跟我一起读《Hadoop权威指南》 第二篇 -- 入门程序,编写MapReduce处理气象数据
气象数据集
关于MapReduce
MapReduce是一种可用于数据处理的编程模型,它本质上是并行运行的,因此可以将大规模的数据分析任务分发给任何一个拥有足够多机器的数据中心。MapReduce的优势在于处理大规模数据集,这里我们先看一个数据集。我们今天的目的是:在大批量的气象数据中,获取每年每月的最高气温。数据格式
我们使用的数据来自于权威指南提供的美国国家气候数据中心,该数据按行为单位,每一行包含日期、气温、地点等等信息。比如下列数据为:1901年12月29日到31日的数据,相信细心的你会找到日期的,而温度是每一行的第87到92个字符(包含正负号)。0029227070999991901122913004+62167+030650FM-12+010299999V0200701N002119999999N0000001N9-01561+99999100271ADDGF104991999999999999999999 0029227070999991901122920004+62167+030650FM-12+010299999V0200701N002119999999N0000001N9-02001+99999100501ADDGF107991999999999999999999 0029227070999991901123006004+62167+030650FM-12+010299999V0200701N003119999999N0000001N9-01501+99999100791ADDGF108991999999999999999999 0029227070999991901123013004+62167+030650FM-12+010299999V0200901N003119999999N0000001N9-01331+99999100901ADDGF108991999999999999999999 0029227070999991901123020004+62167+030650FM-12+010299999V0200701N002119999999N0000001N9-01221+99999100831ADDGF108991999999999999999999 0029227070999991901123106004+62167+030650FM-12+010299999V0200701N004119999999N0000001N9-01391+99999100521ADDGF108991999999999999999999 0029227070999991901123113004+62167+030650FM-12+010299999V0200701N003119999999N0000001N9-01391+99999100321ADDGF108991999999999999999999 0029227070999991901123120004+62167+030650FM-12+010299999V0200701N004119999999N0000001N9-01391+99999100281ADDGF108991999999999999999999测试数据下载 Hadoop测试数据–气象数据集
使用MapReduce来分析数据
为了充分利用Hadoop提供的并行处理优势,我们需要将查询表示成MapReduce作业,完成某种本地端的小规模测试之后,就可以把作业部署到集群上运行。
- Map和Reduce
MapReduce任务过程分为两个处理阶段:Map阶段和Reduce阶段,每阶段都以 键-值 作为输入和输出,其类型又开发者根据实际情况自行决定。我们需要编写两个函数:Map函数和Reduce函数。
Map阶段的输入是你刚刚下载的气象数据集,每一行就是一条气象数据,Map的输入的值的格式就是文本格式(String),键就是每一行的起始位置相对于整片内容的偏移量,在这里无实际意义,给Long类型即可。Map函数实现的功能很简单,就是将每一行的数据进行截取,得到我们需要的年份、月份以及气温数据。
为了全面了解Map的工作方式,我们考虑以下输入数据的实例数据(将中间无用的数据省略了,并用省略号表示):
0029227070999991901123013004......N0000001N9-01391+99999100321A......
0029227070999991901123120004......N0000001N9-01391+99999100281A......
这些行以键值对的方式作为map输入
(0,0029227070999991901123013004......N0000001N9-01391+99999100321A......),
(106,0029227070999991901123120004......N0000001N9-01391+99999100281A......)key是文件中的行起始位置的偏移量,Map函数本身不需要这个,所以将其忽略掉,Map函数只需要提取年份月份、气温信息,并将他们作为以下格式输出给Reduce:
(190110, 12),
(190110, 15),
(190111, 22),
(190112, 11)...Map 函数的输出经由Map Reduce框架处理后,最后发送给reduce函数。这个过程基于键来对键值对进行排序和分组。因此,reduce函数接收到的是如下输入:
(190110, [12, 15]),
(190111, 22),
(190112, 11)...每个年份月份后跟着一个气温集合,reduce函数只需要从这个气温集合中找出最大的一个值,就能找到当前月份最高气温了:
(190110, 15),
(190111, 22),
(190112, 11)...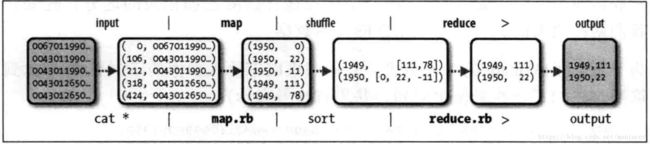
- java MapReduce
明白了Map Reduce的处理流程之后,我们下一步就是编写代码实现它。我们需要三样东西:一个map函数,一个reduce函数,外加一个用来运行作业的代码,
本项目就是一个普通Java项目,编写完三个类后可以打成jar包运行。
pom.xml配置如下(hadoop-client)
"1.0" encoding="UTF-8"?>"http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 4.0.0 com.mright.hadoop.test mright-hadoop-test 1.0-SNAPSHOT org.apache.maven.plugins maven-compiler-plugin 8 8 org.apache.hadoop hadoop-client 2.8.3 mapper函数如下:
package com.mright.hadoop.mapreduce.mapper;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class TamperatureMaper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String month = line.substring(15, 21);
int temperature;
// 正负值的判断
if ('+' == line.charAt(87)) {
temperature = Integer.parseInt(line.substring(88, 92));
} else {
temperature = Integer.parseInt(line.substring(87, 92));
}
// 这里根据实际情况添加过滤条件,对于脏数据是不能放行的
if (temperature > -99 && temperature < 99) {
context.write(new Text(month), new IntWritable(temperature));
}
}
}
这个mapper类是一个范性类型,他有四个形参类型,分别指定mapper函数的输入键,输入值,输出键,输出值类型。在Hadoop的API中,int用IntWritable代替,long用LongWritable代替,String用Text代替。
reducer函数如下:
package com.mright.hadoop.mapreduce.reducer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Arrays;
public class TemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
final int[] maxValue = {-99};
// jdk8才能使用此方法,否则请使用一般for循环
values.forEach(value->{
maxValue[0] = Math.max(value.get(), maxValue[0]);
});
context.write(key, new IntWritable(maxValue[0]));
}
}
同理,四个形参分别代指输入输出键值的类型,感觉这里有问题的同学请回到mapreduce分析那几段话看看流程。
job启动类
package com.mright.hadoop.mapreduce.job;
import com.mright.hadoop.mapreduce.mapper.TamperatureMaper;
import com.mright.hadoop.mapreduce.reducer.TemperatureReducer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TemperatureJob {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args.length != 2) {
System.err.println("你必传两个参数,被处理数据所在目录和结果集数据存放目录");
System.exit(-1);
}
Job job = Job.getInstance();
job.setJarByClass(TemperatureJob.class);
job.setJobName("处理气温的Job");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(TamperatureMaper.class);
job.setReducerClass(TemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
首先构建Job对象,指定启动类,设置Job名称,这个在Hadoop监控页面可以看到执行过的Job
构建Job成功之后,需要指定输入和输出数据的路径,调用FileInputFormat和FileOutputFormat分别指定,FileInputFormat.addInputPath可以指定多个输入数据的路径,也就是说输入的数据可以有很多个。
接着指定Mapper和Reducer
setOutputKeyClass和setOutputValueClass设置reducer的输出类型,Mapper的输出类型默认和Reducer是一样的,如果不一样,需要通过setMapOutputKeyClass()和setMapOutputValueClase()设置。
最后是运行Job,job的waitForCompletion方法是提交作业并等待执行完毕。
一切无误后直接package打成jar包
运行测试
- 准备数据
- 本博客起始位置有数据的下载链接,下载数据之后上传到hdfs
// 创建存放数据的目录
hdfs dfs -mkdir /input
// 上传数据
hdfs dfs -put 1901 /input
hdfs dfs -put 1902 /input- 切换到jar包所在的目录,启动jar | 如果是win搭建的虚拟机,则将jar发送至虚拟机,在jar所在的目录执行下边的命令:注意jar名和Job所在主类的全称命名。
hadoop jar mright-hadoop-test-1.0-SNAPSHOT.jar com.mright.hadoop.mapreduce.job.TemperatureJob /input /output

