根据宽和高的最小差进行比较。
*/
private static class SizeComparator implements Comparator<Camera.Size> {
private final int width;
private final int height;
private final float ratio;
SizeComparator(int width, int height) {
//不管横屏还是竖屏,parameters.getSupportedPreviewSizes()的size.width 始终大于 size.height
if (width < height) {
this.width = height;
this.height = width;
} else {
this.width = width;
this.height = height;
}
this.ratio = (float) this.height / this.width;
}
@Override
public int compare(Camera.Size size1, Camera.Size size2) {
int width1 = size1.width;
int height1 = size1.height;
int width2 = size2.width;
int height2 = size2.height;
float ratio1 = Math.abs((float) height1 / width1 - ratio);
float ratio2 = Math.abs((float) height2 / width2 - ratio);
int result = Float.compare(ratio1, ratio2);
if (result != 0) {
return result;
} else {
int minGap1 = Math.abs(width - width1) + Math.abs(height - height1);
int minGap2 = Math.abs(width - width2) + Math.abs(height - height2);
return minGap1 - minGap2;
}
}
}
还有另外一种算法:尺寸最接近优先
private static Point findBestPreviewSizeValue(List<Camera.Size> supportSizeList, Point screenResolution) {
int bestX = 0;
int bestY = 0;
int diff = Integer.MAX_VALUE;
for (Camera.Size previewSize : supportSizeList) {
int newX = previewSize.width;
int newY = previewSize.height;
int newDiff = Math.abs(newX - screenResolution.x) + Math.abs(newY - screenResolution.y);
if (newDiff == 0) {
bestX = newX;
bestY = newY;
break;
} else if (newDiff < diff) {
bestX = newX;
bestY = newY;
diff = newDiff;
}
}
if (bestX > 0 && bestY > 0) {
return new Point(bestX, bestY);
}
return null;
}
设置适合的放大倍数
当我们对准二维码时候发现,相机离二维码比较远时,预览的二维码比较小;当相机靠近时,预览的二维码比较大。当我们的二维码过小时,发现条码很难扫出来。另外测试发现每个手机的放大倍数不是都是相同的,这可能与各个手机的信号相关。如果直接设置为一个固定值,这可能会在某些手机上过度放大,某些手机上放大的倍数不够。索性相机的参数设定里给我们提供了最大的放大倍数值,通过取放大倍数值的N分之一作为当前的放大倍数,就完美地解决了手机的适配问题。
private void setZoom(Camera.Parameters parameters) {
String zoomSupportedString = parameters.get("zoom-supported");
if (zoomSupportedString != null && !Boolean.parseBoolean(zoomSupportedString)) {
return;
}
int tenDesiredZoom = 27;
String maxZoomString = parameters.get("max-zoom");
if (maxZoomString != null) {
try {
int tenMaxZoom = (int) (10.0 * Double.parseDouble(maxZoomString));
if (tenDesiredZoom > tenMaxZoom) {
tenDesiredZoom = tenMaxZoom;
}
} catch (NumberFormatException nfe) {
Log.w(TAG, "Bad max-zoom: " + maxZoomString);
}
}
String takingPictureZoomMaxString = parameters.get("taking-picture-zoom-max");
if (takingPictureZoomMaxString != null) {
try {
int tenMaxZoom = Integer.parseInt(takingPictureZoomMaxString);
if (tenDesiredZoom > tenMaxZoom) {
tenDesiredZoom = tenMaxZoom;
}
} catch (NumberFormatException nfe) {
Log.w(TAG, "Bad taking-picture-zoom-max: " + takingPictureZoomMaxString);
}
}
String motZoomValuesString = parameters.get("mot-zoom-values");
if (motZoomValuesString != null) {
tenDesiredZoom = findBestMotZoomValue(motZoomValuesString, tenDesiredZoom);
}
String motZoomStepString = parameters.get("mot-zoom-step");
if (motZoomStepString != null) {
try {
double motZoomStep = Double.parseDouble(motZoomStepString.trim());
int tenZoomStep = (int) (10.0 * motZoomStep);
if (tenZoomStep > 1) {
tenDesiredZoom -= tenDesiredZoom % tenZoomStep;
}
} catch (NumberFormatException nfe) {
// continue
}
}
// Set zoom. This helps encourage the user to pull back.
// Some devices like the Behold have a zoom parameter
if (maxZoomString != null || motZoomValuesString != null) {
parameters.set("zoom", String.valueOf(tenDesiredZoom / 10.0));
}
// Most devices, like the Hero, appear to expose this zoom parameter.
