集成方法(随机森林)
随机森林是集成方法中优势非常强的一种方法,它以决策树为基础学习器,每棵树独立建立,天然具有并行特性,相对于GradientBoosting和Bagging方法而言,它耗内存更大,速度也相对慢些,但能获得更稳定的结果,尤其是在与CV验证相结合时,泛化能力大大增强。
- 决策树基本算法
- 随机森林算法
- 应用随机森林
1、决策树基本算法
(1)寻找最优化分节点的办法有信息增益量和GINI系数:
①信息增益量:
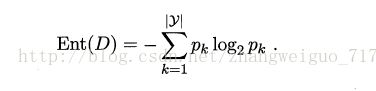
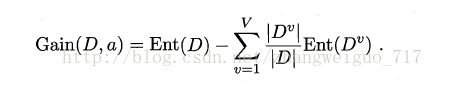
ENt表示原始样本的熵,熵越大,样本越混乱,Gain为加入但变量a之后的信息增益,记加入此特征之后熵降低的数量,Gain越大,越容易作为决策树的划分节点,有时根据需要会在排名前k个节点中选取合适,并非是最优的那一个节点。
②GINI系数


GINI的含义,大概可以表示成这个意思,随机从特征a相同的样本里选取两个样本,他们两个表现不同的概率,概率越低,说明此特征越好,越具有划分度。
(2)树自由生长,会长成没一个叶节点长最多有一个样本,会造成过拟合的现象,在训练集中效果很好,测试集中表现欠佳,这时需要进行剪枝处理,可以通过设定树的深度、叶节点的最小样本数来控制,增强泛化能力。
2、随机森林
多棵决策树,他们随机在选取样本、特征,各自野蛮生长,最后再对他们的结果进行组合,

随机森林算法来源于Bagging算法,但他的表现往往由于Bagging,随着森林中树的数目增多,它的泛化能力会逐渐增强,其效果比单棵决策树要优势太多。
3、实验
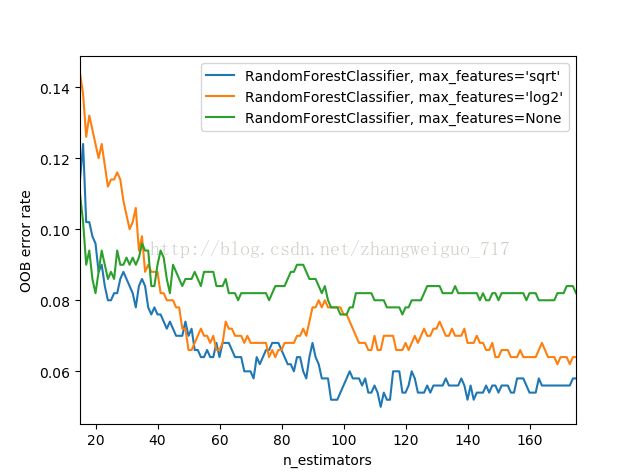
使用Python中sklearn模块,生成分类数据集,并用随机森林随机选取不同数目的特征进行融合,构建随机森林分类器。
import matplotlib.pyplot as plt
from collections import OrderedDict
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier
# Author: Kian Ho
# Gilles Louppe
# Andreas Mueller
#
# License: BSD 3 Clause
print(__doc__)
RANDOM_STATE = 123
# Generate a binary classification dataset.
X, y = make_classification(n_samples=500, n_features=25,
n_clusters_per_class=1, n_informative=15,
random_state=RANDOM_STATE)
# NOTE: Setting the `warm_start` construction parameter to `True` disables
# support for parallelized ensembles but is necessary for tracking the OOB
# error trajectory during training.
ensemble_clfs = [
("RandomForestClassifier, max_features='sqrt'",
RandomForestClassifier(warm_start=True, oob_score=True,
max_features="sqrt",
random_state=RANDOM_STATE)),
("RandomForestClassifier, max_features='log2'",
RandomForestClassifier(warm_start=True, max_features='log2',
oob_score=True,
random_state=RANDOM_STATE)),
("RandomForestClassifier, max_features=None",
RandomForestClassifier(warm_start=True, max_features=None,
oob_score=True,
random_state=RANDOM_STATE))
]
# Map a classifier name to a list of (, ) pairs.
error_rate = OrderedDict((label, []) for label, _ in ensemble_clfs)
# Range of `n_estimators` values to explore.
min_estimators = 15
max_estimators = 175
for label, clf in ensemble_clfs:
for i in range(min_estimators, max_estimators + 1):
clf.set_params(n_estimators=i)
clf.fit(X, y)
# Record the OOB error for each `n_estimators=i` setting.
oob_error = 1 - clf.oob_score_
error_rate[label].append((i, oob_error))
# Generate the "OOB error rate" vs. "n_estimators" plot.
for label, clf_err in error_rate.items():
xs, ys = zip(*clf_err)
plt.plot(xs, ys, label=label)
plt.xlim(min_estimators, max_estimators)
plt.xlabel("n_estimators")
plt.ylabel("OOB error rate")
plt.legend(loc="upper right")
plt.show()