实战 |利用机器学习实现一个多分类任务
对于机器学习而言,如果你已经大致了解了相关算法的原理、理论推导,你也不是大家口中刚入门的小白了。接下来你需要将自己所学的知识利用起来,最好的方式应该就是独立完成几个项目实战,项目难度入门级即可,因为重点是帮助你了解一个项目的流程,比如缺失值和异常值的处理、特征降维、变量转换等等。
Kaggle毋庸置疑是一个很好的平台,里面的泰坦尼克号、房屋价格预测、手写数字都是非常非常经典的入门实战项目,如果你独立完成这三个项目后感觉可以提升一下难度,就可以继续在Playground中寻找适合自己的项目。但如果你感觉还需要几个简单的项目巩固一下,这里给大家安利一下SofaSofa竞赛平台。

专业程度虽然不及Kaggle,但练习赛中十个简单项目用来练手还是不错的,种类也是非常全的,包括分类、回归预测、自然语言处理、图像识别等等,本文在练习赛【8】——地震后建筑修复建议的基础上实现。
了解数据集
首先一定要做的是了解数据集,因为大多数据集的特征名都是以英文或者以英文简写搭配命名,只有真正了解一个特征的意义,才能更好地分析该特征与标签变量之前存在的关系。SofaSofa在每个比赛中都会有一个表格,给出所有变量对应的解释。
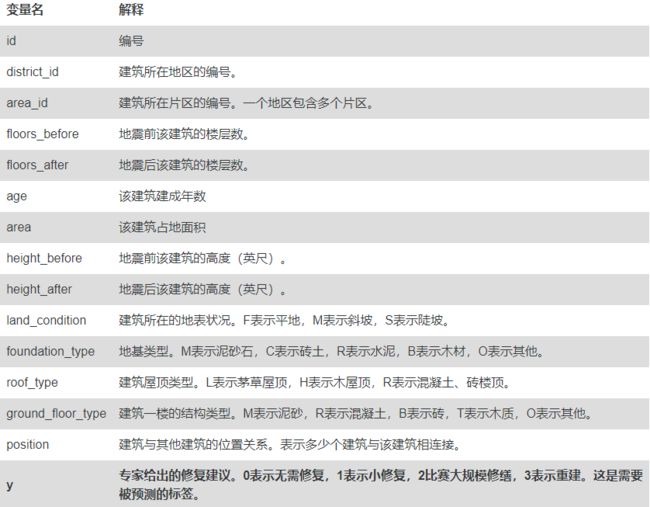
可以看到这个数据集的特征并不是很多,但训练集共有65万个样本,我们都知道数据多对于建模是有好处的,因为数据越多覆盖面就越广,会提高模型的准确率,当然这可能会牺牲一些内存和计算时间。标签变量y,共有四种可能取值,说明这是一个多元分类问题。
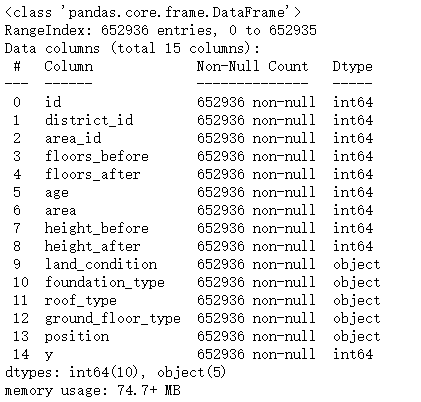
没有缺失值是不错的消息,除标签变量y之外,共有9个数值型比变量和5个类别型变量。
可视化分析
可视化分析一方面是帮助我们找出样本中的异常点和离群点,一方面也是帮助分析特征与标签变量之间的关系。但上面提及了这个训练集足足有65万条数据,如果同时利用所有样本绘制图像,图像可能会被样本点填满,很难从中得出有用的信息。
所以这里可以选择随机抽样的方式,每次抽取1000-2000个样本绘制图像进行分析,可以多抽取几次,防止数据的偶然性。这里选择用散点图可视化数值型特征,用area和age为例。
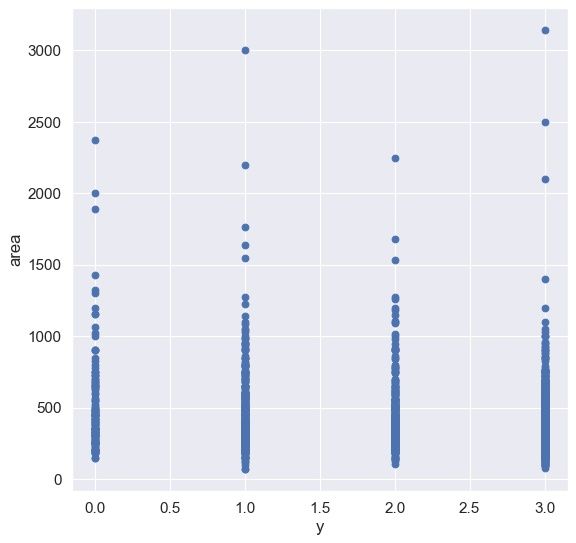
area特征中有一些数值偏大,但不能说其是异常点,因为一些大型建筑物占地面积3000不是不可能的,但2000个样本,仅有不到20个样本的占地面积大于1500,所以可以将其视为离群点,离群点在建模时是会影响拟合的,所以选择舍去。
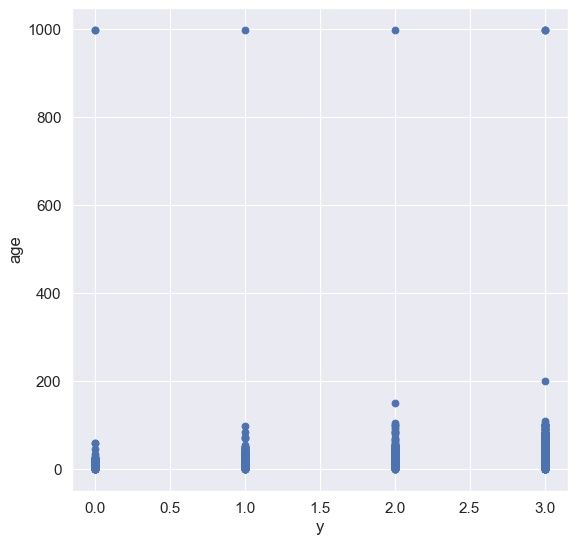
对于建筑物的年限age而言,可视化后会发现有很多样本在age这一特征的数值都为999,中间却有很大的空缺,比如没有一个样本点的age位于500-900之间,所以这类样本被视为异常点,再结合离群点分析,可以选择一个阈值进行过滤。其他数值型特征可以做同样的操作,这里不再过多介绍。
这个数据集还有个奇怪的地方就是有很多样本地震后的楼层、高度都要高于地震发生之前,这显然是不可能发生的,可能是在数据填充时出现了错误,利用布尔索引过滤掉此类特征。
#布尔索引
data1 = data1[data1['floors_before']>=data1['floors_after']]
data1 = data1[data1['height_before']>=data1['height_after']]
data1.reset_index(drop = True)#重置索引
然后利用相关矩阵对所有的数值型特征进行一下相关性分析,通过观察相关性舍去一些没有必要的特征达到降维的目的。
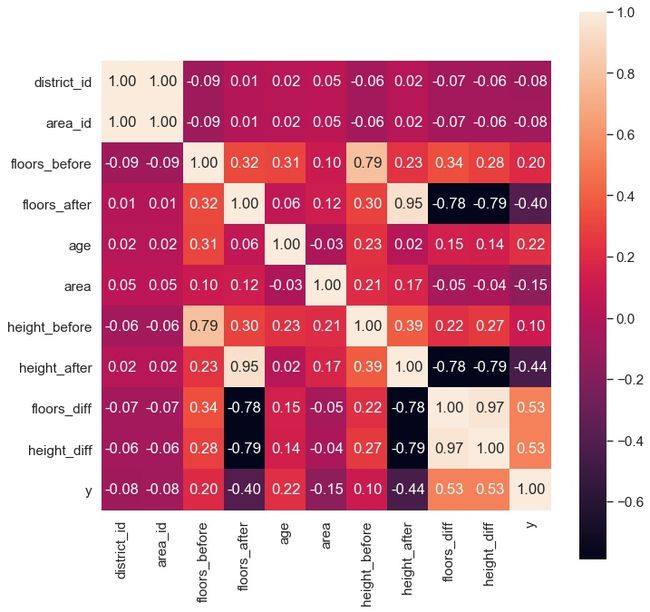
这里"district_id"和"area_id"是完全相关的,可以随便留下一个,或者都删去,因为相关性确实小的可怜;可以看到这里增加了两个新的变量"floors_diff"和"height_diff",就是地震前后的建筑物层数和高度的差值,可以观察一下标签变量"y"和这六个属性的相关性,与地震前的信息相关性极低,也就是说,标签变量很少关注一个建筑物震前的信息,而是着重关注经过地震之后建筑物发生变化的信息。
类别型变量转换
类别型变量不方便后期建模时传入数据,所以我们需要提前将类别型变量转换为算法能识别的数值型,变量转换方式有很多种,比如有序变量、哑变量、虚拟变量。
对于"position"这一特征,可以进行有序变量,由于仅有一个特征,所以没有调用sklearn中的API,而是直接利用自定义函数结合apply函数进行转换。
def pos(e):
if e == "Not attached":
return 0
elif e == "Attached-1 side":
return 1
elif e=="Attached-2 side":
return 2
else:
return 3
data1['position'] = data1['position'].apply(pos)
而剩下的几个类别型变量皆为无序变量,可以将其转化为哑变量,再进一步转化为虚拟变量。相比于sklearn中的API,pandas自带的方法看起来更加简洁。
#哑变量编码
dummy_df = pd.get_dummies(data1.iloc[:,6:10])
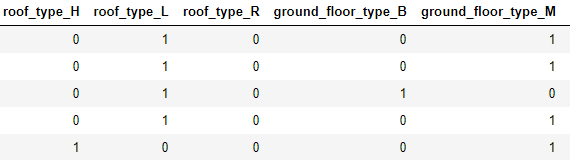
如果你感觉这种方式简单,并没有懂哑变量编码的意思和过程,可以试着了解一下下面这个函数,同样是实现哑变量编码。
def dummy_code(var):
#获取特征中所有变量
var_unique = var.unique()
#新建一个DataFrame
dummy = pd.DataFrame()
#最后一个不设置虚拟变量,可用之前所有变量表示
for val in var_unique:
#利用一个布尔型数组存储编码后的变量
bo = (val==var)
#命名,并将True转为1,False转为0
dummy[var.name+"_"+str(val)] = bo.astype(int)
return dummy
将哑变量进一步转化为虚拟变量合并至数据集中,代码如下:
#每个特征删去一个类别,得到虚拟变量
dummy_df1 = dummy_df.drop(['land_condition_S','foundation_type_O','roof_type_H','ground_floor_type_T'],axis = 1)
#删去原特征,合并虚拟变量
data1 = data1.drop(['land_condition','foundation_type','roof_type','ground_floor_type'],axis = 1)
data1 = pd.concat([data1,dummy_df1],axis = 1)
可能很多伙伴不太了解为什么虚拟变量可以这样转换,虚拟变量与哑变量相比,减少了特征的维度,本质是类似的,以"roof_type"这一特征举例,经过哑变量转换形成三个新特征:[“roof_type_H”,“roof_type_L”,“roof_type_R”],如果在"roof_type"为"R"的样本,在哑变量的表达方式应该是[0,0,1],但是如果从哑变量中删去"roof_type_R"这一特征,表达方式就可以变成[0,0],通过唯一性就可以利用前两个特征推出第三个特征的值,所以减少了不必要的特征以实现降维。
当然这里还可以做一下方差过滤、相关性分析等操作进一步实现特征降维,各位在实操的时候可以自己试一下。
建模工作
前面说过了这个是一个多元分类项目,所以在建模的时候可以有两种选择,一是利用多元分类器,比如随机森林、朴素贝叶斯,二就是利用二元分类器实现多元分类任务,比如逻辑回归、SVM。
后面文章会写一篇关于二元分类器实现多元分类的文章,本文就集中于多元分类器的实现,主要用到的两个分类器是随机森林和LGBM。
一般建模的流程大致是在训练集上切分训练集和测试集,有的数据需要标准化处理,然后训练模型,利用测试集进行预测,获取模型的准确率或其他衡量模型好坏的指标,下面以随机森林分类器模拟一下该流程。
首先进行数据切分,可以选择控制训练集和测试集的比例:
from sklearn.model_selection import train_test_split