// It takes on values like "27" which appears to mean 2.7x zoom
if (takingPictureZoomMaxString != null) {
parameters.set("taking-picture-zoom", tenDesiredZoom);
}
}
除了设置一定比例的放大倍数之外,还有一种辅助的做法是根据二维码的大小自动拉近摄像头。微信就是这么干的:当发现二维码距离比较远的时候自动拉近摄像头,也就是加大放大倍数。建议的做大:二维码在扫描框中的宽度小于扫描框的 1/4,放大最大倍数的 1/4 镜头:
// 二维码在扫描框中的宽度小于扫描框的 1/4,放大镜头
final int maxZoom = parameters.getMaxZoom();
final int zoomStep = maxZoom / 4;
final int zoom = parameters.getZoom();
post(new Runnable() {
@Override
public void run() {
startAutoZoom(zoom, Math.min(zoom + zoomStep, maxZoom), result);
}
});
合理的对焦策略
ZXing 默认的聚焦间隔时间是2000毫秒。扫码是在每一次调用相机聚焦完成后触发回调取图解析的。在这里缩短聚焦时间会提高解析频率,扫码性能自然就提升了。这里建议采用连续对焦模式提升解析频率。
/**
* 连续对焦
*/
private void startContinuousAutoFocus() {
try {
Camera.Parameters parameters = mCamera.getParameters();
// 连续对焦
parameters.setFocusMode(Camera.Parameters.FOCUS_MODE_CONTINUOUS_PICTURE);
mCamera.setParameters(parameters);
// 要实现连续的自动对焦,这一句必须加上
mCamera.cancelAutoFocus();
} catch (Exception e) {
HDQRCodeUtil.e("连续对焦失败");
}
}
除了对焦模式,对焦策略也是非常重要。要辅助选择触摸区域对焦,双指缩放对焦倍数,Android 4.0 以后设置合适的对焦区域和测光区域来优化识别效率。
private void handleFocusMetering(float originFocusCenterX, float originFocusCenterY, int originFocusWidth, int originFocusHeight) {
try {
boolean isNeedUpdate = false;
Camera.Parameters focusMeteringParameters = mCamera.getParameters();
Camera.Size size = focusMeteringParameters.getPreviewSize();
if (focusMeteringParameters.getMaxNumFocusAreas() > 0) {//支持设置对焦区域
isNeedUpdate = true;
Rect focusRect = HDQRCodeUtil.calculateFocusMeteringArea(1f,
originFocusCenterX, originFocusCenterY,
originFocusWidth, originFocusHeight,
size.width, size.height);
focusMeteringParameters.setFocusAreas(Collections.singletonList(new Camera.Area(focusRect, 1000)));
focusMeteringParameters.setFocusMode(Camera.Parameters.FOCUS_MODE_MACRO);
}
if (focusMeteringParameters.getMaxNumMeteringAreas() > 0) {//支持设置测光区域
isNeedUpdate = true;
Rect meteringRect = HDQRCodeUtil.calculateFocusMeteringArea(1.5f,
originFocusCenterX, originFocusCenterY,
originFocusWidth, originFocusHeight,
size.width, size.height);
focusMeteringParameters.setMeteringAreas(Collections.singletonList(new Camera.Area(meteringRect, 1000)));
}
if (isNeedUpdate) {
mCamera.cancelAutoFocus();
mCamera.setParameters(focusMeteringParameters);
mCamera.autoFocus(new Camera.AutoFocusCallback() {
public void onAutoFocus(boolean success, Camera camera) {
//对焦结果
}
});
}
} catch (Exception e) {//对焦测光失败
e.printStackTrace();
}
}
加大二维码的颜色对比度
二维码识别,如下图,常规二维码为了方便识别选择了两个对比度最大的颜色-黑色与白色,在重新设计二维码的时候要注意二维码颜色和背景颜色保持一定的深浅对比度,注意二维码不能使用白色,白色代表编码 0,黑色代表编码 1,反白之后编码会错误,二维码将不能识别。

二维码原理
接下来讲讲二维码的具体原理,为什么放在后面讲?因为:
二维码原理太复杂了,如果放在前面,我相信你看了几分钟就不想看了。即使你坚持看完了,也是一脸懵逼,想自己实现一下基本是不可能。倒不如先讲完优化部分再讲原理,实操第一嘛~
首先我们要了解一下二维码是什么?二维码又称二维条码,常见的二维码为 QR Code,QR 全称 Quick Response,是一个近几年来移动设备上超流行的一种编码方式,它比传统的 Bar Code 条形码能存更多的信息,也能表示更多的数据类型。如下图:传统条形码在 X 轴上存储信息,二维码则多加了 Y 轴。
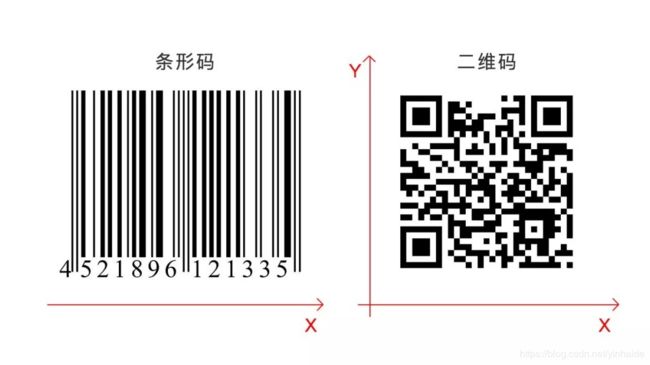
二维码存储数据的方式采用二进制语言,对于电脑程序来说,有 0 和 1 这两个数字就有了一切!在二维码中,白色的方块代表 0,黑色的方块代表 1。

二维码存在 40 种尺寸,在官方文档中,尺寸又被命名为 Version,这个version下面会经常提到,先努力记下来。尺寸与 Version 存在线性关系:Version 1 是 21×21 的矩阵,Version 2 是 25×25 的矩阵,每增加一个 Version,尺寸都会增加 4,故尺寸 Size 与 Version 的线性关系为:
![]()
