【论文阅读-ASAP】ASAP: Adaptive Structure Aware Pooling for Learning Hierarchical Graph Representations
论文地址:https://www.aaai.org/Papers/AAAI/2020GB/AAAI-RanjanE.8336.pdf
代码地址:https://github.com/malllabiisc/ASAP
来源:WWW2020
图神经网络(GNN)已被证明可以有效地建模图结构数据,解决节点分类、链路预测和图分类等任务。最近在定义图中池化概念方面取得了一些进展,模型试图通过向下采样和汇总节点中呈现的信息来生成图级表示。现有的池方法要么不能有效地捕获图的子结构,要么不能轻松地伸缩到大型图。
这篇论文提出的ASAP(自适应结构感知池),是一种稀疏和可区分的池方法,解决了以前的图池架构的局限性。ASAP利用一种新颖的自注意网络和一种修正的GNN公式来捕获给定图中每个节点的重要性。它还学习了一种稀疏软集群分配的节点在每一层有效地池子图形成池图。
模型架构
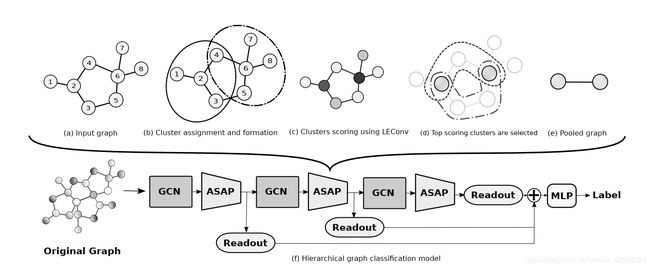
和SAGPool的分层池化结构一致。
(a.)向ASAP输入图表。
(b.) ASAP initial clustering 1-hop neighborhood,考虑所有节点为medoid1。为简便起见,我们仅将节点2和6的簇形成表示为medoid。使用M2T attention计算簇隶属度(参见第4.2节)。
(c.)使用LEConv对集群进行评分。颜色越深表示分数越高。
(d)在合并图中选择得分最高的集群的一部分。利用所选簇成员节点之间的边权重新计算邻接矩阵。
(e) ASAP的输出
(f)层次图分类架构概述。
卷积层
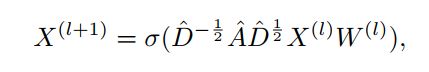
池化层
P首先考虑具有固定接受域的所有可能的局部聚类。然后使用注意机制计算节点的簇成员。然后使用GNN对这些集群进行评分。在合并图中选择一部分得分最高的簇作为节点,并在相邻簇之间计算新的边权值。
Master2Token (M2T)
在给定簇ch(vi)的情况下,通过自注意机制学习簇分配矩阵S。这里的任务是通过关注集群ch(vi)中的相关节点来了解集群ch(vi)的总体表示。这篇论文提出了一种新的自我注意变种,称为Master2Token (M2T)。
首先创建一个代表集群中所有节点的 mi :
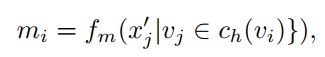
X_q, _ = scatter_max(x_pool_j, edge_index[0], dim=0)
# NxF
M_q = self.lin_q(X_q)
# ExF
# M_q->mi
M_q = M_q[edge_index[0].tolist()]
计算注意力分数:
即,把簇的代表节点mi 作为query,之前的self-attention中query = key = value。
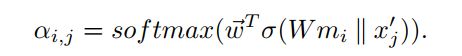
score = self.gat_att(torch.cat((M_q, x_pool_j), dim=-1))
score = F.leaky_relu(score, self.negative_slope)
score = softmax(score, edge_index[0], num_nodes=num_nodes.sum())
聚合:
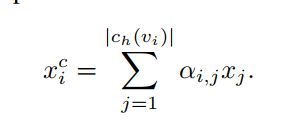
# Sample attention coefficients stochastically.
score = F.dropout(score, p=self.dropout_att, training=self.training)
# 公式7
# ExF
v_j = x_j * score.view(-1, 1)
#---Aggregation---
# NxF
out = scatter_add(v_j, edge_index[0], dim=0)
LEConv
用attention后的节点embding来计算得分,得分函数使用LEConv。LEConv用节点之间的增量来衡量得分。
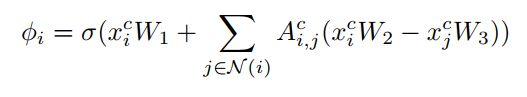
num_nodes = x.shape[0]
h = torch.matmul(x, self.weight)
if edge_weight is None:
edge_weight = torch.ones((edge_index.size(1), ),
dtype=x.dtype,
device=edge_index.device)
edge_index, edge_weight = remove_self_loops(edge_index=edge_index, edge_attr=edge_weight)
deg = scatter_add(edge_weight, edge_index[0], dim=0, dim_size=num_nodes) #+ 1e-10
h_j = edge_weight.view(-1, 1) * h[edge_index[1]]
aggr_out = scatter_add(h_j, edge_index[0], dim=0, dim_size=num_nodes)
out = ( deg.view(-1, 1) * self.lin1(x) + aggr_out) + self.lin2(x)
edge_index, edge_weight = add_self_loops(edge_index=edge_index, edge_weight=edge_weight, num_nodes=num_nodes)
topk
fitness = torch.sigmoid(self.gnn_score(x=out, edge_index=edge_index)).view(-1) #这里的gnn_score即LEConv层
perm = topk(x=fitness, ratio=self.ratio, batch=batch)
x = out[perm] * fitness[perm].view(-1, 1)
更新图
batch = batch[perm]
edge_index, edge_weight = graph_connectivity(
device = x.device,
perm=perm,
edge_index=edge_index,
edge_weight=edge_weight,
score=score,
ratio=self.ratio,
batch=batch,
N=N)
def graph_connectivity(device, perm, edge_index, edge_weight, score, ratio, batch, N):
r"""graph_connectivity: is a function which internally calls StAS func to maintain graph connectivity"""
kN = perm.size(0)
perm2 = perm.view(-1, 1)
# mask contains bool mask of edges which originate from perm (selected) nodes
mask = (edge_index[0]==perm2).sum(0, dtype=torch.bool)
# create the S
S0 = edge_index[1][mask].view(1, -1)
S1 = edge_index[0][mask].view(1, -1)
index_S = torch.cat([S0, S1], dim=0)
value_S = score[mask].detach().squeeze()
# relabel for pooling ie: make S [N x kN]
n_idx = torch.zeros(N, dtype=torch.long)
n_idx[perm] = torch.arange(perm.size(0))
index_S[1] = n_idx[index_S[1]]
# create A
index_A = edge_index.clone()
if edge_weight is None:
value_A = value_S.new_ones(edge_index[0].size(0))
else:
value_A = edge_weight.clone()
fill_value=1
index_E, value_E = StAS(index_A, value_A, index_S, value_S, device, N, kN)
index_E, value_E = remove_self_loops(edge_index=index_E, edge_attr=value_E)
index_E, value_E = add_remaining_self_loops(edge_index=index_E, edge_weight=value_E,
fill_value=fill_value, num_nodes=kN)
return index_E, value_E
Readout
def readout(x, batch):
x_mean = scatter_mean(x, batch, dim=0)
x_max, _ = scatter_max(x, batch, dim=0)
return torch.cat((x_mean, x_max), dim=-1)
xs += readout(x, batch)
分类
x = F.relu(self.lin1(xs))
x = F.dropout(x, p=0.5, training=self.training)
x = self.lin2(x)
out = F.log_softmax(x, dim=-1)
总结
主要是在pool丢弃节点前,进行了attention的聚合,保留了丢弃节点的信息。同时用节点的增量来改进了得分函数