features = data2.iloc[:,0:-1].values
label = data2.iloc[:,-1].values
X_train,X_test,y_train,y_test = train_test_split(features,label,test_size = 0.3)
这里介绍一下可以减少代码量的管道流,如果正常来说,我们可能要分别实例化标准化和PCA的API,然后再传入训练集和测试集,这些操作可以利用管道流封装到一起,让代码看起来更加简洁。
from sklearn.ensemble import RandomForestClassifier
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline,Pipeline
#管道流简化工作流
pipe_rf = make_pipeline(StandardScaler(),
PCA(n_components=10),
RandomForestClassifier())
pipe_rf.fit(X_train,y_train)
#得到每个类别的概率
pred_y_rf = pipe_rf.predict_prob(X_test)
利用predict_prob计算出标签变量得到每个类别的概率,然后利用索引排序可以得到概率最大的两个类别:
pred_df = pd.DataFrame(data=pred_y_rf.argsort()[:, -2:][:, ::-1], columns=['y1', 'y2'])
pred_df.to_csv("eq_submission.csv",index=False)
由于数据量比较大,调参比较费时,在没有调参的情况下,随机森林模型的概率大致为68%,LGBM模型的准确率大致为70%,准确率并不是太好,除准确率外还可以通过查全率、查准率、F1-score衡量一下模型的好坏,上文大体上提供了一个建模前及建模的思路而已,伙伴们可以利用自己的思路,再加上调参应该会得到一个不错的模型。
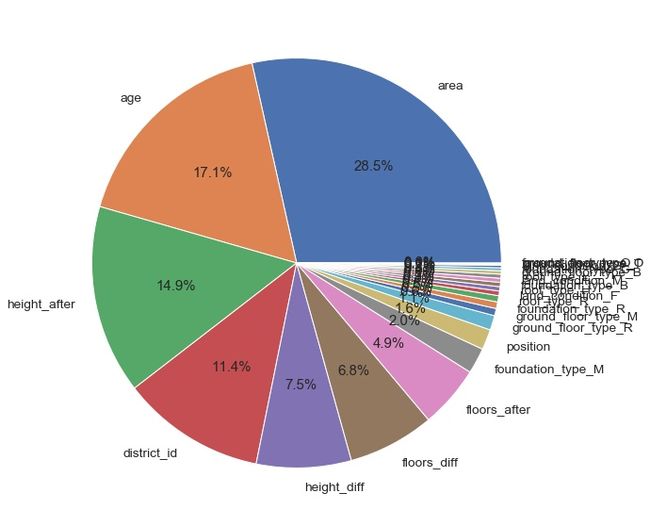
这幅图是关于特征重要度的饼图,可以根据饼图再调节特征,其中area占比是比最大的,然后"distict_id"占比也是不小的,但是上文关系矩阵中与标签变量的相关性又很小,所以分析要相互结合、更加全面一些才好。
说在最后
上面的一系列操作都是为了最后的模型,但如果作为一个竞赛,你需要提交一份文件,而这份文件从何来?竞赛会给出一个不含标签变量的测试集!注意与测试集中分割出的测试集不同。我们同样需要对测试集做一些数据处理,操作和训练集类似,然后将训练出的模型应用在测试集上,会得出最后的结果保存成一个新的csv文件,这就是你最后需要提交的文件啦。
公众号【奶糖猫】后台回复"地震"可获取源码供参考