Version 的最大值是 40,故尺寸最大值是(40-1)*4+21 = 177,即 177 x 177 的矩阵。
二维码结构图
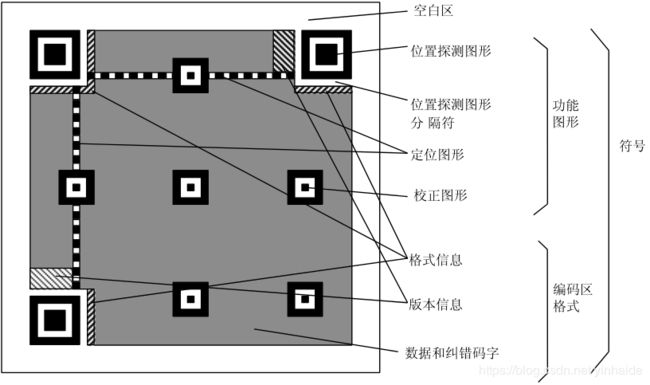
- 空白区
固定不变,用来快速区分周围环境与二维码。 - 位置探测图形
固定不变,用于标记二维码矩形的大小;用三个定位图案即可标识并确定一个二维码矩形的位置和方向了。 - 位置探测图形分隔符
固定不变,用白边框将定位图案与其他区域区分。 - 定位图形
固定不变,用于定位,二维码如果尺寸过大,扫描时容易畸变,定位图形的作用就是防止扫描时畸变的产生。 - 校正图形
由三个黑白相间的小正方形嵌套组成一个大的正方形,仅在版本Version>=2的情况下存在(version=1没有),而且不同版本的个数不一样。作用是便于确定中心,纠正扭曲。 - 格式信息
形状位置固定,内容变化,用来记录使用的掩码和纠错等级。 - 板信息
形状位置固定,内容变化,仅在版本Version>=7的情况下存在,需要预留两块 3×6 的区域记录具体的版本信息,版本6以及以下全为0。 - 数据和纠错码字
剩下的区域,用来保存二维码信息和纠错码字(用于修正二维码损坏带来的错误)。
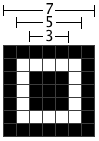
位置探测图形
定位图案与尺寸大小无关,一定是一个 7×7 的矩阵。
定位图形
对齐图案与尺寸大小无关,一定是一个 5×5 的矩阵。

定位图形的个数和位置规则按下表摆放(只列举version<=25部分)。其中第一列对应Version版本号,第二列表示最终得到的定位图的个数,第三列表示所列举的数字进行两两组合(包含自身)形成的坐标点就是定位图标的中心坐标点,不包括已经定义好的功能的位置点。
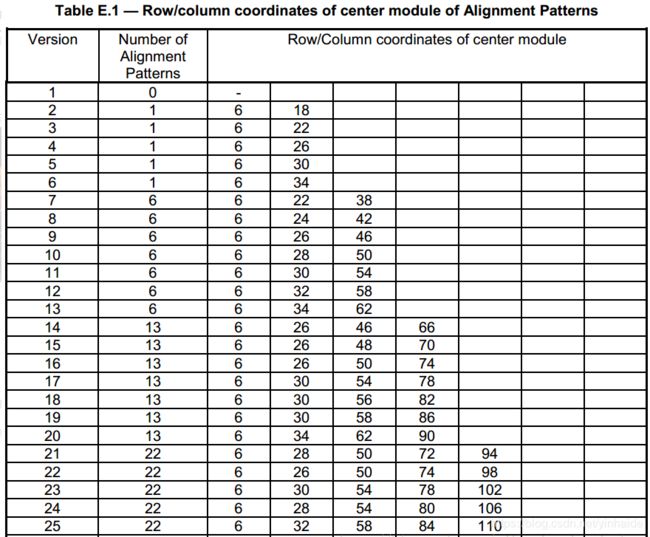
下面针对上述表格中 Version 8 的一个例子。对于 Version 8 的二维码,行列值在 6, 24, 42 两辆组合得到坐标:(6,6)、(6,24)、(6,42)、(24,6)、(24,24)、(24,42)、(42,6)、(42,24)、(42,42)
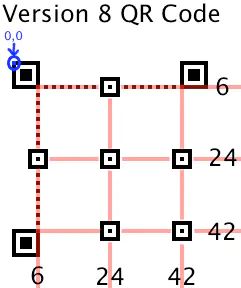
本来存在3*3=9种情况,但是黄色部分的坐标与位置探测图形的坐标重合,不算,剩下6个,如上图所示。
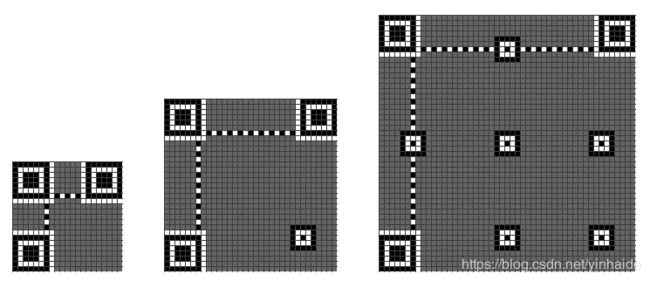
校正图形
校正图形,是两条黑白相间的连接三个定位图案的线。如下图所示。
格式信息
格式信息在定位图案周围分布,由于定位图案个数固定为 3 个,且大小固定,故格式信息也是一个固定 15bits 的信息。

每个 bit 的位置如下图(注:图中的 Dark Module 是固定不变的)。

15bits 中数据,按照 5bits 的数据位 + 10bits 纠错位的顺序排列。但是,最终的15bits数据并不是简单的数据位+接错位,为了减少扫描后图像识别的困难,最后还需要将 15bits 的数据 与 101010000010010 做异或 XOR 操作。因为我们在原格式信息中可能存在太多的 0 值(如纠错级别为 00,蒙版 Mask 为 000),使得格式信息全部为白色,这将增加分析图像的困难。
5bits 的数据位
数据位占 5bits:其中 2bits 用于表示使用的纠错等级 (Error Correction Level),3bits 用于表示使用的蒙版 (Mask) 类别。
- 纠错等级
二维码被遮挡部分或者加入logo也能识别出来,原因就是纠错机制。二维码存在4个级别的纠错等级,纠错级别越高,可以修正的错误就越多,需要的纠错码的数量也变多,相应的可储存的数据就会减少。
