HDFS的原理详解
思考两个问题:HDFS文件系统的虚拟目录
分布式文件系统的命名空间
1.组成:
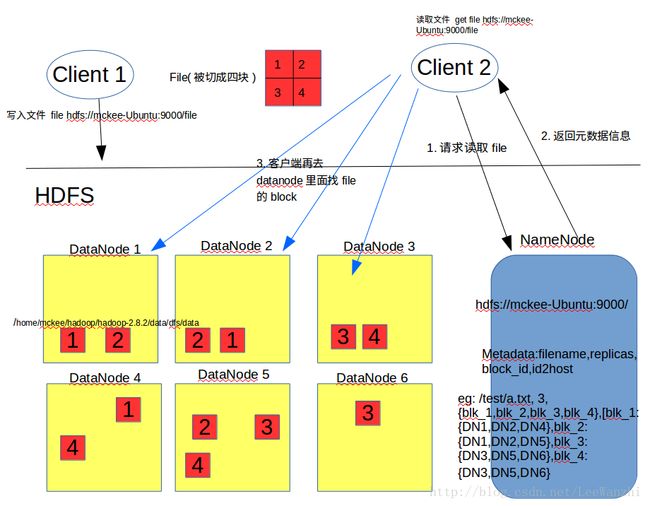
NameNode: 存放文件的元数据信息(数据分成了多少个block,多少副本,不同的block分到了哪些DataNode上),也即hdfs文件系统中的文件与真实的block之间的映射关系。其格式为:filename,replicas,block_id,id2host(文件名,副本数,block_id,block到主机NameNode的映射),结合上图好好体会。
DataNode:数据节点,提供真实文件数据的存储服务,即存储的是blocks。不同的数据节点在不同的主机上,多个主机可以在一个rack(机架)上,这样一个rack断电,其他rack仍然工作。分布式存储可以有效降低负载,提高数据的可靠性以及访问的吞吐量。
Secondary NameNode: 主要负责将操作日志文件中的元数据信息与元数据镜像文件合并。这个下面会具体讲工作流程,这里先忽略。
2.HDFS基本机制:
因为这里和下面讲的有很大重叠,所以这里先浅讲。
(1) 首先,client上传文件到HDFS文件系统的虚拟目录/hdfs://host-name:9000/…下,它以为数据就存放在这个目录下,其实不然,但对于用户,它只需这样以为就足够了。
(2)实际上,在client提出上传请求时,NameNode会响应它元数据信息,告诉client文件应该分成多少块,存放在哪些DataNode上;同时也会告诉datanode应该复制多少样本,复制在哪。
(3)然后,另一个client想下载这个文件,它会在虚拟目录/hdfs://host-name:9000/…下直接下载得到文件爱你,它以为它是这样得到的,其实不然,但对于用户,它只需这样以为就足够了。
(4)实际上,client请求下载时,NameNode会告诉它在哪些datanode中下载。然后,client去对应的datanode中把block下载下来,合并成一个block得到最终的完整的文件。
二、HDFS具体的工作原理
1. 写文件到HDFS

1.client上传文件到hdfs,发出上传请求
2.Namenode首先往edits中记录元数据操作日志,并返回元数据信息给client(即分成多少block,不同block放在哪些datanode上)
3.client根据namenode返回的信息,对文件进行切分,写入到datanode中
4.datanode再将block复制到其他datanode上,并向datanode返回成功信息,若失败,则重新分配datanode进行复制
5.client上传文件成功后,将成功信息返回给NameNode,NameNode将本次元数据信息写入内存
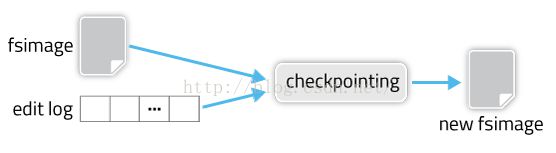
6.当edits写满时,需要将这一段时间内新的元数据刷到fs_image文件中,这个过程在secondary namenode中进行
6.1 首先Namenode通知Secondary Namenode进行checkpoint操作
6.2 然后Namenode会停止往edits中写数据,而是生成一个edits.new文件,数据写入edits.new
6.3 secondary namenode会从namenode下载 fs_image 和 edits,合并为fs_image.checkpoint
6.4 secondary namenode将fs_image.checkpoint上传到namenode,改名为fs_image,替换原文件;同时edits.new改名为edits,并替换原文件
HDFS Namenode本地目录的存储结构和Datanode数据块存储目录结构,也就是hdfs-site.xml中配置的dfs.namenode.name.dir和dfs.datanode.data.dir。
HDFS metadata主要存储两种类型的文件
1、fsimage
记录某一永久性检查点(Checkpoint)时整个HDFS的元信息
2、edits
所有对HDFS的写操作都会记录在此文件中
Checkpoint介绍
HDFS会定期(dfs.namenode.checkpoint.period,默认3600秒)的对最近的fsimage和一批新edits文件进行Checkpoint(也可以手工命令方式),Checkpoint发生后会将前一次Checkpoint后的所有edits文件合并到新的fsimage中,HDFS会保存最近两次checkpoint的fsimage。Namenode启动时会把最新的fsimage加载到内存中。
重要特征:
1.HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
2.HDFS文件系统会给客户端提供一个统一的抽象目录树(虚拟目录),客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
3.目录结构(HDFS的虚拟目录)及文件分块信息(元数据)的管理由namenode节点承担——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树(虚拟目录),以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
4.文件的各个block的存储管理由datanode节点承担---- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
5.HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
1、HDFS的设计
HDFS是什么:HDFS即Hadoop分布式文件系统(Hadoop Distributed Filesystem),以流式数据访问模式来存储超大文件,运行于商用硬件集群上,是管理网络中跨多台计算机存储的文件系统。
HDFS不适合用在:要求低时间延迟数据访问的应用,存储大量的小文件,多用户写入,任意修改文件。