sklearn.naive_bayes常用API介绍
高斯朴素贝叶斯
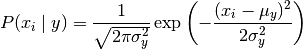
sklearn.naive_bayes.GaussianNB(priors=None):
priors:array-like,shape(n_classes,)
类别的先验概率,如果指定则不会根据数据改变
属性:
class_prior_:array,shape(n_classes,)
每一类的概率
class_prior_:array,shape(n_classes,)
每一类的概率
class_count_:array,shape(n_classes,)
每一类的训练样本个数
每一类的训练样本个数
theta_:array,shape(n_classes,n_features)
每一类每个特征的均值
每一类每个特征的均值
sigma_:array,shape(n_classes,n_features)
每一类每个特征的方差
from sklearn.naive_bayes import GaussianNB
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
Y = np.array([1, 1, 1, 2, 2, 2])
gnb = GaussianNB()
gnb.fit(X,Y)
print(gnb.class_count_)
#[3. 3.]
print(gnb.class_prior_)
#[0.5 0.5]
print(gnb.theta_)
#[[-2. -1.33333333]
#[ 2. 1.33333333]]
print(gnb.sigma_)
#[[0.66666667 0.22222223]
#[0.66666667 0.22222223]]
每一类每个特征的方差
from sklearn.naive_bayes import GaussianNB
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
Y = np.array([1, 1, 1, 2, 2, 2])
gnb = GaussianNB()
gnb.fit(X,Y)
print(gnb.class_count_)
#[3. 3.]
print(gnb.class_prior_)
#[0.5 0.5]
print(gnb.theta_)
#[[-2. -1.33333333]
#[ 2. 1.33333333]]
print(gnb.sigma_)
#[[0.66666667 0.22222223]
#[0.66666667 0.22222223]]
fit(X,y[,sample_weight])
根据X,y训练高斯朴素贝叶斯模型
X:array-like,shape(n_samples,n_features).训练向量
y:array-like,shape(n_samples,)目标值
sample_weight:array-like,shape(n_samples),默认None
每个样本的权值
根据X,y训练高斯朴素贝叶斯模型
X:array-like,shape(n_samples,n_features).训练向量
y:array-like,shape(n_samples,)目标值
sample_weight:array-like,shape(n_samples),默认None
每个样本的权值
返回训练好的模型
get_params(deep=True):获得参数
partial_fit(X,y,classes=None,sample_weight=None):
每次用一批样本增量拟合,连续在不同的大量数据集上进行拟合。当数据集太大时推荐使用
X:array-like,shape(n_samples,n_features).训练向量
y:array-like,shape(n_samples,)目标值
classes:array-like,shape(n_classes,),默认None
可能出现在y向量中的所有类别的list。第一次使用partial_fit时需要给出
sample_weight:array-like,shape(n_samples),默认None
每次用一批样本增量拟合,连续在不同的大量数据集上进行拟合。当数据集太大时推荐使用
X:array-like,shape(n_samples,n_features).训练向量
y:array-like,shape(n_samples,)目标值
classes:array-like,shape(n_classes,),默认None
可能出现在y向量中的所有类别的list。第一次使用partial_fit时需要给出
sample_weight:array-like,shape(n_samples),默认None
返回训练好的模型
predict(X):对测试向量X分类预测
X:array-like,shape(n_samples,n_features)
返回:X的目标值,array,shape(n_samples)
X:array-like,shape(n_samples,n_features)
返回:X的目标值,array,shape(n_samples)
predict_log_proba(X):
X:array-like,shape(n_samples,n_features)
返回C:array-like,shape(n_samples,n_classes),每个样本属于每个类别的概率的log值
Cij=样本i属于类别j的概率的log值
X:array-like,shape(n_samples,n_features)
返回C:array-like,shape(n_samples,n_classes),每个样本属于每个类别的概率的log值
Cij=样本i属于类别j的概率的log值
predict_proba(X):
X:array-like,shape(n_samples,n_features)
返回C:array-like,shape(n_samples,n_classes),每个样本属于每个类别的概率
Cij=样本i属于类别j的概率
X:array-like,shape(n_samples,n_features)
返回C:array-like,shape(n_samples,n_classes),每个样本属于每个类别的概率
Cij=样本i属于类别j的概率
score(X,y,sample_weight=None):
X:array-like,shape(n_samples,n_features)测试样本
y:array-like,shape(n_samples)或shape(n_samples,n_outputs),X的真实类别
sample_weight:array-like,shape(n_samples),默认None
每个样本的权值
X:array-like,shape(n_samples,n_features)测试样本
y:array-like,shape(n_samples)或shape(n_samples,n_outputs),X的真实类别
sample_weight:array-like,shape(n_samples),默认None
每个样本的权值
set_params(**params):设置参数
from sklearn.naive_bayes import GaussianNB
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
Y = np.array([1, 1, 1, 2, 2, 2])
gnb = GaussianNB()
gnb.fit(X,Y)
test = [[1,2],[-1,-2]]
print(gnb.predict(test))
#[2 1]
print(gnb.predict_proba(test))
#[[9.35762808e-14 1.00000000e+00]
# [1.00000000e+00 9.35762808e-14]]
print(gnb.predict_log_proba(test))
#[[-2.99999995e+01 -9.32587341e-14]
#[-9.32587341e-14 -2.99999995e+01]]
from sklearn.naive_bayes import GaussianNB
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
Y = np.array([1, 1, 1, 2, 2, 2])
gnb = GaussianNB()
gnb.fit(X,Y)
test = [[1,2],[-1,-2]]
print(gnb.predict(test))
#[2 1]
print(gnb.predict_proba(test))
#[[9.35762808e-14 1.00000000e+00]
# [1.00000000e+00 9.35762808e-14]]
print(gnb.predict_log_proba(test))
#[[-2.99999995e+01 -9.32587341e-14]
#[-9.32587341e-14 -2.99999995e+01]]
多项式朴素贝叶斯
sklearn.naive_bayes.MultinomialNB(alpha=1.0,fit_prior=True,class_prior=None)
多项式模型的朴素贝叶斯分类器
alpha:float,默认1.0.平滑参数
fit_prior:boolean,默认True
是否学习类别的先验概率,False时所有类的先验概率相等
是否学习类别的先验概率,False时所有类的先验概率相等
class_prior:array-like,shape(n_classes,)
类别的先验概率,如果指定则不会根据数据改变
类别的先验概率,如果指定则不会根据数据改变
属性:
class_log_prior:array,shape(n_classes,)
每一类平滑后的经验log概率
class_log_prior:array,shape(n_classes,)
每一类平滑后的经验log概率
intercept_:将多项式朴素贝叶斯模型作为线性模型时的class_log_prior镜像
feature_log_prob:array,shape(n_classes,n_features)
给定类别时特征的经验log概率,=P(xi|y)
给定类别时特征的经验log概率,=P(xi|y)
coef_:将多项式朴素贝叶斯模型作为线性模型时的class_log_prob镜像
class_count_:array,shape(n_classes,)
每一类的训练样本个数
每一类的训练样本个数
feature_count_:array,shape(n_classes,n_features)
训练时计数的每个(class,feature)的个数
训练时计数的每个(class,feature)的个数
方法;
fit(X,y[,sample_weight])
根据X,y训练高斯朴素贝叶斯模型
X:array-like,shape(n_samples,n_features).训练向量
y:array-like,shape(n_samples,)目标值
sample_weight:array-like,shape(n_samples),默认None
每个样本的权值
fit(X,y[,sample_weight])
根据X,y训练高斯朴素贝叶斯模型
X:array-like,shape(n_samples,n_features).训练向量
y:array-like,shape(n_samples,)目标值
sample_weight:array-like,shape(n_samples),默认None
每个样本的权值
返回训练好的模型
get_params(deep=True):获得参数
partial_fit(X,y,classes=None,sample_weight=None):
每次用一批样本增量拟合,连续在不同的大量数据集上进行拟合。当数据集太大时推荐使用
X:array-like,shape(n_samples,n_features).训练向量
y:array-like,shape(n_samples,)目标值
classes:array-like,shape(n_classes,),默认None
可能出现在y向量中的所有类别的list。第一次使用partial_fit时需要给出
sample_weight:array-like,shape(n_samples),默认None
每次用一批样本增量拟合,连续在不同的大量数据集上进行拟合。当数据集太大时推荐使用
X:array-like,shape(n_samples,n_features).训练向量
y:array-like,shape(n_samples,)目标值
classes:array-like,shape(n_classes,),默认None
可能出现在y向量中的所有类别的list。第一次使用partial_fit时需要给出
sample_weight:array-like,shape(n_samples),默认None
返回训练好的模型
predict(X):对测试向量X分类预测
X:array-like,shape(n_samples,n_features)
返回:X的目标值,array,shape(n_samples)
X:array-like,shape(n_samples,n_features)
返回:X的目标值,array,shape(n_samples)
predict_log_proba(X):
X:array-like,shape(n_samples,n_features)
返回C:array-like,shape(n_samples,n_classes),每个样本属于每个类别的概率的log值
Cij=样本i属于类别j的概率的log值
X:array-like,shape(n_samples,n_features)
返回C:array-like,shape(n_samples,n_classes),每个样本属于每个类别的概率的log值
Cij=样本i属于类别j的概率的log值
predict_proba(X):
X:array-like,shape(n_samples,n_features)
返回C:array-like,shape(n_samples,n_classes),每个样本属于每个类别的概率
Cij=样本i属于类别j的概率
X:array-like,shape(n_samples,n_features)
返回C:array-like,shape(n_samples,n_classes),每个样本属于每个类别的概率
Cij=样本i属于类别j的概率
score(X,y,sample_weight=None):
X:array-like,shape(n_samples,n_features)测试样本
y:array-like,shape(n_samples)或shape(n_samples,n_outputs),X的真实类别
sample_weight:array-like,shape(n_samples),默认None
每个样本的权值
X:array-like,shape(n_samples,n_features)测试样本
y:array-like,shape(n_samples)或shape(n_samples,n_outputs),X的真实类别
sample_weight:array-like,shape(n_samples),默认None
每个样本的权值
set_params(**params):设置参数
example:
from sklearn.naive_bayes import MultinomialNB
X = np.random.randint(5,size=(6,100))
y = np.array([1,1,3,3,5,5])
clf = MultinomialNB()
clf.fit(X,y)
print(clf.predict([X[2],X[4]]))
#[3 5]
print(clf.predict_proba([X[2],X[4]]))
#[[1.26317087e-20 1.00000000e+00 2.47165203e-17]
# [9.59835319e-27 1.35642916e-19 1.00000000e+00]]
print(clf.predict_log_proba([X[2],X[4]]))
#[[-52.56539043 0. -38.00629887]
#[-45.45670366 -44.93313846 0. ]]
example:
from sklearn.naive_bayes import MultinomialNB
X = np.random.randint(5,size=(6,100))
y = np.array([1,1,3,3,5,5])
clf = MultinomialNB()
clf.fit(X,y)
print(clf.predict([X[2],X[4]]))
#[3 5]
print(clf.predict_proba([X[2],X[4]]))
#[[1.26317087e-20 1.00000000e+00 2.47165203e-17]
# [9.59835319e-27 1.35642916e-19 1.00000000e+00]]
print(clf.predict_log_proba([X[2],X[4]]))
#[[-52.56539043 0. -38.00629887]
#[-45.45670366 -44.93313846 0. ]]
sklearn.naive_bayes.BernoulliNB(alpha=1.0,binarize=0.0,fit_prior=True,class_prior=None)
伯努利模型的朴素贝叶斯分类器
alpha:float,默认1.0.平滑参数
binarize:float or None,默认0.0
特征二元化的阀值,None时输入应保证是二元向量
特征二元化的阀值,None时输入应保证是二元向量
fit_prior:boolean,默认True
是否学习类别的先验概率,False时所有类的先验概率相等
是否学习类别的先验概率,False时所有类的先验概率相等
class_prior:array-like,shape(n_classes,)
类别的先验概率,如果指定则不会根据数据改变
类别的先验概率,如果指定则不会根据数据改变
属性:
class_log_prior:array,shape(n_classes,)
每一类平滑后的经验log概率
class_log_prior:array,shape(n_classes,)
每一类平滑后的经验log概率
feature_log_prob:array,shape(n_classes,n_features)
给定类别时特征的经验log概率,=P(xi|y)
给定类别时特征的经验log概率,=P(xi|y)
class_count_:array,shape(n_classes,)
每一类的训练样本个数
每一类的训练样本个数
feature_count_:array,shape(n_classes,n_features)
训练时计数的每个(class,feature)的个数
训练时计数的每个(class,feature)的个数
方法:
fit(X,y[,sample_weight])
根据X,y训练高斯朴素贝叶斯模型
X:array-like,shape(n_samples,n_features).训练向量
y:array-like,shape(n_samples,)目标值
sample_weight:array-like,shape(n_samples),默认None
每个样本的权值
fit(X,y[,sample_weight])
根据X,y训练高斯朴素贝叶斯模型
X:array-like,shape(n_samples,n_features).训练向量
y:array-like,shape(n_samples,)目标值
sample_weight:array-like,shape(n_samples),默认None
每个样本的权值
返回训练好的模型
get_params(deep=True):获得参数
partial_fit(X,y,classes=None,sample_weight=None):
每次用一批样本增量拟合,连续在不同的大量数据集上进行拟合。当数据集太大时推荐使用
X:array-like,shape(n_samples,n_features).训练向量
y:array-like,shape(n_samples,)目标值
classes:array-like,shape(n_classes,),默认None
可能出现在y向量中的所有类别的list。第一次使用partial_fit时需要给出
sample_weight:array-like,shape(n_samples),默认None
每次用一批样本增量拟合,连续在不同的大量数据集上进行拟合。当数据集太大时推荐使用
X:array-like,shape(n_samples,n_features).训练向量
y:array-like,shape(n_samples,)目标值
classes:array-like,shape(n_classes,),默认None
可能出现在y向量中的所有类别的list。第一次使用partial_fit时需要给出
sample_weight:array-like,shape(n_samples),默认None
返回训练好的模型
predict(X):对测试向量X分类预测
X:array-like,shape(n_samples,n_features)
返回:X的目标值,array,shape(n_samples)
X:array-like,shape(n_samples,n_features)
返回:X的目标值,array,shape(n_samples)
predict_log_proba(X):
X:array-like,shape(n_samples,n_features)
返回C:array-like,shape(n_samples,n_classes),每个样本属于每个类别的概率的log值
Cij=样本i属于类别j的概率的log值
X:array-like,shape(n_samples,n_features)
返回C:array-like,shape(n_samples,n_classes),每个样本属于每个类别的概率的log值
Cij=样本i属于类别j的概率的log值
predict_proba(X):
X:array-like,shape(n_samples,n_features)
返回C:array-like,shape(n_samples,n_classes),每个样本属于每个类别的概率
Cij=样本i属于类别j的概率
X:array-like,shape(n_samples,n_features)
返回C:array-like,shape(n_samples,n_classes),每个样本属于每个类别的概率
Cij=样本i属于类别j的概率
score(X,y,sample_weight=None):
X:array-like,shape(n_samples,n_features)测试样本
y:array-like,shape(n_samples)或shape(n_samples,n_outputs),X的真实类别
sample_weight:array-like,shape(n_samples),默认None
每个样本的权值
X:array-like,shape(n_samples,n_features)测试样本
y:array-like,shape(n_samples)或shape(n_samples,n_outputs),X的真实类别
sample_weight:array-like,shape(n_samples),默认None
每个样本的权值
set_params(**params):设置参数
example:
from sklearn.naive_bayes import BernoulliNB
X = np.random.randint(5,size=(6,100))
y = np.array([1,1,3,3,5,5])
clf = BernoulliNB()
clf.fit(X,y)
print(clf.predict([X[2],X[4]]))
#[3 5]
print(clf.predict_proba([X[2],X[4]]))
#[[1.47005968e-08 9.99999985e-01 5.37744740e-11]
# [3.22646849e-10 1.69953896e-10 1.00000000e+00]]
print(clf.predict_log_proba([X[2],X[4]]))
#[[-1.80353777e+01 -1.47543702e-08 -2.36462222e+01]
#[-2.18544627e+01 -2.24954939e+01 -4.92597962e-10]]
from sklearn.naive_bayes import BernoulliNB
X = np.random.randint(5,size=(6,100))
y = np.array([1,1,3,3,5,5])
clf = BernoulliNB()
clf.fit(X,y)
print(clf.predict([X[2],X[4]]))
#[3 5]
print(clf.predict_proba([X[2],X[4]]))
#[[1.47005968e-08 9.99999985e-01 5.37744740e-11]
# [3.22646849e-10 1.69953896e-10 1.00000000e+00]]
print(clf.predict_log_proba([X[2],X[4]]))
#[[-1.80353777e+01 -1.47543702e-08 -2.36462222e+01]
#[-2.18544627e+01 -2.24954939e+01 -4.92597962e-10]]