Opencv暑期历程--Day10(6种肤色检测方法,YCrCb肤色模型解释,再理解一遍掩模)
从一篇文章了解到,肤色检测主要有以下七种方法:
- RGB color space
- Ycrcb之cr分量+otsu阈值化
- YCrCb中133<=Cr<=173 77<=Cb<=127
- HSV中 7
- 基于椭圆皮肤模型的皮肤检测
- opencv自带肤色检测类AdaptiveSkinDetector
不过经作者自己检验,用RGB的方法受光线影响比较大,鲁棒性太低了,所以我们这次就不实验它了,留下一个判别式就好。
第三种也不好用,
方法一:基于RGB的皮肤检测
根据RGB颜色模型找出定义好的肤色范围内的像素点,范围外的像素点设为黑色。
查阅资料后可以知道,前人做了大量研究,肤色在RGB模型下的范围基本满足以下约束:
在均匀光照下应满足以下判别式:
R>95 AND G>40 B>20 AND MAX(R,G,B)-MIN(R,G,B)>15 AND ABS(R-G)>15 AND R>G AND R>B
在侧光拍摄环境下:
R>220 AND G>210 AND B>170 AND ABS(R-G)<=15 AND R>B AND G>B
方法二:基于椭圆皮肤模型的皮肤检测
经过前人学者大量的皮肤统计信息可以知道,如果将皮肤信息映射到YCrCb空间,则在CrCb二维空间中这些皮肤像素点近似成一个椭圆分布。因此如果我们得到了一个CrCb的椭圆,下次来一个坐标(Cr, Cb)我们只需判断它是否在椭圆内(包括边界),如果是,则可以判断其为皮肤,否则就是非皮肤像素点。
看看这个YCrCb是个啥:
肤色YCbCr颜色空间是一种常用的肤色检测的色彩模型,其中Y代表亮度,Cr代表光源中的红色分量,Cb代表光源中的蓝色分量。人的肤色在外观上的差异是由色度引起的,不同人的肤色分布集中在较小的区域内。肤色的YCbCr颜色空间CbCr平面分布在近似的椭圆区域内,通过判断当前像素点的CbCr是否落在肤色分布的椭圆区域内,就可以很容易地确认当前像素点是否属于肤色。将图像转换到YCbCr空间并且在CbCr平面进行投影,可以采集到肤色的样本点。
将CbCr平面均分为许多小区域,将每个区域的中心点CbCr色度值作为当前区域的特征值,对肤色区域像素值进行遍历,如果当前像素值落在该区域内则替换当前区域特征值。

这么一看,和HSV模型有点像哈。

3、YUV和RGB互相转换的公式如下(RGB取值范围均为0-255)︰
Y = 0.299R + 0.587G + 0.114B
U = -0.147R - 0.289G + 0.436B
V = 0.615R - 0.515G - 0.100B
R = Y + 1.14V
G = Y - 0.39U - 0.58V
B = Y + 2.03U
大概知道了,YUV(YCrCb)就是一个单独把亮度分离开来的颜色模型,使用这个颜色模型的话,像肤色不会受到光线亮度而发生改变。
在实际代码中,该椭圆是采用绘画函数绘制到图片上的,一句代码而已:
ellipse(skinCrCbHist, Point(113, 155.6), Size(23.4, 15.2), 43.0, 0.0, 360.0, Scalar(255, 255, 255), -1);void ellipse(Mat& img, Point center, Size axes, double angle, double startAngle, double endAngle, const Scalar&color, int thickness=1, int lineType=8, int shift=0)
该函数是用来在指定图片上绘制椭圆弧线的。
参数image为需要绘制椭圆的图像;
参数center是该椭圆的中心点坐标;
参数axes是该椭圆的长半轴和短半轴;
参数angle是该椭圆和水平方向上的旋转夹角;
参数startAngle表示绘制椭圆弧线相对该椭圆自己的水平轴的起始角度;
参数endAngel表示绘制椭圆弧线相对该椭圆自己的水平轴的终止角度;
后面的参数比较普通就不介绍了。
即将图像转化到YCbCr 空间并且在CbCr平面进行投影,因此我们采集了肤色的样本点,将其投影到此平面,并且投影后,我们进行了相应的非线性变换K-L变换
刚才疑问为啥那个长短半轴的长度,以及角度是怎么得出来的,根据这个图形,大概就可以看出来角度是43~45之间了。这个参数应该是固定的。
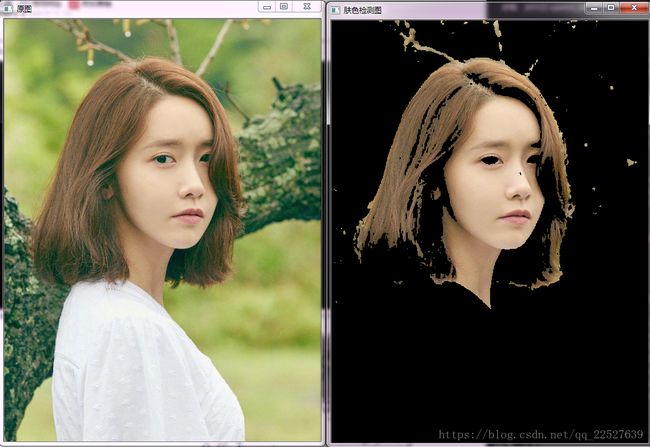
哇,用允儿的照片,不知道会不会被打。
// opencv_day10.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/highgui/highgui.hpp"
#include
using namespace cv;
using namespace std;
Mat ellipse_detect(Mat &src);
int main()
{
Mat image = imread("1.jpg");
resize(image, image, Size(image.cols/2,image.rows/2));
Mat detect = ellipse_detect(image);
imshow("原图", image);
imshow("肤色检测图", detect);
waitKey();
return 0;
}
Mat ellipse_detect(Mat &src)
{
Mat img = src.clone();
Mat skinCrCbHist = Mat::zeros(Size(256, 256), CV_8UC1);//256*256的矩阵,相当于CrCb分量的横纵坐标
//利用Opencv自带的椭圆生成函数生成一个肤色椭圆模型
ellipse(skinCrCbHist, Point(113, 155.6), Size(23.4, 15.2), 43.0, 0.0, 360.0, Scalar(255, 255, 255), -1);
Mat ycrcb_image;
Mat output_mask = Mat::zeros(img.size(), CV_8UC1);
cvtColor(img, ycrcb_image, CV_BGR2YCrCb); //首先转换成到YCrCb空间
for (int i = 0; i < img.cols; i++)
{
for (int j = 0; j < img.rows; j++)
{
Vec3b ycrcb = ycrcb_image.at(j, i);
if (skinCrCbHist.at(ycrcb[1], ycrcb[2]) > 0)//如果该点落在皮肤模型椭圆区域内,则该点是皮肤像素点。
output_mask.at(j, i) = 255;
}
}
Mat detect;
img.copyTo(detect, output_mask);//返回肤色图
return detect;
}
这段代码的大致流程是这样的,首先先设置一个单通道的256*256大小的二维矩阵,全0填充完也就是黑色的了。
Mat skinCrCbHist = Mat::zeros(Size(256, 256), CV_8UC1);//256*256的矩阵,相当于CrCb分量的横纵坐标。
然后再上面画一个椭圆,具体位置大小角度等是固定的了,这是前人实验总结出来的。
ellipse(skinCrCbHist, Point(113, 155.6), Size(23.4, 15.2), 43.0, 0.0, 360.0, Scalar(255, 255, 255), -1);//画椭圆,-1表示全填充,也就是说这个椭圆是全白的
接下来把获取的图像转为YCrCb颜色模型的图像,由于用这个模型就是为了排除Y(亮度)的影响,所以横纵坐标分别是Cb,Cr,看上面的图就知道了。转完后,遍历转完图像的像素点,看其后两个通道的值,也就是Cb,Cr的值,转到前面的掩模上就是它的横纵坐标,那我们之前根据这个坐标,对应到的位置如果在椭圆里面,之前椭圆是白色的嘛,底是黑色的,那么说明这个点是肤色点了。
也就是在这个图阴影的位置。
我们新建了一个掩模,Mat output_mask = Mat::zeros(img.size(), CV_8UC1);,跟原图一样大小,不过是黑色的。然后如果原图上哪一个点是肤色像素点,那么我们就把掩模上的这个点设为255,之后用copyTo函数的时候,会把这两个图进行掩模运算再过去,就是只显示肤色像素点的图了。
说起掩模,可以去这个地方看:http://www.cnblogs.com/skyfsm/p/6894685.html
法三:YCrCb颜色空间Cr分量+Otsu法阈值分割
该方法的原理也很简单:
a.将RGB图像转换到YCrCb颜色空间,提取Cr分量图像
b.对Cr做自二值化阈值分割处理(Otsu法)

效果也还不错
#include "stdafx.h"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/highgui/highgui.hpp"
#include
using namespace cv;
using namespace std;
Mat YCrCb_Otsu_detect(Mat& src);
int main()
{
Mat image = imread("1.jpg");
resize(image, image, Size(image.cols/2,image.rows/2));
Mat detect = YCrCb_Otsu_detect(image);
imshow("原图", image);
imshow("肤色检测图", detect);
waitKey();
return 0;
}
/*YCrCb颜色空间Cr分量+Otsu法*/
Mat YCrCb_Otsu_detect(Mat& src)
{
Mat ycrcb_image;
cvtColor(src, ycrcb_image, CV_BGR2YCrCb); //首先转换成到YCrCb空间
Mat detect;
vector channels;
split(ycrcb_image, channels);//分割颜色通道
Mat output_mask = channels[1];//取Cr通道的图像
threshold(output_mask, output_mask, 0, 255, CV_THRESH_BINARY | CV_THRESH_OTSU);//自动阈值分割
src.copyTo(detect, output_mask);
return detect;
} Otsu算法原理
Otsu算法(大津法或最大类间方差法)使用的是聚类的思想,把图像的灰度数按灰度级分成2个部分,使得两个部分之间的灰度值差异最大,每个部分之间的灰度差异最小,通过方差的计算来寻找一个合适的灰度级别来划分。 所以可以在二值化的时候采用otsu算法来自动选取阈值进行二值化。otsu算法被认为是图像分割中阈值选取的最佳算法,计算简单,不受图像亮度和对比度的影响。因此,使类间方差最大的分割意味着错分概率最小。
设t为设定的阈值。
| w0 | 分开后前景像素点数占图像的比例 |
| u0 | 分开后前景像素点的平均灰度 |
| w1 | 分开后背景像素点数占图像的比例 |
| u1 | 分开后背景像素点的平均灰度 |
图像总平均灰度为: u = w0∗u0 + w1∗u1
从L个灰度级遍历 t,使得 t 为某个值的时候,前景和背景的方差最大,则 这个 t 值便是我们要求得的阈值。其中,方差的计算公式如下:
g = wo∗(u0−u)∗(u0−u) + w1∗(u1−u)∗(u1−u)
此公式计算量较大,可以采用:
g = w0∗w1∗(u0−u1)∗(u0−u1)
由于Otsu算法是对图像的灰度级进行聚类,因此在执行Otsu算法之前,需要计算该图像的灰度直方图。
法四:基于YCrCb颜色空间Cr,Cb范围筛选法
这个方法跟法一其实大同小异,只是颜色空间不同而已。据资料显示,正常黄种人的Cr分量大约在133至173之间,Cb分量大约在77至127之间。大家可以根据自己项目需求放大或缩小这两个分量的范围,会有不同的效果。
算了,,这个懒得做了,,因为只是加个判断的,原理很好理解。
法五:HSV颜色空间H范围筛选法
同样地,也是在不同的颜色空间下采取相应的颜色范围将皮肤分割出来。
肤色的HSV值应在
0<=H<=20;S>=48;V>=50;//这个也不想做
if (p_src[h] >= 0 && p_src[h] <= 20 && p_src[s] >=48 && p_src[v] >=50)
{
p_mask[0] = 255;
}法六:opencv自带肤色检测类AdaptiveSkinDetector
opencv提供了下面这个皮肤检测类,类里面有
filter.process(frame, maskImg);这个函数可以把图片处理出肤色像素点到掩模上。
CvAdaptiveSkinDetector(int samplingDivider = 1, int morphingMethod = MORPHING_METHOD_NONE);
这个函数的第二个参数表示皮肤检测过程时所采用的图形学操作方式,其取值有3种可能:
- 如果为MORPHING_METHOD_ERODE,则表示只进行一次腐蚀操作;
- 如果为MORPHING_METHOD_ERODE_ERODE,则表示连续进行2次腐蚀操作;
- 如果为MORPHING_METHOD_ERODE_DILATE,则表示先进行一次腐蚀操作,后进行一次膨胀操作。
我的Opencv里面没有这个类,不知道是不是因为我是2的,而那个博主使用的是3的Opencv的原因。所以这个就没法做了。
他的代码的意思是先声明了一个皮肤像素检测的类对象,然后设置好对象的参数,之后调用对象里面的处理函数,功能是把一张图处理后放到第二张掩模里。
/*opencv自带肤色检测类AdaptiveSkinDetector*/
Mat AdaptiveSkinDetector_detect(Mat& src)
{
IplImage *frame;
frame = &IplImage(src); //Mat -> IplImage
CvAdaptiveSkinDetector filter(1, CvAdaptiveSkinDetector::MORPHING_METHOD_ERODE_DILATE);
IplImage *maskImg = cvCreateImage(cvSize(src.cols, src.rows), IPL_DEPTH_8U, 1);
IplImage *skinImg = cvCreateImage(cvSize(src.cols, src.rows), IPL_DEPTH_8U, 3);
cvZero(skinImg);
filter.process(frame, maskImg); // process the frame
cvCopy(frame, skinImg, maskImg);
Mat tmp(skinImg); //IplImage -> Mat
Mat detect = tmp.clone();
cvReleaseImage(&skinImg);
cvReleaseImage(&maskImg);
return detect;
}注意这句,哪个图像拷贝到哪个图像?
image.copyTo(img2, mask);当然是原始图image拷贝到目的图img2上啦。
其实拷贝的动作完整版本是这样的:
原图(image)与掩膜(mask)进行与运算后得到了结果图(img2)。
何为图与掩膜的与运算?
其实就是原图中的每个像素和掩膜中的每个对应像素进行与运算。比如1 & 1 = 1;1 & 0 = 0;
比如一个3 * 3的图像与3 * 3的掩膜进行运算,得到的结果图像就是:
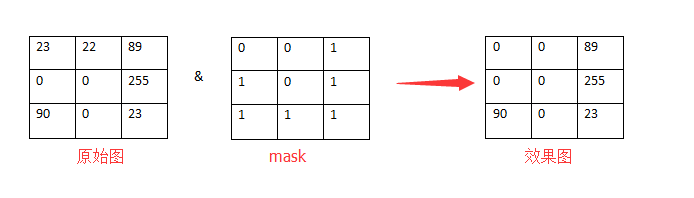
现在就已经完全理解为什么要x用掩模了,因为掩模设置为1的区域或者255的区域,反正跟另一个图与完还是1,就允许拷贝过去了。之前的也是这样。