Python学习笔记(二十八):线程
进程和线程的区别:
-
进程:是系统进行资源分配和调度的一个独立单位;
-
线程:是进程的一个实体,是 CPU 调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈);但是它可与同属一个进程的其他线程共享进程所拥有的全部资源。
-
一个程序至少有一个进程,一个进程至少有一个线程;
-
线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高;
-
进程在执行过程中,拥有独立的内存单元;而多个线程共享一个内存单元,从而极大地提高了程序的运行效率;
-
线程不能够独立运行,必须依存在进程中;
-
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反;
-
进程和线程都能够完成多任务:比如一个电脑上可以安装多个 QQ,多个 QQ 就是多个进程;而一个 QQ 可以打开多个聊天窗口,可以同时与多人聊天,这就是多线程。
-
每个线程都有它自己的一组 CPU 寄存器,称为线程的上下文,该上下文反映了上次运行该线程的 CPU 寄存器状态;
-
线程可以被抢断(中断);
threading 模块:
python 中用于线程的两个模块为 _thread 和 threading;
thread 模块已经被弃用,在 python3 中不能再使用 thread 模块,为了兼容性,python3 将 thread 模块重命名为 _thread;但是 _thread 模块只提供了低级别的、原始的线程、以及一个简单的锁;而 threading 模块除了包含 _thread 模块中的所有方法外,还提供了其他的方法:
-
threading.currentThread():返回当前的线程对象;
-
threading.enumerate():返回一个包含正在运行的线程的 list;正在运行指线程启动后,结束前;
-
threading.activeCount():返回正在运行的线程数量,与 len(threading.enumerate) 有相同的结果;
threading 模块除了提供上面的方法外,还提供了 Thread 类来表示一个线程,Thread 类提供了以下方法:
-
run():用于执行线程功能的方法;
-
start():用于启动线程;
-
join([time]):等待线程结束;
-
isAlive():返回线程是否活动的;
-
getName():返回线程名。默认线程名为 Thread-N,N 是从 1 递增的整数;
-
setName():设置线程名;
创建子线程方法一:
实例化 threading.Thread 对象,通过 target 参数指定线程执行的对象;
# 导入 threading 模块
import threading
import time
# 声明一个函数,在子线程中执行
def test(msg):
for i in range(5):
print("=== %s-%d ===" %(msg, i))
print("thread_name:", threading.currentThread().getName())
time.sleep(1)
if __name__ == "__main__":
# 创建子线程,并指定子线程执行的对象(test函数)
# args 参数用于向线程中传入参数,以元祖的形式;
t = threading.Thread(target=test, args=("hello", ))
# 启动子线程
t.start()
# join() 方法用于阻塞线程,即等待线程执行结束才会继续向下执行
t.join()
# print(t.getName()) # 获取线程的名字
print("=== main ===")
创建子线程方法二:
自定义一个类,继承于 Thread 类,然后重写 Thread 类的 run() 方法;
# 导入 threading 模块
import threading
import time
# 自定义一个类,继承于 Thread 类
class MyThread(threading.Thread):
# 重写 Thread 类的 run 方法,self 是当前线程对象
def run(self):
for i in range(5):
print("=== %s ===" %(self.name))
time.sleep(1)
if __name__ == "__main__":
# 实例化自定义类的对象
t = MyThread()
# 启动子线程,自动执行 run 方法
t.start()
print("=== main ===")
多线程共享全局变量:
多线程共享全局变量,可以通过在线程方法中声明全局变量来实现:
# 导入 threading 模块中的 Thread 类
from threading import Thread
import time
# 声明一个全局变量
g_num = 100
# 声明两个函数 work1 和 work2,在子线程中执行
def work1():
# 子线程中操作外部全局变量,需要用 global 关键字声明全局变量
global g_num
g_num += 100
print("---in work1, g_num is %d---" %g_num)
def work2():
# 在 work1 线程中修改了全局变量 g_num 的值,
# 也影响了 work2 中全局变量 g_num 的值;
global g_num
print("---in work2, g_num is %d---" %g_num)
if __name__ == "__main__":
print("---线程创建之前 g_num is %d---" %g_num)
# 创建子线程对象,指定线程执行的目标对象为 work1 函数
t1 = Thread(target=work1)
t1.start() # 启动子线程
# 延迟 1 秒,保证上一个线程先执行
time.sleep(1)
t2 = Thread(target=work2)
t2.start()多线程共享全局变量,还可以通过将全局变量传入到线程中实现:注意,此方法只对可变类型的数据有效;
# 导入 threading 模块中的 Thread 类
from threading import Thread
import time
# 声明一个整数类型的全局变量(不可变类型)
g_num = 100
# 声明一个列表类型的全局变量(可变类型)
g_nums = [11, 22, 33]
# 声明两个函数 work1 和 work2,在子线程中执行
def work1(g_num, g_nums):
# 在子线程中修改传入进来的变量
g_num += 100
g_nums.append(44);
print("in work1, g_num is:", g_num)
print("in work1, g_nums is:", g_nums)
def work2(g_num, g_nums):
# 因为 g_num 是整形的,是不可变类型,那么在 work1 线程中
# 修改 g_num 变量的值,并不会改变外部全局变量 g_num 的值;
print("in work2, g_num is:", g_num)
# 而 g_nums 是列表类型,是可变类型,那么 在 work1 线程中
# 修改 g_nums 的值,会导致外部全局变量 g_nums 的值也跟着
# 改变,那么传入 work2 线程中的 g_nums 的值就是改变后的新值;
print("in work2, g_nums is:", g_nums)
if __name__ == "__main__":
print("线程创建之前 g_num is:", g_num)
print("线程创建之前 g_nums is:", g_nums)
# 创建子线程对象,指定线程执行的目标对象为 work1 函数
# args 参数表示传入到线程中的数据,以元祖的形式表示;
t1 = Thread(target=work1, args=(g_num, g_nums))
t1.start() # 启动子线程
# 延迟 1 秒,保证上一个线程先执行
time.sleep(1)
t2 = Thread(target=work2, args=(g_num, g_nums))
t2.start()
多线程共享全局变量可能会遇到的问题:
先看下面一段代码:
# 导入 threading 模块的 Thread 类
from threading import Thread
import time
# 声明一个全局变量
g_num = 0;
# 定义两个方法,分别在两个方法中对全局变量 g_num 自加 100万次
def work1():
global g_num
for i in range(1000000):
g_num += 1
print("work1 ---- g_num:", g_num)
def work2():
global g_num
for i in range(1000000):
g_num += 1
print("work2 ---- g_num:", g_num)
if __name__ == "__main__":
# 创建子线程,并指定子线程执行的对象
t1 = Thread(target=work1)
t1.start()
# time.sleep(3) # 延迟 3 秒
t2 = Thread(target=work2)
t2.start()输出结果:

如果把代码中 time.sleep(3) 延迟注释放开,输出结果变成了:

那么为什么会有两种不同的结果呢???
先看第二种结果:线程1 先执行,然后延迟了 3 秒,在这3秒时间里,足够线程1执行结束,所以线程1中输出 g_num 的值为 1000000,此时全局变量 g_num 的值也是 1000000;在3秒延迟结束之后,开始执行线程2,那么此时线程2中的 g_num 变量的初始值就是 1000000,然后再让其自加 100万次,所以最终线程2中 g_num 变量的值为 2000000;
那么为什么把延迟3秒注释掉,结果就不对了呢?这是因为,没有延迟的时候,两个线程同时执行,那么两个线程就会同时操作全局变量 g_num;而我们知道,线程的执行顺序是不确定的,那么就有可能会出现这么一个情况:假如 g_num = 100 的时候,线程1抢到了执行权,于是线程1获取到 g_num 变量,此时线程1中 g_num 变量的值为 100,但是线程1还没来得及给 g_num 加1,线程2又抢到了执行权,那么此时线程2获取到的 g_num 的值也是 100,然后线程2给 g_num 加1之后,全局变量 g_num 的值变成了 101;然后线程1又抢到了执行权,虽然全局变量的值已经变成了 101,但是线程1之前已经获取到了 g_num,而且 g_num 的值为 100,于是线程1给 g_num 加1后,又再次把全局变量的值变成了 101;所以,虽然线程1和线程2都对 g_num 完成了一次加1操作,但是实际上全局变量 g_num 的值只是增加了 1,并没有增加 2.
