利用SQL求中位数(已修复BUG)
引言
看《SQL进阶教程》,看到用 HAVING 子句进行自连接:求中位数 这一节时对于给出的SQL不是很理解。因此花了一些时间分析了一下。体会贴在此博文中。
HAVING 子句进行自连接:求中位数
中位数是指将集合中的元素按照升序排序后恰好位于正中间的元素。如果元素个数是偶数,则取中间两个元素的平均值作为中位数。
那么如何利用SQL求中位数呢?
将集合的元素按照大小分为上半部分和下半部分两个子集,同时让着两个子集共同拥有集合正中间的元素。这样共同部分的元素均值就是中位数:

对应的建表语句如下:
CREATE TABLE Graduates
(name VARCHAR(16) PRIMARY KEY,
income INTEGER NOT NULL);
INSERT INTO Graduates VALUES('桑普森', 400000);
INSERT INTO Graduates VALUES('迈克', 30000);
INSERT INTO Graduates VALUES('怀特', 20000);
INSERT INTO Graduates VALUES('阿诺德', 20000);
INSERT INTO Graduates VALUES('史密斯', 20000);
INSERT INTO Graduates VALUES('劳伦斯', 15000);
INSERT INTO Graduates VALUES('哈德逊', 15000);
INSERT INTO Graduates VALUES('肯特', 10000);
INSERT INTO Graduates VALUES('贝克', 10000);
INSERT INTO Graduates VALUES('斯科特', 10000);
原文给出的求中位数的SQL为:
SELECT AVG (DISTINCT income)
FROM (SELECT t1.income FROM Graduates t1,Graduates t2
GROUP BY t1.income
--s1 的条件
HAVING SUM(CASE WHEN t2.income >= t1.income THEN 1 ELSE 0 END)
>= COUNT(*) / 2.0
--s2的条件
AND SUM(CASE WHEN t2.income <= t1.income THEN 1 ELSE 0 END)
>= COUNT(*) / 2.0) TMP;
这条SQL语句要注意的是
>= COUNT(*) / 2.0里的等号,这么做的目的是让着两个字节拥有共同部分。如果去掉等号,当元素个数为偶数时,就没有共同的元素了。
原文给出的解释就是上面这么一点。虽然SQL相对简短,但是很难理解。那么只能拆分开来一步一步分析了。
注意在postgre中需要写成
COUNT(*) / 2.0,感谢每天发芽的豆芽指出。
为了分析方便,将数据修改一下,并且删掉一些记录。
INSERT INTO "public"."graduates"("name", "income") VALUES ('桑普森', 40);
INSERT INTO "public"."graduates"("name", "income") VALUES ('迈克', 3);
INSERT INTO "public"."graduates"("name", "income") VALUES ('阿诺德', 2);
INSERT INTO "public"."graduates"("name", "income") VALUES ('史密斯', 2);
INSERT INTO "public"."graduates"("name", "income") VALUES ('劳伦斯', 1);

先看下子查询
(SELECT t1.income FROM Graduates t1,Graduates t2
GROUP BY t1.income
--s1 的条件
HAVING SUM(CASE WHEN t2.income >= t1.income THEN 1 ELSE 0 END)
>= COUNT(*) / 2.0
--s2的条件
AND SUM(CASE WHEN t2.income <= t1.income THEN 1 ELSE 0 END)
>= COUNT(*) / 2.0)
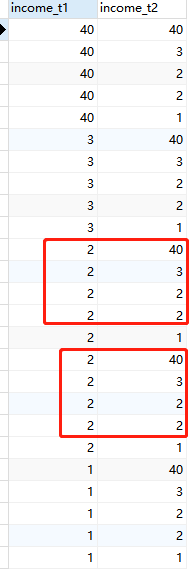
去掉 GROUP BY语句和HAVING得到一个全连接:
SELECT t1.income income_t1,t2.income income_t2 FROM Graduates t1,Graduates t2;
该全连接的结果为:

再将求集合s1的条件抽出来查询:
SELECT t1.income,SUM(CASE WHEN t2.income >= t1.income THEN 1 ELSE 0 END),COUNT(*) FROM Graduates t1,Graduates t2 GROUP BY t1.income
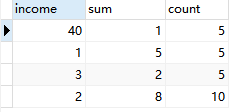
那么这个结果是怎算的呢,其实就是一行中的两两比较(income_t2 >= income_t1),就拿t1.income=2来说:
因此对应t1.income=2满足条件(SUM(CASE WHEN t2.income >= t1.income THEN 1 ELSE 0 END) >= COUNT(*) / 2.0)的有8行。而全连接后共有10行。
满足8 > = (10/2 = 5 )
将上面的SQL进行一下修改:
SELECT t1.income,SUM(CASE WHEN t2.income >= t1.income THEN 1 ELSE 0 END),COUNT(*)/2.0 cnt FROM Graduates t1,Graduates t2 GROUP BY t1.income
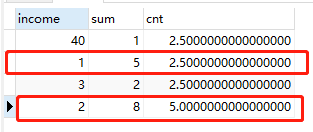
查询结果如上,满足条件的有 { 1 , 2 } \{1,2\} {1,2}
求s2同理:
SELECT t1.income,SUM(CASE WHEN t2.income <= t1.income THEN 1 ELSE 0 END),COUNT(*)/2.0 cnt FROM Graduates t1,Graduates t2
GROUP BY t1.income
--s2的条件
HAVING SUM(CASE WHEN t2.income <= t1.income THEN 1 ELSE 0 END)
>= COUNT(*) / 2.0

得到集合 { 40 , 3 , 2 } \{40,3,2\} {40,3,2}
注意它们求得的上下半的集合+1个,这里交集就是 { 2 } \{2\} {2}
取平均数也是 2 2 2。
SELECT AVG (DISTINCT income)
FROM (SELECT t1.income FROM Graduates t1,Graduates t2
GROUP BY t1.income
--s1 的条件
HAVING SUM(CASE WHEN t2.income >= t1.income THEN 1 ELSE 0 END)
>= COUNT(*) / 2.0
--s2的条件
AND SUM(CASE WHEN t2.income <= t1.income THEN 1 ELSE 0 END)
>= COUNT(*) / 2.0) TMP;
结果:
