文件路径转化json格式的数据设计思想和源码
本人是一个大三的学生,这个暑假老师给了一个任务,其中有个需求就是将hadoop上的文件树显示到web页面上,这就需要将形如 /project2/a/b 这样的路径转化为如下的格式:
[{
"text":"project2",
"children":
[{
"text":"a",
"children":
[{
"text":"b"
}]
}]
}]
有了数据后直接交给easyui的tree组件渲染,然后生成目录结构:

但是刚开始做的时候,对于如何把路径转化为json,我不会做,也想偷个懒,于是就去网上找现成的代码,最终在本站找到一个老哥的代码:
java 字符串路径集合转换成带有层次结构的JSON
使用他的代码确实可以达到目的,但是后期发现,当目录的层数达到8个以上,程序就会卡死,根据我调试结果来看,貌似是进入了递归死循环(爆栈),因此不得不放弃,还是打算自己写一个方法。
设计思路
我放弃了使用递归的方式。
文件的路径,其实就是树的结构。我们可以从叶子节点,一级一级的往上溯源,从而达到目的,这样做的好处是:不必考虑孩子节点,只需要考虑双亲节点即可。如果从根节点往下,那么对于分支节点就需要考虑双亲和孩子。
节点的形式:
| text | level | parent | id | pid | children |
|---|
对应的实体类:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class tree {
@JSONField(ordinal = 1)
private String text;
@JSONField(serialize=false)
// @ToString.Exclude
private int level;
@JSONField(serialize=false)
// @ToString.Exclude
private String parent;
@JSONField(serialize=false)
// @ToString.Exclude
private int id;
@JSONField(serialize=false)
// @ToString.Exclude
private int pid;
@JSONField(ordinal = 2)
public List<String> children;
}
@JSONField(serialize=false)这个注解是转化为json字符串时排除这个注解所标注的属性,可自行取舍
实体类有了,接下来就要构造json数据了
假设已遍历目录,获得了所有的路径,得到了数据data(网上对于遍历目录的代码很多):
String data = "project1/a project1/a/c project1/a/c/d project1/a/c/d/e project1/a/c/d/f project1/b";
//得到每个路径的数组
List<String> UrlList = Arrays.asList(data.split(" "));
以空格" "为分隔符,转化为数组后,得到urlList:

接下来就到了最重要的一步,构造出每一个对象,这个过程中只能构造出text、level、parent、id、pid,比较复杂的children暂时赋值为空:
List<tree> trees = new ArrayList<>();
Map<String, Boolean> map = new HashMap<>();
Map<String, Integer> map1 = new HashMap<>();
int id = 0;
for (String l : UrlList) {
List<String> temp = Arrays.asList(l.split("/")); //[project1,a]
for (int i = 0; i < temp.size(); i++) {
if (i == 0 && !map.containsKey(temp.get(0) + (i + 1))) {
trees.add(new tree(temp.get(i), i + 1, "null", ++id, 0, null));
map.put(temp.get(0) + (i + 1), true);
map1.put((i + 1) + temp.get(i), id);
}
if (i != 0 && !map.containsKey(temp.get(i) + (i + 1))) {
trees.add(new tree(temp.get(i), i + 1, temp.get(i - 1), ++id, map1.get((i) + temp.get(i - 1)), null));
map.put(temp.get(i) + (i + 1), true);
map1.put((i + 1) + temp.get(i), id);
}
}
}
上面的代码,首先是遍历urlList这个数组,将数组中的每一个路径再以“/”分割存入新的数组temp,我们知道,对于路径
a/b/c,我们能清楚的看出谁是谁的双亲节点和孩子节点,所以分割后存入数组的每个节点,索引值相差为1的一定是父子关系,例如第一次遍历的temp的值为:

那么a一定是project1的孩子节点,project1一定是a的双亲节点!
对于temp,我们再以下标索引进行一次遍历,索引为0,那么一定是root节点,也就是project1。
level为索引值加1
再遍历过程中,一定会遇见重复的对象,例如a/b/c和a/b,其中的b会被构建两次,那么我们就需要一个标记,来记录该对象有没有被构建过。level表示的是树的深度和目录的级数,level相同的对象,text属性就一定不可能相同,换句话说,level和text可以用来作为唯一性的标志。因此在这里引入了map来判断(作用和标记数组相同),键为对象的text+level。
遍历temp时会做一个判断,倘若map中不存在text+level的键,那么就构建该对象,存在则不构造。
同时还引入了另一个map1,用来记录双亲节点的id,也就是pid,当map判断通过构造对象后,存入map1的键为level+text,值为当前对象的id,然后在除了root的构造不用取值,其余的节点都需要取值,取值的键为当前的level-1+上一个text,也就是temp.get(i - 1)。
这个地方不能用id作为pid但参考标准,例如a/b/c和a/b/d,c和d都是b但孩子,但是c和d的id也会递增,所以必须要借助工具。
通过上面的代码,就可以得到一个tree对象的列表了:

有了这个列表,就可以来构造json数据了!
json的转化
这里需要将trees列表按照level倒叙排序,从而达到从叶子节点往根节点的溯源:
trees = trees
.stream()
.sorted(Comparator.comparing(tree::getLevel,Comparator.reverseOrder())).collect(Collectors.toList());
同时还需要一个按照id正序排序的列表,这样就能获取到pid后,直接把pid作为索引来获取到双亲节点的对象了:
List<tree> collect = trees
.stream()
.sorted(Comparator.comparing(tree::getId)).collect(Collectors.toList());
转化的代码:
for (tree c : trees) {
System.out.println(c);
int pid = c.getPid() -1;
int id1 = c.getId() -1;
if (pid > 0){
if(collect.get(pid).children == null){
collect.get(pid).children = new ArrayList<>();
}
collect.get(pid).children.add(JSON.toJSONString(collect.get(id1)));
}else {
collect.get(0).children = new ArrayList<>();
for (tree cc : collect){
if (cc.getLevel() == 2){
collect.get(0).children.add(JSON.toJSONString(collect.get(cc.getId()-1)));
}
}
}
}
遇到的坑:
1、大家可能注意到了,添加孩子节点时我没有直接添加对象,而是添加孩子节点的json字符串,这是因为直接添加对象的话,最后获得的root节点对象是没问题的,但是转化为json时会报错:java.lang.StackOverflowError,这是因为fastjson转化时会调用对象的toString()方法,对于root节点的对象,他的children属性又包含了多个tree对象,所以会同时调用多个tree类的toString()方法,导致报错。
2、转化后的json中出现了$ref这样的玩意儿,上网查了查,这个是对象重复引用的问题,归根结底还是因为我存对象的原因,因此最后我还是改成了存json字符串。
3、因为存的是json字符串,最终的json里面后很多个反斜杠\:
[{"text":"project1","children":["{\"text\":\"a\",\"children\":[\"{\\\"text\\\":\\\"c\\\",\\\"children\\\":[\\\"{\\\\\\\"text\\\\\\\":\\\\\\\"d\\\\\\\",\\\\\\\"children\\\\\\\":[\\\\\\\"{\\\\\\\\\\\\\\\"text\\\\\\\\\\\\\\\":\\\\\\\\\\\\\\\"e\\\\\\\\\\\\\\\"}\\\\\\\",\\\\\\\"{\\\\\\\\\\\\\\\"text\\\\\\\\\\\\\\\":\\\\\\\\\\\\\\\"f\\\\\\\\\\\\\\\"}\\\\\\\"]}\\\"]}\"]}","{\"text\":\"b\"}"]}]
问题的原因是添加孩子节点的json字符串时,会在最外围添加上双引号",所以,最后只需要把["{…}"]这种中括号和打括号之间的双引号去掉,然后再把反斜杠\去掉就ok了!
System.out.println(jsonString
.replaceAll("\"\\{","{")
.replaceAll("\\\\","")
.replaceAll("}\"","}"));
结果:
![]()
对于比较复杂的结构,也能胜任:
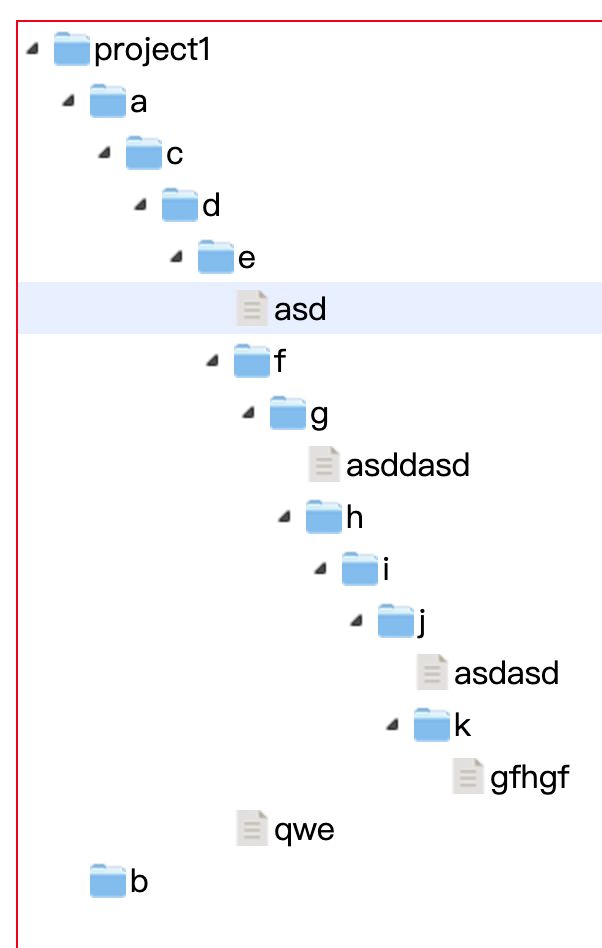
json数据为:
[{"text":"project1","children":[{"text":"a","children":[{"text":"c","children":[{"text":"d","children":[{"text":"e","children":[{"text":"asd"},{"text":"f","children":[{"text":"g","children":[{"text":"asddasd"},{"text":"h","children":[{"text":"i","children":[{"text":"j","children":[{"text":"asdasd"},{"text":"k","children":[{"text":"gfhgf"}]}]}]}]}]}]},{"text":"qwe"}]}]}]}]},{"text":"b"}]}]
这样就大功告成了!转化的属性值我只需要text和children,其余的做了排除,文章开头有说。
整体代码:
public class json {
public static String getJson(List<String> UrlList){
System.out.println(UrlList);
List<tree> trees = new ArrayList<>();
Map<String, Boolean> map = new HashMap<>();
Map<String, Integer> map1 = new HashMap<>();
int id = 0;
for (String l : UrlList) {
List<String> temp = Arrays.asList(l.split("/")); //[project1,a]
for (int i = 0; i < temp.size(); i++) {
if (i == 0 && !map.containsKey(temp.get(0) + (i + 1))) {
trees.add(new tree(temp.get(i), i + 1, "null", ++id, 0, null));
map.put(temp.get(0) + (i + 1), true);
map1.put((i + 1) + temp.get(i), id);
}
if (i != 0 && !map.containsKey(temp.get(i) + (i + 1))) {
trees.add(new tree(temp.get(i), i + 1, temp.get(i - 1), ++id, map1.get((i) + temp.get(i - 1)), null));
map.put(temp.get(i) + (i + 1), true);
map1.put((i + 1) + temp.get(i), id);
}
}
}
trees = trees.stream().
sorted(Comparator.comparing(tree::getLevel,Comparator.reverseOrder())).collect(Collectors.toList());
List<tree> collect = trees.stream().
sorted(Comparator.comparing(tree::getId)).collect(Collectors.toList());
int maxLevel = trees.size();
tree t = new tree();
for (tree c : trees) {
System.out.println(c);
int pid = c.getPid() -1;
int id1 = c.getId() -1;
if (pid > 0){
if(collect.get(pid).children == null){
collect.get(pid).children = new ArrayList<>();
}
collect.get(pid).children.add(JSON.toJSONString(collect.get(id1)));
}else {
collect.get(0).children = new ArrayList<>();
for (tree cc : collect){
if (cc.getLevel() == 2){
collect.get(0).children.add(JSON.toJSONString(collect.get(cc.getId()-1)));
}
}
}
}
tree res = collect.get(0);
String jsonString = JSON.toJSONString(res, SerializerFeature.DisableCircularReferenceDetect);
JSONObject jsonObject = JSON.parseObject(jsonString, Feature.OrderedField);
String json = "["+jsonString
.replaceAll("\"\\{","{")
.replaceAll("\\\\","")
.replaceAll("}\"","}") +"]";
System.out.println(json);
return json;
}
}
效率
这种方式不能说效率很高,假设目录和文件的数量为n,按最坏的来算,目录的深度也为n,则第一个循环的时间复杂度为n*n,第二个循环的时间复杂度为n,则整个算法的复杂度为n²,实际情况下,很少出现数量和深度都为n(这样的话每一个目录只有一个子目录);最好的情况,数量为n,深度为1(除了根目录的所有文件目录都在根目录下),则第一个循环的时间复杂度为n,第二个也为n,整体时间复杂度为2n。所以最终取均值为:T(n)=O((n²+2n)/2)=O(n²)。
空间复杂度为:算上urlList、temp、map、map1、tree1、collect,S(n)=O(6n)=O(n)。
总结
这是我第一次写博客!老激动了
学生党,很多知识都不牢固,还很懒(没救了),这次的代码很多地方都有问题,这是肯定的,但是这毕竟是我熬夜独立思考后的成果,做出来的那一刻我还是很开心的,哈哈,所以发个文章纪念一下
大神看见了写的不好的地方,请轻喷(^ - ^)。