问题产生的原因就是没有控制多个线程对同一资源的访问,对数据造成了破坏,使得线程运行的结果不可预期,这种情况叫做 “线程不安全”。
解决这种线程安全问题的办法是:线程同步;同步的意思是协同步调,即按照约定的先后顺序依次执行;而不是同时执行的意思。
而线程同步的具体实施方案是:对共享资源添加互斥锁;互斥锁的原理如下:
1、当线程1获取到执行权的时候,给全局变量 g_num 添加一把锁,让其他线程不能操作该变量;
2、当线程1操作完全局变量 g_num 之后,将该锁解开,允许其他线程操作该变量;
3、同理,线程2操作 g_num 的时候,也给 g_num 添加一把锁,不允许其他线程操作;
这样就能保证,同一时间,只有一个线程可以操作共享资源了。
互斥锁 Lock:
threading 模块中提供了 Lock 类用于对共享资源的锁定;
# 导入 threading 模块的 Thread 类和 Lock 类
from threading import Thread, Lock
import time
# 声明一个全局变量
g_num = 0;
# 定义两个方法,分别在两个方法中对全局变量 g_num 自加 100万次
def work1():
global g_num
for i in range(1000000):
# 当前线程抢到执行权的时候,对共享资源进行锁定,
# 即锁内的代码在执行的时候,其他的线程等待,直到解锁;
# 参数 True 表示阻塞,即如果对共享资源进行锁定的时候,
# 如果资源已经上锁了,则等待,直到该资源解锁为止(默认值);
# 如果参数为 False,则表示非阻塞,即不管本次对共享资源
# 上锁能不能成功,都不会卡在这里,而是继续向下执行;
mutex.acquire(True)
g_num += 1
# 对共享资源进行解锁
mutex.release()
print("work1 ---- g_num:", g_num)
def work2():
global g_num
for i in range(1000000):
mutex.acquire() # 上锁
g_num += 1
mutex.release() # 解锁
print("work2 ---- g_num:", g_num)
if __name__ == "__main__":
# 创建一个互斥锁,这个锁默认是没有上锁的
mutex = Lock()
# 创建子线程,并指定子线程执行的对象
t1 = Thread(target=work1)
t1.start()
t2 = Thread(target=work2)
t2.start()上锁的原则:上面的代码也可以将锁加在 for 循环的外面,如下所示:
def work1():
global g_num
# 将锁上在 for 循环外面
mutex.acquire(True) # 上锁
for i in range(1000000):
g_num += 1
mutex.release() # 解锁
print("work2 ---- g_num:", g_num)但是这样的话,多线程的任务就变成了单线程的任务,每个线程从头到尾执行完,再执行下一个线程;所以一般来说,上锁的代码越少越好,一般只在必须加锁的位置上锁,尽量不要把不必要的代码也放到锁里。
锁的坏处:
1、阻止了多线程并发执行,包含锁的某段代码实际上是以单线程模式执行,效率就降低了;
2、由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁;
死锁:
在线程中共享多个资源的时候,如果两个线程分别占有一部分资源,并且同时等待对方的资源,就会造成死锁;下面代码用来演示死锁的产生:
# 导入 threading 模块
import threading
import time
# 自定义一个类,继承于 Thread 类
class MyThread1(threading.Thread):
# 重写 Thread 类中的 run 方法
def run(self):
# 先对 mutexA 锁进行上锁
if mutexA.acquire():
print(self.name+'----do1---up----')
time.sleep(1)
# 再对 mutexB 锁进行上锁
if mutexB.acquire():
print(self.name+'----do1---down----')
mutexB.release()
mutexA.release()
class MyThread2(threading.Thread):
def run(self):
# 先对 mutexB 锁进行上锁
if mutexB.acquire():
print(self.name+'----do2---up----')
time.sleep(1)
# 再对 mutexA 锁进行上锁
if mutexA.acquire():
print(self.name+'----do2---down----')
mutexA.release()
mutexB.release()
if __name__ == '__main__':
# 创建两个互斥锁
mutexA = threading.Lock()
mutexB = threading.Lock()
# 创建两个子线程
t1 = MyThread1()
t2 = MyThread2()
t1.start()
t2.start()输出结果:
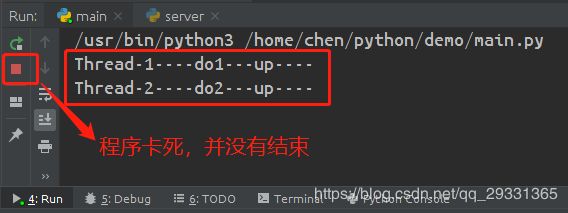
产生死锁的原理是:

解决死锁的办法有:
1、程序设计时尽量避免;
2、添加超时时间:acquire([blocking[, timeout]]) 有两个参数,blocking 参数在上面介绍互斥锁的时候已经说了,timeout 参数就是超时时间;如果调用 acquire 方法的时候没有参数,默认是阻塞的,并且是无休止等待的;如果加了 timeout 参数,比如 acquire(3),就表示只等待 3 秒钟,3 秒钟之后不管有没有上锁成功,都会继续向下执行;
生产者与消费者模式:
-
为什么要使用生产者与消费者模式:
在线程的世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
-
什么是生产者与消费者模式:
生产者与消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。
在 Python学习笔记(二十七):进程间通信 Queue 文章中,我们已经知道,多进程之间进行通信,可以通过 multiprocessing 模块中的 Queue 类来实现;
而多线程之间的通信可以通过 queue 模块中的 Queue 类来实现(在 python2 中,模块名为 Queue);
多线程通信使用的 queue 模块中的 Queue 类和多进程通信使用的 multiprocessing 模块中的 Queue 类,具有相同的方法;
使用 Queue 实现生产者与消费者的案例如下:
# 从 queue 模块中导入 Queue 类
from queue import Queue
# 如果是 python2,模块名为 Queue
# from Queue import Queue
# 导入 threading 模块中的 Thread 类
from threading import Thread
import time
# 生产者类:生产产品
class Producer(Thread):
# 重写 Thread 类的 run 方法
def run(self):
count = 0
while True:
# 如果队列中的产品数量小于1000,就开始生产
if queue.qsize() < 1000:
# 每次生产100个
for i in range(100):
count = count + 1
msg = self.name + " 生成产品 " + str(count)
queue.put(msg) # 将生成的产品放入队列中
print(msg)
else:
# 如果队列中产品数量大于1000,生产者就休息一会,
# 停止生产,等产品被消费到 1000 以下了,再继续生产
time.sleep(1)
# 消费者类:消费产品
class Consumer(Thread):
def run(self):
while True:
# 如果队列中的产品数量大于100,就开始消费
if queue.qsize() > 100:
# 每次消费 3 个
for i in range(3):
# 从队列中取出产品
msg = self.name + " 消费了" + queue.get()
print(msg)
else:
# 如果队列中产品数量低于100,消费者就休息一会,停止消费,
# 等队列中产品数量大于100了,再继续开始消费;
time.sleep(1)
if __name__ == "__main__":
# 创建一个队列
queue = Queue()
# 创建了 500 个初始产品放到队列中
for i in range(500):
queue.put("初始产品:" + str(i))
# 创建了两个生产者,生产产品
for i in range(2):
p = Producer()
p.start()
# 创建了五个消费者,消费产品
for i in range(5):
c = Consumer()
c.start()
ThreadLocal:
在多线程环境下,每个线程都有自己的数据,一个线程使用自己独有的局部变量比使用全局变量好,因为局部变量只有自己能看见,不会影响其他线程,而全局变量的修改必须加锁;但是局部变量也有问题,就是在函数调用的时候,传递来传递去很麻烦;而 ThreadLocal 就是用来解决这类问题的。
ThreadLocal 本身是一个全局变量,但是每个线程都可以用它来保存自己的私有数据,这些私有数据对其他线程是不可见的。ThreadLocal 在每一个线程中都会创建一个副本,每个线程都可以访问自己内部的副本变量。
import threading
# 创建全局 ThreadLocal 对象
localStudent = threading.local()
def process_student():
# 获取当前线程关联的 studentName;
# ThreadLocal 中绑定的跟线程有关的数据,对其他线程是不可见的;
studentName = localStudent.studentName
print('Hello, %s (in %s)' % (studentName, threading.currentThread().name))
def process_thread(name):
# 将 studentName 绑定到 localStudent;
# 每个线程都可以将自己的私有数据绑定到 ThreadLocal;
localStudent.studentName = name
process_student()
if __name__ == "__main__":
# 创建两个子线程,传入 name 参数
t1 = threading.Thread(target=process_thread, args=('jack',), name='Thread-A')
t1.start()
t2 = threading.Thread(target=process_thread, args=('lucy',), name='Thread-B')
t2.start()
线程池:
当程序中需要创建大量生存期很短暂的线程时,一个一个的创建,成本是比较高的,因为每个线程的创建和消亡,都需要消耗时间和资源,此时就可以使用线程池来解决;
线程池在创建时,池中就创建了一定数量空闲的线程,程序只要将一个函数提交给线程池,线程池就会启动一个空闲的线程来执行它;当该线程执行结束后,该线程并不会死亡,而是再次返回到线程池中,变成空闲状态;
python3 中可以使用 concurrent.futures 模块来实现线程池的应用,也可以使用 threadpool 模块,不过 threadpool 是第三方模块,需要手动安装;而且 threadpool 模块是老版本的,新版本推荐使用 concurrent.futures 模块,是 python3 自带的;
线程池的基类是 concurrent.futures 模块中的 Executor,Executor 提供了两个子类,即 ThreadPoolExecutor 和 ProcessPoolExecutor,分别用于创建线程池和进程池;
Executor 提供了如下方法:
-
submit(fn, *args, **kwargs):将 fn 函数提交给线程池。args 代表传给 fn 函数的参数,kwargs 代表以关键字参数的形式为 fn 函数传入参数。
-
map(func, *iterables, timeout=None, chunksize=1):该函数类似于全局函数 map(func, *iterables),只是该函数将会启动多个线程,以异步方式立即对 iterables 执行 map 处理。
-
shutdown(wait=True):关闭线程池;参数 wait 默认值为 True,表示等待线程池中的任务全部执行结束,再向下执行;如果为 False,则不等待;
程序将任务函数提交(submit)给线程池后,submit 方法会返回一个 Future 对象;由于任务函数会在子线程中以异步方式执行,因此,任务函数相当于一个 “将来完成” 的任务,所以 python 使用 Future(未来) 来表示;
Future 类提供了如下方法:
-
cancel():取消该 Future 代表的线程任务;如果该任务正在执行,则不可取消,该方法返回 False;否则,程序会取消该任务,并返回 True;
-
cancelled():判断 Future 代表的线程任务是否被成功取消;如果被成功取消,返回 True;
-
running():判断 Future 代表的线程是否正在执行;如果正在执行,返回 True;
-
done():判断 Future 代表的线程是否已经完成;如果已经完成,返回 True;
-
result(timeout=None):获取 Future 代表的线程最后返回的结果;如果线程任务还未完成,该方法会阻塞当前线程,timeout 参数指定最多阻塞多少秒;
-
exception(timeout=None):获取 Future 代表的线程返回的异常;如果线程成功完成,没有异常,返回 True;
-
add_done_callback(fn):为 Future 代表的线程注册一个回调函数,当线程执行结束时,会自动触发回调函数;
在用完一个线程池后,应该调用线程池的 shutdown 方法,该方法将关闭线程池,不再接收新任务,但会将之前提交的所有任务执行完成。
# 导入线程池模块中的 ThreadPoolExecutor 类和 Future 类
from concurrent.futures import ThreadPoolExecutor, Future
# 导入线程模块
import threading
import time
# 声明一个函数,用于在子线程中执行
def work(i):
print("线程 %s 开始执行 任务%d" %(threading.currentThread().name, i))
time.sleep(1)
# 回调函数:线程执行结束会自动触发执行
def callFunc(future):
print(threading.currentThread().name + " 执行结束")
if __name__ == "__main__":
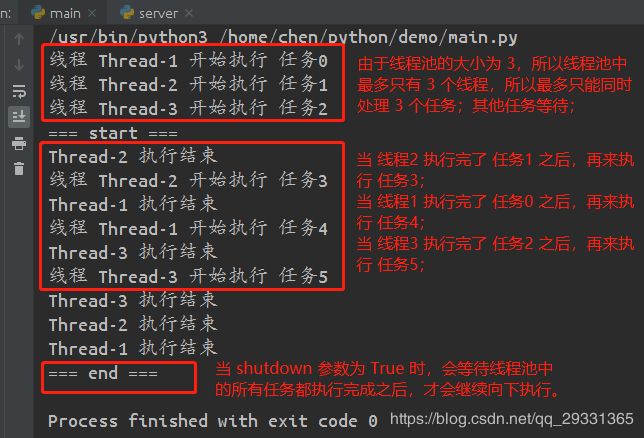
# 创建线程池对象,最大线程数为 3,即线程池中最多存在 3 个子线程
pool = ThreadPoolExecutor(3)
# 循环提交 6 个任务给线程池执行
for i in range(6):
# 将任务函数提交给线程池,并传入参数到任务函数中;
# 如果提交的任务数量大于线程池中的线程数量,那么
# 多余的任务会等待,等待线程池中的线程执行完之前
# 的任务之后,再来执行等待的新任务;
# 返回 Future 对象
future = pool.submit(work, i)
# 为线程添加回调函数,默认将 future 对象传入到回调函数中
future.add_done_callback(callFunc)
print("=== start ===")
# 关闭线程池,不再接收新的任务;
# 默认参数为 True,表示等待线程池中的所有任务执行结束后,
# 再向下执行,下面的 end 会最后输出;
# 如果为 False,则表示不等待,那么 end 会先输出;
pool.shutdown(True)
print("=== end ===")输出结果: