显著性目标检测之Label Decoupling Framework for Salient Object Detection

文章目录
- 摘要
- 网络详解
- Label Decoupling
- 特征提取
- Feature Interaction Network
- 损失函数
- 实验结果
- 实验细节
- 消融实验
- 对比其他方法
- 总结
摘要
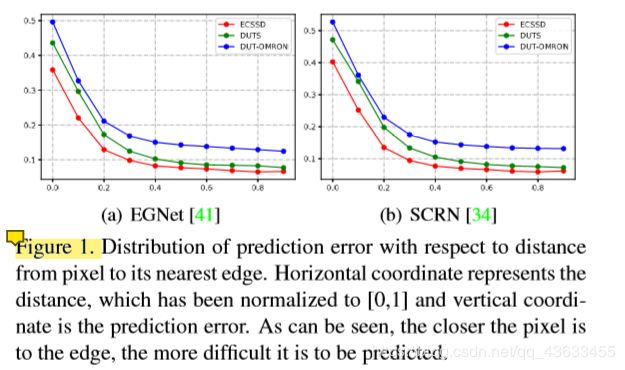
现存问题:下图为两个目前比较好检测方法的预测误差随像素到其最近边缘的距离的分布。横坐标表示距离,已归一化为[0,1],纵坐标为预测误差。可以看出,像素越靠近边缘,越难预测。传统的显著性标签对显著性目标内部的像素都是同等对待的,这可能会导致预测误差较小的像素受到边缘的干扰;
提出方法:Label Decoupling Framework,该网络主要包含以下两部分:
- 标签解耦(LD):通过LD过程,特征图像被分离为两部分:主体和边缘细节。细节图由边缘和附近的像素组成,充分利用了近边缘的像素,使像素分布更加均衡。主题映射主要集中在远离边缘的像素上。
- 特征交互网络(FIN):FIN有两个分支,分别适用于主体图和细节图。将两个互补的分支融合在一起预测显著性映射,然后利用显著性映射对两个分支进行再次细化。这种迭代精化过程有助于获得逐渐精确的显著性图预测,促进分支之间的迭代信息交换。
网络详解
在这一部分要详细讲述网络的组成以及每部分的构造原理
整体网络架构:

Label Decoupling
正如上文提及的,作者根据边缘与中心区域各自的特点进行处理更为合理而不是平等的对待这些像素,如上图所示,是应用LD将图像分为两部分。为了实现这一目标,我们引入了距离变换(DT)来解耦原始标签,这是一种传统的图像处理算法。DT可以将二值图像转换为新图像,其中每个前景像素都有一个值,该值对应于通过距离函数得到的与背景的最小距离。
DT:DT的输入是二值图像,即可以被表示成两部分的的图像(如前景Ifg和背景Ibg),对于每个像素p, I[p]是其对应的值。如果p∈Ifg, I[p] = 1,如果p∈Ibg,I[p] = 0。为了得到图像I的DT结果,我们定义度量函数f(p,q) = √ ̄[(px−qx)2 + (py−qy)2]来度量像素之间的距离。如果像素p属于前景,DT首先查找其在背景中最近的像素q,然后使用f(p,q)计算像素p与q的距离,如果像素p属于背景,则将其最小距离设为零。我们使用f(p,q)作为新生成图像的像素点,距离变换可以表示为:

经过距离变换后,原始图像I被变换为I’,其中像素值I’[p]不再等于0或1。再经过线性变换,将其值缩小在[0,1]。
经过以上步骤,I’的像素值不仅取决于它是属于前景还是背景,还与它的相对位置有关。位于物体中心的像素值最大,远离中心或背景的像素值最小。所以I’代表原始图像的主体部分,主要集中在相对容易的中心像素上。在接下来的实验中,我们使用它作为主体标签。与之对应的是,将主体图像I’从原始图像I中去除,得到的是细节图像,在后续的实验中,将其作为细节标签,主要集中在远离主要区域的像素上。另外,将新生成的标签与原始二值图像I相乘,用来去除背景干扰(BL代表主体部分,DL代表细节图):

特征提取
使用Rst-Net50作为主框架,删除了完全连接层,保留了所有卷积块。对于一幅形状为H×W的输入图像,由于下采样,该主干会生成5个尺度的特征,其空间分辨率会以2为因子降低,用F = {Fi|i = 1,2,3,4,5}代表这些特征图。研究表明,低层次特征极大地增加了计算代价,所以我们只利用{Fi|i = 2,3,4,5}的特征,如图2所示。对这些特征分别采用两个卷积层,分别适应主体预测任务和细节预测任务。然后我们得到两组特征B = {Bi|i = 2,3,4,5}和D = {Di|i = 2,3,4,5},这两组特征都被压缩到64个信道发送到解码器网络进行显著性映射生成。
Feature Interaction Network
图中橙色部分
组成:由上文可知,由于主体图和细节图都是由同一显著性标签派生而来,因此两个分支的特征之间存在一定程度的相似性和互补性。因此在互补的分支之间引入特性交互[FIN],以进行信息交换。总体上,该框架由一个主干编码器网络、一个交互编码器网络、一个体解码器网络和一个细节解码器网络组成。
引入原因:对于特征B,采用主体解码器网络来生成主体映射。同样,对于特征D,使用细节解码器网络来生成细节映射。在得到这两个分支的输出特性之后,处理它们的最简单的方法是连接这些特性并应用卷积层来得到最终的显著性映射。但是,这种方法忽略了分支之间的关系。为了显式地促进分支之间的信息交换,引入了交互编码器网络。
具体地说,交互解码器以主体解码器和细节解码器的连接特征为输入。它堆叠多个卷积来提取多层次的特征。然后将这些多层次的特征应用于3x3卷积层,使其分别适用于主体解码器和细节解码器。
损失函数
训练损失定义为所有迭代的输出之和,即:
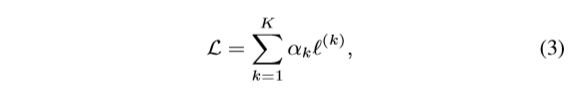
ℓ(k)的损失是第k次迭代,k表示迭代总数,αk是每次迭代的重量。为了简化问题,我们设迭代k = 1来平等地对待所有迭代。对于每个迭代,我们将得到三个输出(即。每一个都对应着一个损失。所以ℓ(k)可以被定义为的结合三个损失如下:
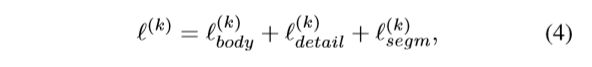
ℓsegm(k)代表分割损失,直接利用二进制交叉熵(BCE)计算ℓbody(k)和ℓdetail(k)。BCE是二值分类和分割中广泛使用的损失,即
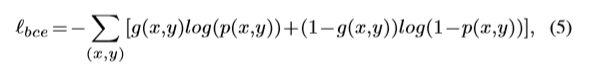
其中g(x,y)∈[0,1]为像素(x,y)的真值, p(x,y)∈[0,1]为预测为显著对象的概率。而BCE独立计算每个像素的损失,忽略了图像的全局结构。为了纠正这个问题,所显示[23]我们利用LoU损失计算ℓsegm(k),它可以衡量两幅图像的相似度总体上而不是单个像素。定义为:

实验结果
实验细节
将ResNet-50主干的最大学习速率设置为0.005,其他部分设置为0.05,利用随机梯度下降(SGD)对整个网络进行端到端的训练。动量衰减和重量衰减分别设置为0.9和0.0005。批处理大小设置为32,最大历元设置为48。在测试过程中,每张图像被简单地调整为352 x 352,然后送入网络进行预测,而不进行任何后处理。值得注意的是,输出显著性映射用于预测,而不是添加预测的主体和细节映射。
消融实验
特性交互的数量:表4显示了不同数量特征交互时的性能。与没有特征交互(数量=0)的基线相比,只有一个特征交互的模型取得了更好的效果。数目越大,性能就越差。

监督组合方式:表5展示了不同监管组合下的绩效。从表中可以看出,包含细节标签的组合比包含边标签的组合表现更好,说明了细节标签比边标签的有效性。此外,包含主体标签的组合比包含显著标签(Sal)的组合表现更好。实验证明,在没有边缘干扰的情况下,中心像素可以更好地学习特征表示。

对比其他方法
定量比较:我们比mF和Eξ,MAF等方面比较该方法与其他方法。结果如表2所示:

图4给出了5个数据集上的精确度回忆曲线和f -measure曲线。可以看出,所提方法的曲线始终高于其他方法的曲线。

此外,在图6中计算了不同方法的误差-距离分布,其中,由提出的方法产生的预测在沿距离,特别是在边缘区域的误差最小:

可视化比较:图5显示了所提方法和其他先进方法的一些预测实例。实验表明,该方法不仅能清晰地突出正确的目标区域,而且能很好地抑制背景噪声。它在处理各种具有挑战性的场景,包括杂乱的背景,人造结构和低对比度前景。与其他方法相比,该方法生成的显著性图更加清晰、准确:

不同属性SOC的性能:表3显示了得分。我们可以看到,所提出的模型在除“BO”外的大部分属性中取得了最好的结果,说明了所提出的方法具有较好的泛化性。它可以应用于不同的具有挑战性的场景:

总结
在本文中,作者提出了标签解耦框架用于显著目标检测。实验表明,边缘预测在显著性预测中是一项具有挑战性的任务,提出了将显著性标记解耦为主体映射和细节映射。细节映射帮助模型更好地学习边缘特征,而主体映射避免了像素靠近边缘的干扰。在这两种地图的监督下,该方法比使用显著性地图直接监督效果更好。引入特征交互网络,充分利用体图与细节图的互补性。在六个数据集上的实验表明,在不同的评价指标下,该方法的性能优于现有的方法。