| 纠错等级 | 编码 | 纠错水平 |
|---|---|---|
| L | 01 | 7%字码修正 |
| M | 00 | 15%字码修正 |
| Q | 11 | 25%字码修正 |
| H | 10 | 30%字码修正 |
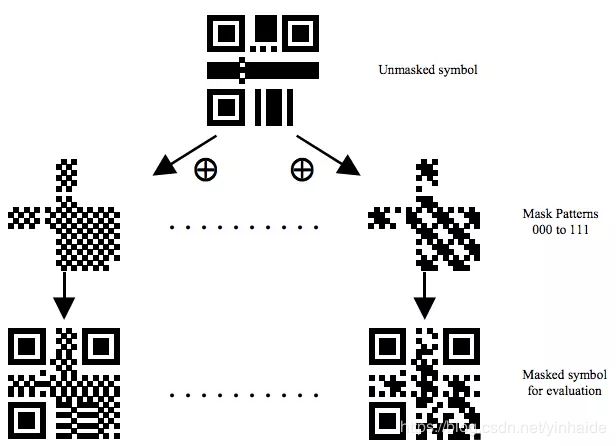
- 蒙版 (Mask)
如果出现大面积的空白或黑块,会造成我们扫描识别的困难。所以,我们还要做Masking操作,QR有8个Mask你可以使用,Mask对应的编码以及算法如下所示。其中,各个mask的公式在各个图下面。所谓mask,就是和上面生成的图做XOR操作。Mask只会和数据区进行XOR,不会影响功能区。

下面是原来比较块状的二维码经过Mask后的一些样子,我们可以看到被某些Mask XOR了的数据变得比较零散了。
10bits 纠错位
上述5bits 的数据位进行 BCH Code(算法介绍) 计算之后生成的10bits纠错码,具体怎么计算这里就不提了。
最后举例子:假设存在纠错等级为 M(对应 00),蒙版图案对应 101,5bits 的数据位为 00101,10bits 的纠错位为 0011011100。生成了在异或操作之前的 bits 序列为:001010011011100 。与 101010000010010 做异或 XOR 操作,即得到最终格式信息:100000011001110。
版本信息
对于 Version 7 及其以上的二维码,需要加入版本信息,如下面蓝色区域。
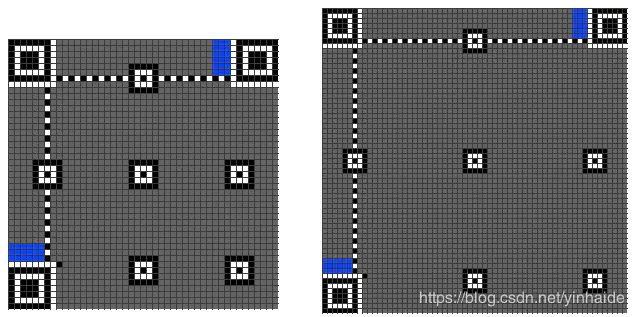
版本信息依附在定位图案周围,故大小固定为 18bits。水平竖直方向的填充方式j以及填充顺序如下图所示。如果再版本6以及以下,这个区域全为0。18bits 的版本信息中,前 6bits 为版本号 (Version Number),后 12bits 为纠错码 (BCH Bits)。示例如下:
假设存在一个 Version 为 7 的二维码(对应 6bits 版本号为 000111),其纠错码为 110010010100,则版本信息图案中的应填充的数据为:000111110010010100。
数据码和纠错码
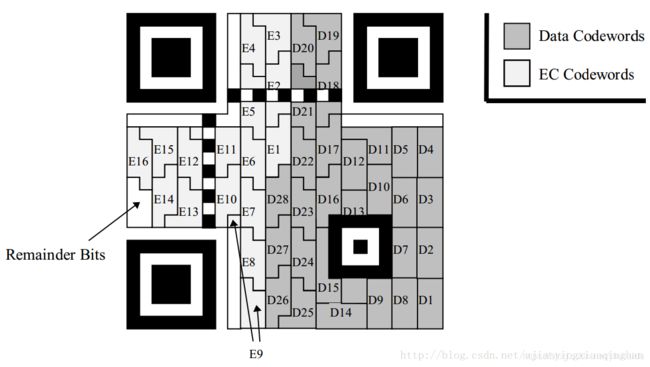
填充数据码和纠错码的思想如下图二维码所示( 以Version 3实例 ),从二维码的右下角开始,沿着红线进行填充,遇到非数据区域,则绕开或跳过。

然而这样难以理解,我们可以将其分为许多小模块,每八个方格组成一个小块,然后将许多小模块串连在一起,如下图所示。灰色的D区域表示的是数据区存放的区域,白色的E区域表示的是纠错码数据存放区域。最后还有部分空白的剩余位,如下图的Remainder Bits。
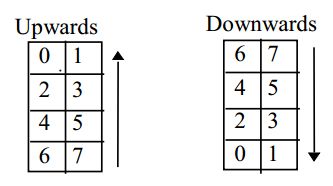
小模块可以分为常规模块和非常规模块,每个模块的容量都为 8。常规情况下,小模块都为宽度为 2 的竖直小矩阵,按照方向将 8bits 的码字填充在内。非常规情况下,模块会产生变形。
填充方式上图 6.14,图中深色区域(如 D1 区域)填充数据码,白色区域(如 E15 区域)填充纠错码。遍历顺序依旧从最右下角的 D1 区域开始,按照蛇形方向(D1→D2→…→D28→E1→E2→…→E16→剩余码)进行小模块的填充,并从右向左交替着上下移动。其中每个小模块的填充规则稍微有些繁琐复杂,因为模块形状各种各样都有。下面举个规则模块的填充顺序,其他的这里不做介绍(下图分别对应D1、D8两块):
那么,数据区和纠错码的数据是怎么个生成规则呢?
针对不同的数据,QR码设计了不同的数据编码编码方式,我们可以根据数据的种类选择合适的编码方式进行编码。通过编码之后的数据码经过一定的规则生成纠错码,就组成了我们的数据码和纠错码区域的数据。下面我们详细展开说明。
数据码
数据编码的过程将数据字符转换为二进制位流,每8位一个码字,整体构成一个数据的码字序列的过程。
但是数据的格式多种多样,可以是数字、字符、汉字、日语等,要以什么样的编码模式转成二进制位流呢?先看看二维码支持的数据编码模式以及对应的指示符:
| 编码模式 | 指示符 |
|---|---|
| ECI编码 | 0111 |
| 数字编码 | 0001 |
| 字符编码 | 0010 |
| 8位字节编码 | 0100 |
| 日本汉字编码 | 1000 |
| 中文汉字编码 | 1101 |
| 结构链接编码 | 0011 |
| FNCI编码 | 0101(第一位置)1001(第二位置) |
| 终止符(信息结尾) | 0000 |
对于特定的编码模式,并不是说单个数据占的二进制位数就确定了,如果二维码的Version版本不一样,单个数据所占的二进制位数也会有不同。下面我们看看不同Version下编码和位数规则:
| 二维码Version | 数字编码 | 字符编码 | 8位字节编码 | 汉字编码 |
|---|---|---|---|---|
| 1 to 9 | 10 | 9 | 8 | 8 |
| 10 to 26 | 12 | 11 | 16 | 10 |
| 27 to 40 | 14 | 13 | 16 | 12 |
下面我们看看常用的几种数据编码:
- 数字编码
数字编码的范围为 0~9。 对于数字编码,统计需要编码数字的个数是否为 3 的倍数。如果不是 3 的倍数,则剩下的 1 位转成 4bits 、2 位会被转为 7bits,否则每三位数字都会转为 10bits 的二进制结果。分组之后对应的是十进制,最后转成对应的二进制流。最后对数字的个数同样编成上面提到的 10、12、14 bits(参照不同Version下编码和位数规则),再加上头部编码指示符和尾部结束符0000形成最终的编码。
举例子:Version = 1 数据为:01234
1、可分为两组:012和34 分别对应10位二进制和7位二进制的十进制12和34
2、数字编码为:012→0000001100 + 34→0100010 : 0000001100 0100010
3、加上数字个数5对应 10bits 编码为(0000000101):0000000101 0000001100 0100010
4、加上头部编码指示符:0001 0000000101 0100010 0000001100 0100010
5、加上结尾结束符:0001 0000000101 0100010 0000001100 0100010 0000
6、最终编码:01234 → 0001 0000000101 0100010 0000001100 0100010 0000
- 字符编码
包括 0-9,大写的A到Z(没有小写),以及符号$ % * + – . / : 和空格。这些字符会映射成一个字符索引表。字符编码的过程,就是将每两个字符分为一组,然后转成下图的45 进制,再转为 11bits 的二进制结果。对于落单的一个字符,则转为 6bits 的二进制结果。 然后字符个数转成9、11、13 bits 二进制的二进制(参照不同Version下编码和位数规则),再加上头部编码指示符和尾部结束符0000形成最终的编码。
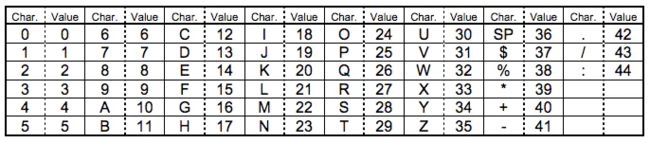
其中的SP是空格,Char是字符,Value是其索引值。
举例子:Version = 1 数据为:AE6
1、可分为两组:AE和6 分别(10, 14) 、 (6)
2、字符编码应将字符组转换为 11bits 的二进制:
- (10, 14):转为 45 进制:10×45+14 = 464;再转为 11bits 的二进制:00111010000
- (6):转为 45 进制:6;再转为 6bits 的二进制:000110
3、加上数字个数3对应 9bits 编码(000000011): 000000011 00111010000 000110
4、加上头部编码指示符:0010 000000011 00111010000 000110
5、加上结尾结束符:0010 000000011 00111010000 000110 0000
6、最终编码为:AE6 → 0010 000000011 00111010000 000110 0000
- 8位字节编码
可以是 0-255 的 ISO-8859-1 字符。有些二维码的扫描器可以自动检测是否是 UTF-8 的编码。
- 其他编码
对于其他编码,用得不多,这里就不展开讲解了。
上面提到的。对于数字01234最终编码为 0001 0000000101 0100010 0000001100 0100010 0000或者字符AE6的编码0010 000000011 00111010000 000110 0000是不是就是最终二维码填充的数据码了?其实不是的,我们最终的数据是以8个为一个数据单元填充,如果编码个数不为8的倍数需要补0;
| 数据 | 编码指示符 | 字符数编码 | 数据编码 | 结束符 | 不足8位补0 |
|---|---|---|---|---|---|
| 01234 | 0001 | 0000 000101 | 01 00010000 00011000 100010 | 00 00 | 000000 |
| AE6 | 0010 | 0000 00011 | 001 11010000 000110 | 00 00 | 000000 |
加了8倍数补位0之后还没完,如果最后还没有达到我们最大的 Bits 数限制,则需要在编码最后加上补齐符(Padding Bytes)。
补齐符内容是不停重复两个字节:11101100 和 00010001。这两个二进制转成十进制,分别为 236 与17。关于每一个Version的每一种纠错级别的最大Bits限制可以参考下图:
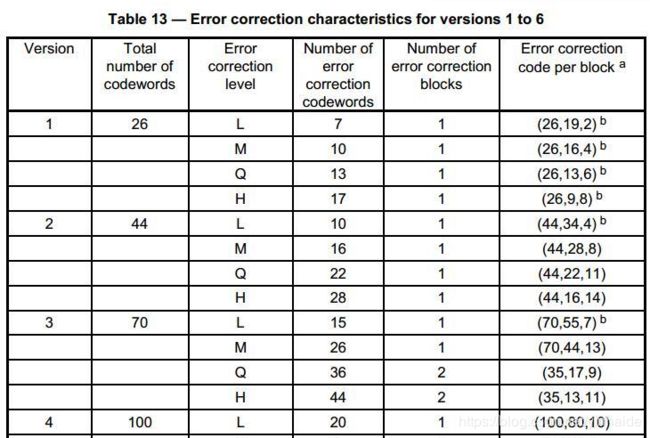
上图中提到的 codewords,可译为码字,一个码字是一个字节,一个字节 8bits。对于 Version,共需要 26 个码字,即 208bits。对于上述部分已经部分编码的数字01234和字符AE6:
| 数据 | 不足8倍补位0之后的编码 | 已用位数 | 还差位数 | 补齐符 |
|---|---|---|---|---|
| 01234 | 00010000 00101010 00100000 0011000 10001000 00000000 | 48 | 160 | 11101100 00010001 x 20 |
| AE6 | 00100000 00011001 11010000 00011000 00000000 | 40 | 168 | 11101100 00010001 x 21 |
最终的数据码(Data Codewords):用于最终填充在二维码D区域的数据
| 数据 | 数据码(Data Codewords) |
|---|---|
| 01234 | 00010000 00101010 00100000 0011000 10001000 00000000 11101100 00010001 … 00010001 11101100 |
| AE6 | 00100000 00011001 11010000 00011000 00000000 11101100 00010001 … 11101100 00010001 |
纠错码
根据前面的分析,我们已经生成了数据码,填充D区域,但是E区域的纠错码又是什么规则生成的呢?纠错码是在数据码的基础上生成的,首先要对数据码进行分组,即分成不同的块(Block)。分组规则参考下图:
加粗样式
主要看两个概念:
- 纠错块个数(Number of error correction blocks):需要划分纠错快的个数
参照表格,大部分是一个数字,比如1表示不同分组,2表示分成两组;还有一种(2 2)的,表示分成两组,每一组分成两块。 - 纠错块码字数(Error Correction Code Per Blocks):每个块中的码字个数,即有多少个字节Bytes
表中最下面关于 (c,k,r) 的解释:
c:码字总个数;
k:数据码个数;
r:纠错码容量
c,k,r的关系公式:c = k+2×r。但是对于标号b区的数据,存在c > k+2×r,属于特殊情况。
纠错码的生成:
纠错码主要是通过里德-所罗门纠错算法(Reed-Solomon Error Correction)实现,这里就不展开讲了
对于只有一个分组:
单个分组采用顺序放置的方式
紧接着上面的两个数据01234和AE6,假如他们的纠错等级都为L,那么他们的纠错码个数都为7,数据码格式为19,因为只有一个分组,所以只需要将这19+7=26个新数据按着顺序放在二维码中即可。
当存在多个分组的情况下:
比如Version 5 + H 纠错等级,参照表格包含着两行两列的四个块,最终的数据将采用穿插放置的规则。
具体示例如下表所示,且由于使用二进制会使得表格过大,故转为范围在 0~255 的十进制。其中组 1 的每个块,都有 11 个数据码, 22 个纠错码;组 2 的每个块,都有 12 个数据码,22 个纠错码。
| 组号 | 块号 | 数据 | 每个块的纠错码 |
|---|---|---|---|
| 1 | 1-1 | 67 85 70 134 87 38 85 194 119 50 6 | 199 11 45 115 247 241 223 229 248 154 117 236 38 6 50 17 7 236 213 87 148 235 |
| 1 | 1-2 | 66 7 118 134 242 7 38 86 22 198 199 | 177 212 76 133 75 242 238 76 195 230 189 106 248 134 76 40 154 27 195 255 117 129 |
| 2 | 2-1 | 247 119 50 7 118 134 87 38 82 6 134 151 | 96 60 202 182 124 157 200 134 27 129 209 182 70 85 246 230 247 70 66 247 118 134 |
| 2 | 2-2 | 194 6 151 50 16 236 17 236 17 236 17 236 | 173 24 147 59 33 106 40 255 172 82 2 157 242 33 229 200 238 106 248 134 76 40 |
提取每一列数据:
第一列:67, 66, 247, 194;
第二列:85, 7, 119, 6;
……
第十一列:6, 199, 134, 17;
第十二列:151, 236;
将上述十二列的数据拼在一起:67, 66, 247, 194, 85, 7, 119, 6,…, 6, 199, 134, 17, 151, 236。
最终的数据码:67, 66, 247, 194, 85, 7, 119, 6,…, 6, 199, 134, 17, 151, 236
同样的方法,将 22 列纠错码放在一起:199, 177, 96, 173, 11, 212, 60, 24, …, 148, 117, 118, 76, 235, 129, 134, 40。
最终的纠错码:199, 177, 96, 173, 11, 212, 60, 24, …, 148, 117, 118, 76, 235, 129, 134, 40
最后将数据码放在D区域,纠错码放在E区域,生成最终的二维码了。
二维码绘制过程
二维码的原理讲完了,不知道看完理解多少。就我个人而言,即使可以看懂,但是想自己实现,那太复杂了,要考虑的维度太多,各种情况都要兼容进来的话难度可想而知。下面最后看看二维码的绘制流程吧。
- 首先在二维码的三个角上绘制位置探测图形。定位图案与尺寸大小无关,一定是一个 7×7 的矩阵。

- 然后绘制定位图形。定位图形与尺寸大小无关,一定是一个 5×5 的矩阵。

- 接着绘制校正图形:两条颜色相间连接三个定位图案的线。

- 接着绘制格式信息图形:格式信息在定位图案周围分布,由于定位图案个数固定为 3 个,且大小固定。

- 接着绘制版本信息图形:依附在定位图案周围,故大小固定为 18bits。

- 接着填充数据码与纠错码:将数据码和操作码的二进制流按着从右下角到左下角的顺序依次填充,1表示填充,0表示空白。

- 最后蒙版操作:如果出现了大面积的空白或黑块,扫描识别会十分困难,所以最后要对整个图像与蒙版进行蒙版操作(Masking),蒙版操作即为异或 XOR 操作。

当讲完前面的原理之后,回头看绘制的过程反而显得没那么难懂了,会有一种豁然开朗的感觉。但是如果还是不懂的话可以多看一遍,笔者相信这篇文章已经讲得非常清楚透彻了~