- 执行完毕后,查看结果,如果运行有问题或者job卡顿五分钟以上不动,那么请参考本系列第一篇的最后部分。
hdfs dfs -ls /output
hdfs dfs -cat /output/part-r-00000

- 数据集的温度是不包含小数的,因此每个温度都被扩大了10倍,看看效果就好,不必纠结数值。到此为止气象数据的Map Reduce任务已经完成,下边是关于整个过程的数据流详解。
数据流
map
- 首先定义一些术语:Map Reduce(Job)作业是客户端需要执行的一个工作单元,他们包括输入数据、Map Reduce程序和配置信息。Hadoop将作业分为若干个任务(Task)来执行,其中包括两类任务:Map任务和Reduce任务。这些任务运行在集群的节点上,并通过Yarn进行调度。如果一个任务失败,他将在另一个不同的节点上自动重试。
- Hadoop将Map Reduce的输入数据划分为等长的小数据块,称为输入分片(input split)或者简称分片。Hadoop为每个分片都会创建一个Map任务,并由该任务来运行用户自己定义的Map函数,多个Map的输出会经过shuffle阶段处理后交给一个或者多个reduce,在气象数据的程序中是只有一个reduce。
- 分片的存在意味着Hadoop可以将一个非常大的输入数据块切分成多个小的分片,那么程序处理每个分片所需的时间就会小于直接处理整个大的数据块所需的时间。但是如果分片分的太小,那么管理分片的总时间和构建map任务的总时间将会成为整个处理流程的瓶颈。对于大多数的作业来说,一个合理的分片大小趋向于一个HDFS一个块的大小,默认是128MB,不过可以根据服务器的情况或者实际需求进行调整。
- Hadoop如果在存储分片的节点上运行map任务会得到最佳性能,因为这样避免了使用宝贵的集群宽带资源,这就是”数据本地化优势”。但是,对于一个map任务的输入分片来说,存储该分片数据及备份的所有节点可能都在执行其他的map任务,此时作业调度必须从某一数据块所在的机架中的一个节点上寻找一个空闲的map槽(slot)来运行该分片的map任务。这种情况一般不会出现,只有在任务数特别多的情况下才有可能出现。

- map任务将其输出写入本地硬盘,而非hdfs,这又是为何?因为map的输出是中间结果,该结果由reduce处理后才能产生最终结果,而且整个流程走完之后map的输出数据是要被清除的。因此如果将map的输出数据存储在HDFS中,HDFS又会自动生成副本进行备份,在任务执行完毕后再删除HDFS中的元数据及副本,这样做显得有点小题大做。如果运行map任务的节点在将map中金啊结果传送至reduce之前失败了,那么Hadoop会在另外一个节点重新运行这个map任务并再次构建map结果。
reduce
reduce并不具备数据本地化的优势,单个的reduce任务的输入通常来自于所有mapper的输出。在气象数据的例子中就是只有一个reduce任务,其输入是所有map的输出。因此排过序的map输出需要通过网络传输发送到运行reduce的任务节点。数据在reduce端合并,然后由用户定义的reduce函数处理。reduce的输出通常存储在HDFS中以供可靠存储。对于reduce输出的每一个数据块,第一个副本存储在本地节点上,其他副本出于可靠性考虑存储在其他机架的节点上。因此将reduce的输出写入HDFS确实需要占用网络带宽,只不过这跟正常的HDFS管线的读写的消耗是一样的。

对于有很多个reduce任务的情况,每个map任务会针对输出进行分区(partition),即为每个reduce任务建一个分区。每个分区有很多个键(及其对应的值),每个键值的记录都在同一个partition中。分区可以有用户定义的分区函数控制,但通常用默认的partition通过哈希函数来分区,性能很高。

map任务和reduce任务之间的处理逻辑统称为shuffle(混洗),因为每个reduce任务的输入来自于多个map输出。当数据处理任务可以完全并行,不需要混洗和reduce处理的时候,那么map分组处理完的数据就会直接写入hdfs。

combiner函数
集群上的可用带宽限制了Map Reduce的作业数量,因此应该尽量避免map和reduce任务之间的数据传输。Hadoop针对map任务的输出指定了一个combiner函数(功能与map和reduce一致,都是接受键值对、输出处理后的键值对),如果配置了combiner函数,map输出会交给combiner处理,combiner输出再交给reducer处理。
以上面的气象数据任务为例:
第一个map的输出为
(1950, 0),
(1950, 20),
(1950, 10)第二个map的输出为
(1950, 25),
(1950, 15)没有添加combiner之前,reduce接受到的参数:
(1950, [0, 20, 10, 25, 25])添加combiner之后,每一个map输出后会直接调用combiner函数,所以第一个map会输出:
(1950, 20)第二个map
(1950, 25)因此,reduce输入为
(1950, 20, 25)- 当执行combiner函数之后,map之后reduce之前的网络传输数据会降低很多。下边是气象数据任务的修改Job之后的代码
package com.mright.hadoop.mapreduce.job;
import com.mright.hadoop.mapreduce.mapper.TamperatureMaper;
import com.mright.hadoop.mapreduce.reducer.TemperatureReducer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TemperatureJob {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args.length != 2) {
System.err.println("你必传两个参数,被处理数据所在目录和结果集数据存放目录");
System.exit(-1);
}
Job job = Job.getInstance();
job.setJarByClass(TemperatureJob.class);
job.setJobName("处理气温的Job");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(TamperatureMaper.class);
job.setReducerClass(TemperatureReducer.class);
job.setCombinerClass(TemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 这里combiner直接调用了reduce类,因为combiner的逻辑和reduce是一样的。但是combiner是不能够取代reduce的,因为我们仍然需要reduce来处理不同map中输出的具有相同键的记录。combiner已经帮助我们减少了很多的网络带宽传输量,因此combiner函数的作用还是不容忽视的。
总结
Hadoop权威指南第二章就讲了这些东西,虽然很多文字都只是简单的搬运,但是我觉得就我个人而言还是有很大提升的:阅读可能很快,一章几十页无非三五个时辰就可以浏览一遍,但是阅读的过程只是一个概念形成的过程,在我的脑海里都只是一些碎片化的知识,过不了几天就会忘记,而编写博客可能花费的时间比阅读要来的多一些,要仔细重复阅读几遍,要每一个细节的实验都要做,这其实就是一个碎片化知识系统化的过程,是不容易忘记的,以后即使忘记也可以回过头来查看博客。
2018年的五一假期我没有回家,没有约朋友胡搞,只希望能够静下心来好好思考自己的路应该怎么走,能够稳住心态提升下自己,最后还是希望能够坚持下去,抽时间将每一份感悟记录下来,毕竟,自己已不再是刚毕业懵懂无知的小子了