eBPF & bcc教程(二)
更多文章目录:点击这里
GitHub地址:https://github.com/ljrkernel
上一篇博客简单介绍了 eBPF 并介绍了 bcc 框架的安装及简单应用,本篇开始实战,动手写 bcc 程序。先来一个简单的bcc 程序,作用为探测 sys_sync ,检测到 sync 时打印出“sys_sync() called”。sys_sync系统调用被用户空间函数调用,用来将内核文件系统缓冲区的所有数据写入存储介质,sys_sync系统调用将buffer、inode和super在缓存中的数据写入设备。
在此之前,先来点题外话,笔者看到 sys_sync 系统调用就想了解一下,此处介绍的内容与 bcc 关系不大,只想了解 bcc 的读者可以直接往后看。关于sys_sync系统调用在linux-5.0\fs\sync.c中先看如下代码:
void ksys_sync(void)
{
int nowait = 0, wait = 1;
wakeup_flusher_threads(WB_REASON_SYNC);
iterate_supers(sync_inodes_one_sb, NULL);
iterate_supers(sync_fs_one_sb, &nowait);
iterate_supers(sync_fs_one_sb, &wait);
iterate_bdevs(fdatawrite_one_bdev, NULL);
iterate_bdevs(fdatawait_one_bdev, NULL);
if (unlikely(laptop_mode))
laptop_sync_completion();
}
SYSCALL_DEFINE0(sync)
{
ksys_sync();
return 0;
}
可以看到SYSCALL_DEFINE0(sync)函数中调用了ksys_sync();,实际上它会扩展为asmlinkage long sys_sync(),asmlinkage 告诉编译器 sys_sync 函数通过堆栈而不是通过寄存器传递参数,尽管该函数并不接收任何参数。
且看 asmlinkage 宏定义,在linux-5.0\arch\x86\include\asm\linkage.h中定义如下:
#ifdef CONFIG_X86_32
#define asmlinkage CPP_ASMLINKAGE __attribute__((regparm(0)))
#endif /* CONFIG_X86_32 */
其中 attribute 是关键字,是gcc的c语言扩展。__attribute__机制是GNU C的一大特色,它可以设置函数属性、变量属性和类型属性等。可以通过它们向编译器提供更多数据,帮助编译器执行优化等。
__attribute__((regparm(0)))告诉gcc编译器该函数不需要通过任何寄存器来传递参数,参数只是通过堆栈来传递。
__attribute__((regparm(3)))告诉gcc编译器这个函数可以通过寄存器传递多达3个的参数,这3个寄存器依次为EAX、EDX 和 ECX。更多的参数才通过堆栈传递。这样可以减少一些入栈出栈操作,因此调用比较快。
asmlinkage 大都用在系统调用中。有一些情况下是需要明确的告诉编译器,我们是使用stack来传递参数的,比如x86中的系统调用,是先将参数压入stack以后调用sys_*函数的,所以所有的sys_*函数都有asmlinkage来告诉编译器不要使用寄存器来编译。
gcc编译器在汇编过程中调用c语言函数时传递参数有两种方法:一种是通过堆栈,另一种是通过寄存器。缺省时采用寄存器,假如要在汇编过程中调用c语言函数,并且想通过堆栈传递参数,定义的c函数时要在函数前加上宏asmlinkage。
下图可以看到 sync 在系统调用表中的情况:

好了,题外话完了正式开始我们的 eBPF & bcc 程序,这个特殊的,可以同时出现 python 和 C 语言的程序,先上代码:
#!/usr/bin/python
from bcc import BPF
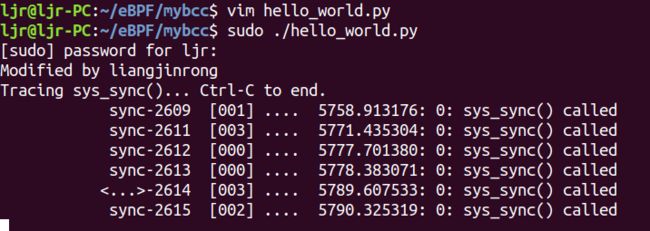
print("Modified by liangjinrong")
print("Tracing sys_sync()... Ctrl-C to end.")
BPF(text='int kprobe__sys_sync(void *ctx) { bpf_trace_printk("sys_sync() called\\n"); return 0; }').trace_print()
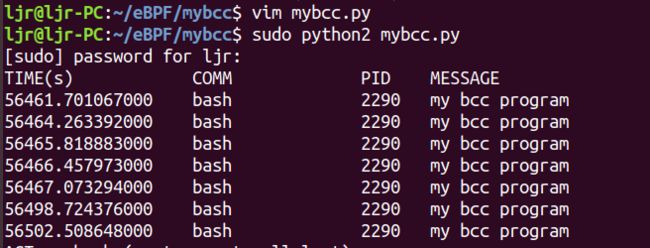
此程序作用是检测到 sync 时打印出“sys_sync() called”,运行此程序,打开另一终端,多次输入sync 回车后,运行结果如下:
上面只是一个简单的 bcc 程序,下面我们写一个更加规范化的例程:
from bcc import BPF
# define BPF program
prog = """
int hello(void *ctx) {
bpf_trace_printk("my bcc program\\n");
return 0;
}
"""
# load BPF program
b = BPF(text=prog)
b.attach_kprobe(event=b.get_syscall_fnname("clone"), fn_name="hello")
# header
print("%-18s %-16s %-6s %s" % ("TIME(s)", "COMM", "PID", "MESSAGE"))
# format output
while 1:
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
except ValueError:
continue
print("%-18.9f %-16s %-6d %s" % (ts, task, pid, msg))
本例程通过 sys_clone() 跟踪新进程的创建,下面进行程序分析:
prog = """ xxx ""此处通过变量声明了一个 C 程序源码,其中xxx是可以换行的 C 程序。int hello() { xxx }声明了一个 C 语言函数,未使用上个例子中 kprobe__ 开头的快捷方式。BPF 程序中的任何 C 函数都需要在一个探针上执行,因此我们必须将 pt_reg* ctx 这样的 ctx 变量放在第一个参数。如果需要声明一些不在探针上执行的辅助函数,则需要定义成 static inline 以便编译器内联编译。有时候可能需要添加 _always_inline 函数属性。b.attach_kprobe(event=b.get_syscall_fnname("clone"), fn_name="hello")这里建立了一个内核探针,内核系统出现 clone 操作时执行 hello() 这个函数。可以多次调用attch_kprobe(),这样就可以用 C 语言函数跟踪多个内核函数。b.trace_fields()这里从trace_pipe返回一个混合数据,这对于黑客测试很方便,但是实际工具开发中需要使用BPF_PERF_OUTPUT()。
运行程序后,打开另一终端多次输入 ls ,可以看到程序与进行结果如下: