CentOS7安装YOLO 训练自己图片并识别 小白笔记(启用GPU,CUDA,OPENCV)
直接进入主题:
1.查看主机显卡型号:
lspci | grep -i vga
![]()
下载nvidia对应型号驱动:
https://www.nvidia.com/Download/index.aspx?lang
2.使用yum安装lrzsz组件,便于传文件
yum install -y lrzsz
3.关闭防火墙
service firewalld.service stop
chkconfig firewalld off
4.编辑驱动黑名单:
vim /etc/modprobe.d/dccp-blacklist.conf
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off
options nouveau modeset=0
vim /usr/lib/modprobe.d/dist-blacklist.conf
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off
options nouveau modeset=0
6.建立新的镜像
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bak
dracut /boot/initramfs-$(uname -r).img $(uname -r)
7.查看是否在跑 nouveau默认驱动
lsmod | grep nouveau
8.停止XServer服务
init 3
service lightdm stop
9.给nvidia驱动赋权,并执行
chmod +x nvidia.run
sh nvidia.run --no-opengl-files
10.安装 vncserver 以备远程操作 labelimage.
yum install tigervnc tigervnc-server -y
yum groupinstall -y "Desktop" "X Window System"
vncpasswd
vncserver --list
vncserver
systemctl enable vncserver@:1.service
11.安装cuda
去官方选择合适的版本下载
https://developer.nvidia.com/cuda-downloads?target_os=Linux&target_arch=x86_64
选择本地run文件
wget http://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda_10.2.89_440.33.01_linux.run
执行安装:
sh cuda_10.2.89_440.33.01_linux.run
加入环境变量
export PATH=/usr/local/cuda-10.2/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
reboot
测试
nvcc -V
12.安装cuDNN
官方下载对应版本
https://developer.nvidia.com/rdp/cudnn-download
更名
mv cudnn-10.2-linux-x64-v7.6.5.32.solitairetheme8 cudnn.gz
解压缩
tar -vxf cudnn.gz
进入解压缩目录
cd cuda
拷贝到系统对应的目录中
cp include/cudnn.h /usr/local/cuda/include/
cp lib64/libcudnn* /usr/local/cuda/lib64/
chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
删除原软链接
cd /usr/local/cuda/lib64
//删除原来的链接
rm libcudnn.so libcudnn.so.7
//生成新的链接
ln ‐s libcudnn.so.7.4.2 libcudnn.so.7
ln ‐s libcudnn.so.7 libcudnn.so
chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
ldconfig
13.安装OpenCV
官方下载:https://opencv.org/releases/
选择合适版本:
这里我选择3.4.8 https://github.com/opencv/opencv/tree/3.4.8
安装预制软件:
yum -y install epel-release
yum -y install gcc gcc-c++
yum -y install cmake
yum -y install python-devel numpy
yum -y install ffmpeg-devel
编译opencv.
cd opencv
mkdir build
cd build
cmake ..
make
make install
配置opencv:
cd /etc/ld.so.conf.d
添加opencv编译产生的lib库路径到opencv.conf中
/bin/bash -c 'echo "/usr/local/lib64/" > /etc/ld.so.conf.d/opencv.conf'
加载 ldconfig
ldconfig
添加PATH
find / -name "opencv.pc"
/usr/local/lib64/pkgconfig/opencv.pc
vim /etc/bashrc
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib64/pkgconfig/
export PKG_CONFIG_PATH
是配置生效:
source /etc/bashrc
更新库
updatedb
pkg-config配置(存在就不需要操作了)
mkdir -p /usr/local/lib/pkgconfig
默认的pkg搜索链接路径/usr/lib/pkgconfig,需要将opencv.pc拷贝到pkg的默认路径下
cp /usr/local/lib64/pkgconfig/opencv.pc /usr/lib/pkgconfig
14. darknet下载:
git clone https://github.com/pjreddie/darknet
make
开启gpu,opencv,cuda
vim Makefile
GPU=1
CUDNN=1
OPENCV=1
保存后
make clean
make
至此。darknet编译成功。可以开始识别之旅了。
你可以尝试测试识别检测功能:
./darknet detect cfg/yolo.cfg yolo.weights data/dog.jpg
15 labelimage 工具下载及准备:
1.需要先安装 PyQt4
yum install PyQt4
官方下载labelimage
git clone https://github.com/tzutalin/labelImg.git
进如labelimage目录
cd labelimage
编辑默认分类:
vim data/predefined_classes.txt
打开
cd..
python labelimage
\
表示标签
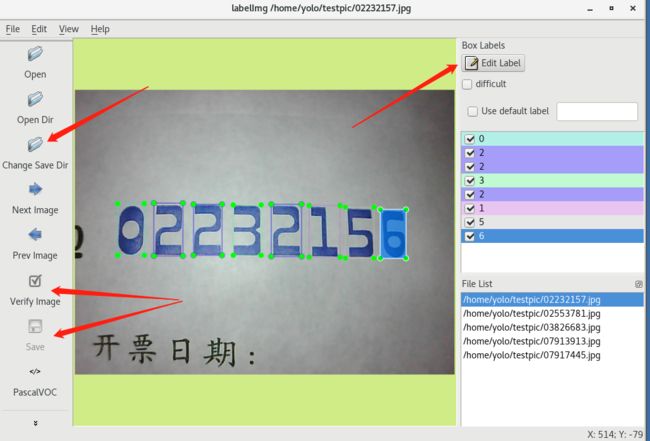
16.创建训练标签图片的文件目录
在darknet下创建文件目录:
mkdir -p VOCdevkit/VOC2007/
mkdir -p VOCdevkit/VOC2007/Annotations/
mkdir -p VOCdevkit/VOC2007/ImageSets/
mkdir -p VOCdevkit/VOC2007/ImageSets/Main/
mkdir -p VOCdevkit/VOC2007/JPEGImages/
mkdir -p VOCdevkit/VOC2007/labels/
17 配置训练
1) 将下面脚本保存到gen_files.py文件并放置到darknet根目录下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
#这个地方根据你的分类自行更改。
classes=["1111","22222"]
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
#size 一定要注意,有的图片在用labelimage做的时候无法生成图片的长宽,是在不行就手工调整一下吧。
#你可以直接按照摄像头固定的图片大小比如640,480这样。
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
out_file = open('VOCdevkit/VOC2007/labels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
work_sapce_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
work_sapce_dir = os.path.join(work_sapce_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
VOC_file_dir = os.path.join(work_sapce_dir, "ImageSets/")
if not os.path.isdir(VOC_file_dir):
os.mkdir(VOC_file_dir)
VOC_file_dir = os.path.join(VOC_file_dir, "Main/")
if not os.path.isdir(VOC_file_dir):
os.mkdir(VOC_file_dir)
train_file = open(os.path.join(wd, "2007_train.txt"), 'w')
test_file = open(os.path.join(wd, "2007_test.txt"), 'w')
train_file.close()
test_file.close()
VOC_train_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/train.txt"), 'w')
VOC_test_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/test.txt"), 'w')
VOC_train_file.close()
VOC_test_file.close()
if not os.path.exists('VOCdevkit/VOC2007/labels'):
os.makedirs('VOCdevkit/VOC2007/labels')
train_file = open(os.path.join(wd, "2007_train.txt"), 'a')
test_file = open(os.path.join(wd, "2007_test.txt"), 'a')
VOC_train_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/train.txt"), 'a')
VOC_test_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/test.txt"), 'a')
list = os.listdir(image_dir) # list image files
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
for i in range(0,len(list)):
path = os.path.join(image_dir,list[i])
if os.path.isfile(path):
image_path = image_dir + list[i]
voc_path = list[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
if(probo < 75):
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
VOC_train_file.write(voc_nameWithoutExtention + '\n')
convert_annotation(nameWithoutExtention)
else:
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
VOC_test_file.write(voc_nameWithoutExtention + '\n')
convert_annotation(nameWithoutExtention)
train_file.close()
test_file.close()
VOC_train_file.close()
VOC_test_file.close()
2)将lableimage训练目录的图片.jpg文件 全部拷贝到 VOCdevkit/VOC2007/JPEGImages/ 目录中
3)将labelimage生成的文件 .xml 全部拷贝到 VOCdevkit/VOC2007/Annotations/ 目录中
在darknet目录下 执行 python gen_files.py,会产生如下变动文本文件:
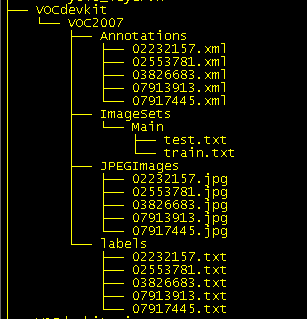

4)进入 /darknet/data目录 copy一份 voc.names 为 vocxxx.names (自定义)
cp voc.names vocfp.names
vim vocxxx.names
里面为训练图片标注分类,我这边就是0,1,2,3,4,5,6,7,8,9

5)进入/darknet/cfg目录 拷贝创建vocfp.data(文件名随意)
cp voc.data vocfp.data
编辑内容:
vim vocfp.data
classes=10
train = /home/yolo/darknet/2007_test.txt
valid = /home/yolo/darknet/2007_train.txt
names = data/vocfp.names
backup = backup
6)进入/darknet/cfg 目录 拷贝创建 yolov3-vocfp.cfg(文件名随意)
cp yolov3-voc.cfg yolov3-vocfp.cfg
编辑内容
vim yolov3-vocfp.cfg (这个是训练关键内容,详细解读如下)

subdivisions=16 (显存大时可用8)
为增加网络分辨率可增大height和width的值,但必须是32的倍数

把max_batches设置为 (classes*2000);但最少为4000。例如如果训练3个目标类别,
max_batches=6000
把steps改为max_batches的80% and 90%;例如steps=4800, 5400
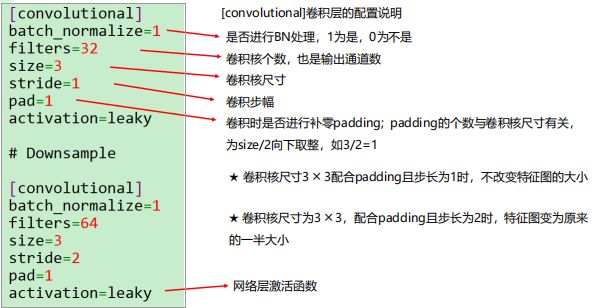
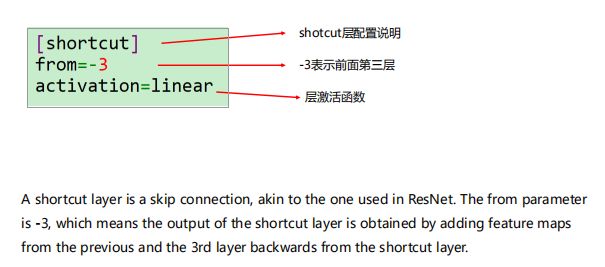

每个yolo层的前一层 filters必须设置为 filters=num*(classes+5)
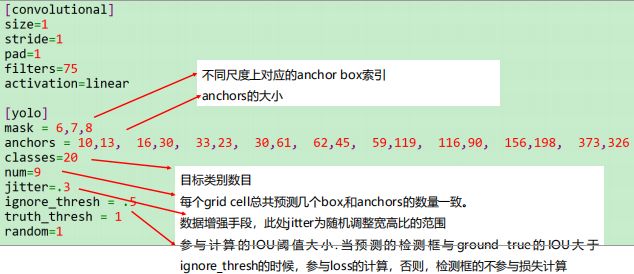


最后配置完,保存,退出。
18)训练自己的数据集
下载预训练数据集
wget https://pjreddie.com/media/fifiles/darknet53.conv.74
训练
./darknet detector train cfg/voc-ball.data cfg/yolov3-voc-ball.cfg darknet53.conv.74
最后识别图片进行测试:
./darknet detect cfg/yolo.cfg yolo.weights xxxxx.jpg
注意上面的命令可能压根识别不出你分好的类,使用第二种方法进行识别:
./darknet detector test cfg/vocfp.data cfg/yolov3-vocfp .cfg backup/yolov3-voc_final.weights 03829611.jgp