Java集合框架概述
Java集合框架类图概览
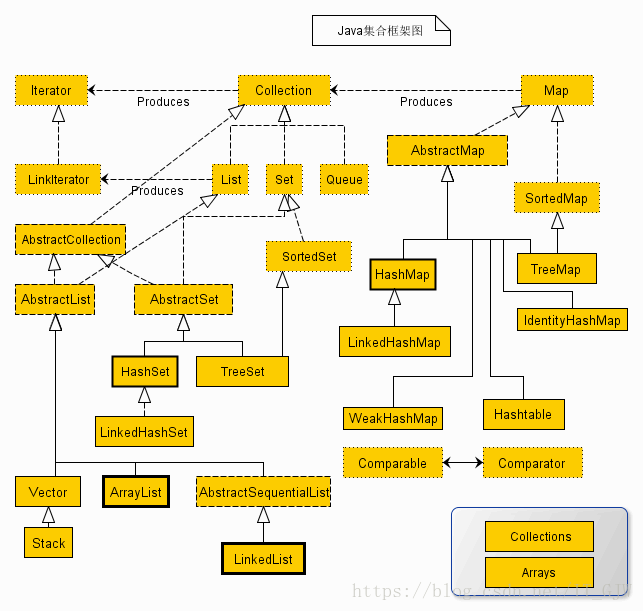
上述类图中,实线边框的是实现类,比如ArrayList,LinkedList,HashMap等,折线边框的是抽象类,比如AbstractCollection,AbstractList,AbstractMap等,而点线边框的是接口,比如Collection,Iterator,List等。
Java集合可以被分为两大类,一类是单列集合,这类集合的根接口是Collection,另一类是双列集合,这类集合的根接口是Map
Collection
Collection接口有3个主要的子接口:List接口、Set接口、Queue接口
一.List集合
List代表一个元素有序、可重复的集合,集合中的每个元素都有其对应的索引。用户可以对集合中的每个元素的插入位置进行精确的控制,同时可以元素的整数索引访问元素。实现List接口的集合主要有:ArrayList、LinkedLidt、Vector、Stack。
- ArrayList是一个动态数组,它的特点是内部元素的随机访问速度快,它是非同步的(线程不安全)
- LinkedList基于双向链表实现,它对元素的随机访问性能差,但是在插入和删除元素时表现出色,它也是非同步的
- Vector和ArrayList类似,但它是同步的(线程安全的),可以说Vector是线程安全的动态数组。
- Stack继承自Vector,它实现了一个后进先出的栈结构

二.Set集合
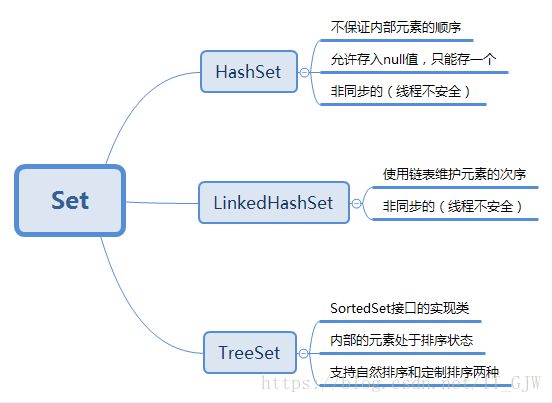
Set集合是一种不允许有重复元素的集合。Set判断元素是否相同的依据是调用元素的equal方法,即如果有e1.equals(e2)==true,那么e1和e2不能同时存在于一个Set集合中。正如其名称所暗示的,此接口模仿了数学上的set抽象。该接口的主要实现类有:HashSet、TreeSet、LinkedHashSet。
1.HashSet
HashSet按hash算法存储集合中的元素,具有很好的存取和查找性能。它不保证元素的顺序(这里的顺序是指:元素的插入顺序和输出顺序不一致),集合中的元素可以是null,但只能存入一个null值。同时它是非同步的(线程不安全)。
HashSet如何保证集合元素的唯一性?
它是通过对象的hashCode和equals方法来完成对象唯一性的,具体如下:
如果对象的hashCode值不同,那么不用判断equals方法,就直接存储到哈希表中。
如果对象的hashCode值相同,那么要再次判断对象的equals方法是否为true。
如果为true,视为相同元素,不存。如果为false,那么视为不同元素,就进行存储。
记住:如果元素要存储到HashSet集合中,必须覆盖hashCode方法和equals方法。
一般情况下,如果定义的类会产生很多对象,比如人,学生,书,通常都需要覆盖equals,hashCode方法。
建立对象判断是否相同的依据。
HashSet的contains方法和remove方法都会依据hashcode和equals方法判断元素是否存在。
2.LinkedHashSet
LinkedHashSet是HashSet的子类。它的特点是使用链表维护了元素的次序,即其内部元素的输出顺序可以与插入顺序保持一致。
3.TreeSet
TreeSet是SortedSet接口的实现类。正如接口所暗示的,TreeSet是一个有序集合,它可以确保集合中的元素处于排序状态。它支持两种排序方式:自然排序和定制排序。它也是非同步的(线程不安全)。
TreeSet对元素进行排序的方式一(自然排序):
让元素自身具备比较功能,元就需要实现Comparable接口。覆盖compareTo方法。
实例如下
public static void main(String[] args) {
TreeSet ts = new TreeSet(new ComparatorByName());
以Person对象年龄进行从小到大的排序,年龄一致的情况下按姓名的字典顺序进行排序
ts.add(new Person("zhangsan",28));
ts.add(new Person("lisi",21));
ts.add(new Person("zhouqi",21));
ts.add(new Person("zhaoliu",25));
ts.add(new Person("wangu",24));
Iterator it = ts.iterator();
while(it.hasNext()){
Person p = (Person)it.next();
System.out.println(p.getName()+":"+p.getAge());
}
}public class Person implements Comparable {
private String name;
private int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String toString(){
return name+":"+age;
}
@Override
public int compareTo(Object o) {
Person p = (Person)o;
int temp = this.age-p.age;
return temp==0?this.name.compareTo(p.name):temp;
}
}排序结果如下

如果对象中不具备自然顺序。怎么办?
可以使用TreeSet集合第二种排序方式二(定制排序):
让集合自身具备比较功能,定义一个类实现Comparator接口,覆盖compare方法。
将该类对象作为参数传递给TreeSet集合的构造函数。
实例如下
创建了一个比较器,该比较器根据person类的name的字典顺序进行排序,在name顺序相同的情况下根据age进行
排序
public class ComparatorByName implements Comparator {
@Override
public int compare(Object o1, Object o2) {
Person p1 = (Person)o1;
Person p2 = (Person)o2;
int temp = p1.getName().compareTo(p2.getName());
return temp==0?p1.getAge()-p2.getAge(): temp;
}
}public static void main(String[] args) {
TreeSet ts = new TreeSet(new ComparatorByName());
ts.add(new Person("zhangsan",28));
ts.add(new Person("lisi",21));
ts.add(new Person("lisi",29));
ts.add(new Person("zhaoliu",25));
ts.add(new Person("wangu",24));
Iterator it = ts.iterator();
while(it.hasNext()){
Person p = (Person)it.next();
System.out.println(p.getName()+":"+p.getAge());
}
}排序结果如下:

TreeSet如何保证集合元素的唯一性?
判断元素唯一性的方式:就是根据比较方法的返回结果是否是0,是0,就是相同元素,不存。
三、Map
与Collection集合不同,Map集合是由一系列键值对组成的集合,它提供了key到value的一对一映射,集合中的key不能重复。它与collection集合的联系是它提供了三种collection视图,允许以键集、值集、键-值映射关系集的形式查看某个映射的内容。Map接口的主要实现类有:HashMap、LinkedHashMap、TreeMap、HashTable。
1.HashMap
以哈希表的数据结构实现,查找对象时通过哈希函数计算其位置,查询速度快。可以使用null作为key或者value。它是非同步的(线程不安全),且不保证映射的顺序。
2.Hashtable
Hashtable与HashMap类似,它是一个古老的Map接口实现类,从JDK1.0便开始提供。与HashMap的不同之处在于,它不允许使用null作为key或者value,同时它是同步的(线程安全的)。
3.LinkedHashMap
LinkedHashMap是HashMap的子类,相比于HashMap,它使用一个链表来维护内部元素的顺序,可以在迭代输出时保证元素的输出顺序与插入顺序一致。由于需要维护元素的插入顺序,因此其性能略低于HashMap。它也是非同步的(线程不安全)。
4.TreeMap
TreeMap是一个有序的key-value集合。它基于红黑树实现,每一个key-value节点作为红黑树的一个节点。它将插入的元素根据key进行排序,排序方式有自然排序和定制排序两种。它也是非同步的(线程不安全)。

参考资料
1.https://www.cnblogs.com/xiaoxi/p/6089984.html
2.https://www.jianshu.com/p/589d58033841
3.HashMap源码分析