存储系统性能 - 带宽计算
你是否曾经有这样的疑问:
某存储系统的最大吞吐量(IOPS)是多少?
某存储系统的最大带宽(MB/s)是多少?
IOPS和带宽的计算与I/O大小、随机/顺序、读写比率、应用程序的线程模型、对响应时间的要求等诸多因素相关,这些因素的组合称之为【I/O profile】。不同的I/O Profile下对系统所做的测试将得到不一样的结果,通常我们看到的【标称IOPS】都是在某一个固定组合下测得的,拿到生产环境中,未必能达到标称值,这也是为什么在做设计解决方案时需要做性能分析、估量(sizing)的缘故。
某存储系统的最大吞吐量(IOPS)是多少?
某存储系统的最大带宽(MB/s)是多少?
IOPS和带宽的计算与I/O大小、随机/顺序、读写比率、应用程序的线程模型、对响应时间的要求等诸多因素相关,这些因素的组合称之为【I/O profile】。不同的I/O Profile下对系统所做的测试将得到不一样的结果,通常我们看到的【标称IOPS】都是在某一个固定组合下测得的,拿到生产环境中,未必能达到标称值,这也是为什么在做设计解决方案时需要做性能分析、估量(sizing)的缘故。
硬件性能极限就摆在那,公式:带宽 = 频率 * 位宽。在读文章之前,建议先看一下如下计算公式和名词。
计算公式:
- Real-world result = nominal * 70% -> 我所标称的数据都是乘了70%,尽可能接近实际数据。
- 带宽 = 频率 * 位宽
- QPI带宽:假设QPI频率==2.8 Ghz
× 2 bits/Hz (double data rate)
× 20 (QPI link width)
× (64/80) (data bits/flit bits)
× 2 (unidirectional send and receive operating simultaneously)
÷ 8 (bits/byte)
= 22.4 GB/s
术语:
- Westmere -> Intel CPU微架构的名称
- GB/s -> 每秒传输的字节数量
- Gb/s -> 每秒传输的比特数量
- GHz -> 依据具体操作而言,可以是单位时间内运算的次数,单位时间内传输的次数 (GT/s)
- 1-byte = 8-bits
- IOH -> I/O Hub,处于传统北桥的位置,是一个桥接芯片。
- QPI -> QuickPath Interconnect,Intel前端总线(FSB)的替代者,可以认为是AMD Hypertransport的竞争对手
- MCH -> Memory Controller Hub,内置于CPU中的内存控制器,与内存直接通信
- PCI Express(Peripheral Component Inteconnect Express, PCIe) - 一种计算机扩展总线(Expansion bus),允许外围设备与计算机系统内部硬件(包括CPU和RAM)之间的数据传输。
- Overprovisioning - 比如 48*1Gbps access port交换机,通常只有4*1Gbps uplink,那么overprovisioning比 = 12:1
- PCI-E 2.0每条lane的理论带宽是500MB/s
- X58 – 相当于传统的北桥,只不过不再带有内存控制器,Code name = Tylersburg
- Ultrapoint - VNX/CLARiiON后端LCC(link control card)的交换拓扑,实现在一个DAE内点到点的链接,而非FCAL总线结构
- Ultraflex - EMC I/O模块(SLIC)的
- Interconnect - PCIe设备通过一条逻辑连接(interconnect)进行通信,该连接也称为Link。两个PCIe设备之间的link是一条点到点的通道,用于收发PCI请求。从物理层面看,一个link由一条或多条Lane组成。低速设备使用single-lane link,高速设备使用更宽的16-lane link。
- Lane - 一条lane由一对发送/接收差分线(differential line)组成,共4根线,全双工双向字节传输。一个PCIe slot可以有1-32条lane,以x前缀标识,通常最大是x16。
相关术语:
- address/data/control line
- 资源共享 ->资源仲裁
- 时钟方案(Clock Scheme)
- Serial Bus
PCI-E Capacity:
Per lane (each direction):
- v1.x: 250 MB/s (2.5 GT/s)
- v2.x: 500 MB/s (5 GT/s)
- v3.0: 1 GB/s (8 GT/s)
- v4.0: 2 GB/s (16 GT/s)
16 lane slot (each direction):
- v1.x: 4 GB/s (40 GT/s)
- v2.x: 8 GB/s (80 GT/s)
- v3.0: 16 GB/s (128 GT/s)
性能是【端到端】的,中间任何一个组件都有其性能极限,它并不像一根均匀水管,端到端性能一致。存储系统由各个子系统组成,每个子系统有其自身固有的性能瓶颈 。我将以一种双控制器、SAS后端、x86架构的中端存储系统为例,为了方便名称引用,我们称其为myStorage。
控制器上可以让我们算一算的无非是CPU、内存、I/O模块,不过我会带上一些极为重要但却会忽略的组件。先上一张极为简化的计算机系统构成图,许多中端存储控制器就是如此。

CPU - 假设控制器采用Intel Xeon-5600系列处理器(Westmere Microarchiecture ),支持DDR3-1333。CPU带宽 = 2.8GHz x 64bits / 8 =
22.4 GB/s。
内存 – myStorage通过DMA (Direct Memory Access) 直接在前端I/O模块(用于连接主机,可以是iSCSI、FC、SAS)、内存以及后端I/O模块之间传输数据。因此需要知道内存是否提供了足够的带宽。3 x DDR3,1333MHz带宽==
29GB/s(通常内存带宽都是足够的),那么位宽应该是64bits。Westmere集成了内存控制器,极大降低了CPU与内存的通信延迟。myStorage采用(X58 IOH)替代了原始的北桥芯片,X58 芯片组提供 36条 PCIe2.0 lane,带宽 =
17.578GB/s (之后会有更多解释)。
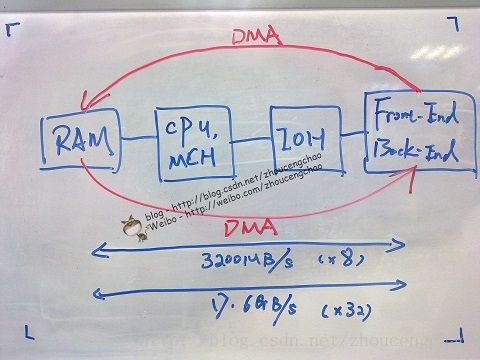
I/O模块 (SLIC)- 一个SLIC所能提供的带宽并不等于其所有端口带宽之和,还要看控制芯片和总线带宽。以SAS SLIC为例,一个SAS SLIC可能由两个SAS控制器组成,假设每个SAS控制器实际带宽大约
2200MB/s,一个SAS端口 = 4 * 6Gbps /8 * 70% =
2100MB/s;一个SAS控制器控制2 x SAS端口,可见单个SAS控制器无法处理两个同时满负荷运转的SAS端口(2200MB/s < 4200MB/s),这里SAS控制器是瓶颈 ->
Overprovisioning!整个SAS SLIC又是通过【x8 PCI-E 2.0】 外围总线与【IOH】连接。x8 PCIe 贷款 = 8 * 500MB/s * 70% = 2800MB/s。如果两个SAS控制器满负荷运作的话,即
4400MB/s >
2800MB/s,此时x8 PCIe总线是个瓶颈 ->
Overprovisioning!

其实还可以计算后端磁盘的总带宽。假设myStorage系统一根后端Bus最多能连250块盘,一块SAS 15K RPM硬盘提供大约12MB/s的带宽(非顺序随机64KB,读写未知),12 * 250 = 3000MB/s > 2100MB/s ->
Overprovisioning!
备注
:一个SAS控制器控制两个SAS端口,错开连接端口可分别利用到两个SAS控制器,做到负载均衡。
同理,对任何类型的SLIC,只要能够获得其端口速率、控制器带宽、PCIe带宽,即可知道瓶颈的位置。值得注意的是,前端入站I/O量(来自主机)很大时,后端能否顶住。
PCI-Express – PCIe是著名的外围设备总线,用于连接高带宽设备与CPU通信,比如存储系统的I/O模块。X58提供了36 lane PCIe 2.0,因此带宽 = 36 x 500MB/s / 1024MB =
17.578125GB/s。
QPI & IOH – QPI通道带宽可以通过计算公式获得,我从手中资料直接获得的结果是19-24GB/s(运行在不同频率下的值)。IOH芯片总线频率是
12.8GB/s (List of Intel chipsets这里获得,但不确定总线频率是否就是指IOH本身的运行频率)< 17.578GB/s(36 Lane) ->
Overprovisioning!
算完了,能回答myStorage系统最大能提供多少带宽了吗?看下来CPU、内存、QPI的带宽都上20GB/s,留给前后端的PCIe总线总共也只有18GB/s不到,即便这样也已经过载了IOH(12GB/s)。所以看来整个系统的瓶颈在IOH,只有12GB/s。下图有点旧了,我把PCIe 36 Lane框成了MAX Bandwidth,因为那个时候以为IOH应该有足够的带宽,但后来发现可能不是这样,但图已经被我擦了。。。
 。
。
。

怎么算带宽并不是重点(我自己也是摸瞎),重要的在于让你看到一些I/O路径上容易被忽略的子系统。我们通常只会从存储的CPU、I/O模块、磁盘来算性能极限。但却忽略了整个系统中的其它部分,例如IOH、QPI、MCH、PCI-E,必须对完全的I/O路径进行分析。
- EMC中文技术社区
- List of Intel chipsets
- Intel QuickPath Interconnect
- Direct Media Interface
- List of Intel Xeon microprocessors
- Westmere (microarchitecture)
- Intel Tick-Tock
- Intel® QuickPath Architecture
- Unified Storage性能官方文档
- Direct Memory Access
Related info:
(1) Bus
(2) Northbridge
(3) Intel Clarkdale平台国内首测
(4) 见证"芯"路 30年CPU架构发展史(一)