重读 Amazon Dynamo 论文有感
本文内容不仅仅局限于 Dynamo
- 什么是 Dynamo
- Dynamo 和 MySQL 的关系?
- 数据分片
- 数据分片的实现方式
- Redis 集群的数据分片
- Dynamo 的数据分片
- 一致性哈希的改进
- 数据复制
- Dynamo 的读写流程
- 数据一致性和冲突解决
- Dynamo 集群成员状态监测
- 总结
- 参考资料
什么是 Dynamo
亚马逊在业务发展期间面临一些问题,主要受限于关系型数据库的可扩展性和高可用性,希望研发一套新的、基于 KV 存储模型的数据库,将之命名为 Dynamo。
相较于传统的关系型数据库 MySQL,Dynamo 的功能目标与之有一些细小的差别,例如 Amazon 的业务场景多数情况并不需要支持复杂查询,却要求必要的单节点故障容错性、数据最终一致性(即牺牲数据强一致优先保障可用性)、较强的可扩展性等。
可以肯定的是,在上述功能目标的驱使下,Dynamo 需要解决以下几个关键问题:
- 它要在
CAP中做出取舍,Dynamo选择牺牲特定情况下的强一致性(这也是大多数新兴数据库的权衡)优先保障可用性 - 它需要引入多节点,通过异步数据流复制完成数据备份和冗余,从而支持单节点故障切换、维持集群高可用
- 它需要引入某种 “再平衡(
rebalance)” 算法来完成集群的自适应管理和扩展操作,Dynamo选择了一致性哈希算法
Dynamo 和 MySQL 的关系?
有的人有这种疑问,其实二者没有什么关系,Dynamo 叙述的是一种 NoSQL 数据库的设计思想和实现方案,它是一个由多节点实例组成的集群,其中一个节点称之为 Instance(或者 Node 其实无所谓),这个节点由三个模块组成,分别是请求协调器、Gossip 协议检测、本地持久化引擎,其中最后一个持久化引擎被设计为可插拔的形式,可以支持不同的存储介质,例如 BDB、MySQL 等。
数据分片
数据分片的实现方式
数据分片实在是太常见了,因为海量数据无法仅存储在单一节点上,必须要按照某种规则进行划分之后分开存储,在 MySQL 中也有分库分表方案,它本质上就是一种数据分片。
数据分片的逻辑既可以实现在客户端,也可以实现在 Proxy 层,取决于你的架构如何设计,传统的数据库中间件大多将分片逻辑实现在客户端,通过改写物理 SQL 访问不同的 MySQL 库;而 NewSQL 数据库倡导的计算存储分离架构中呢,通常将分片逻辑实现在计算层,即 Proxy 层,通过无状态的计算节点转发用户请求到正确的存储节点。
Redis 集群的数据分片
Redis 集群也是 NoSQL 数据库,它是怎么解决哈希映射问题的呢?它启动时就划分好了 16384 个桶,然后再将这些桶分配给节点占有,数据是固定地往这 16384 个桶里放,至于节点的增减操作,那就是某些桶的重新分配,缩小了数据流动的范围。
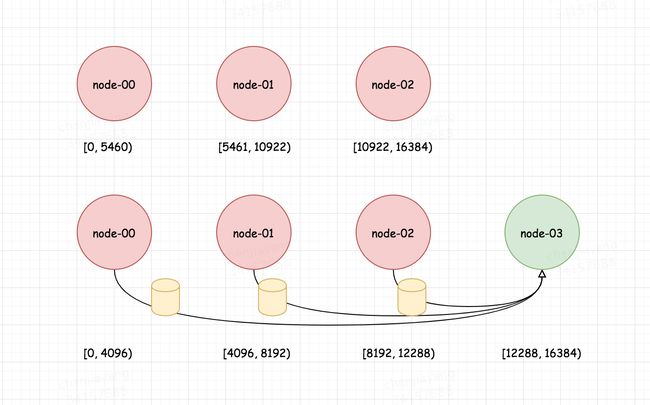
Dynamo 的数据分片
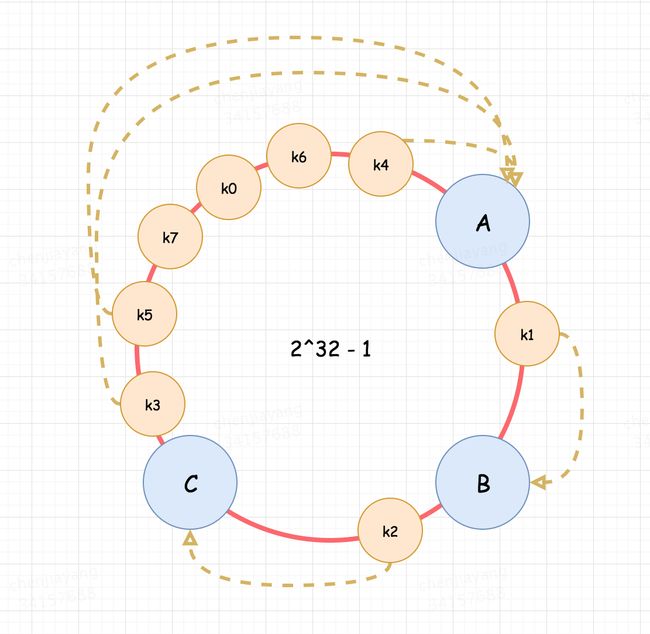
Dynamo 设计之初就考虑到要支持增量扩展,因为节点的增减必须具备很好的可扩展性,尽可能降低期间的数据流动,从而减轻集群的性能抖动。Dynamo 选择采用一致性哈希算法来处理节点的增删,一致性哈希的算法原理细节这里不再赘述,只是提一下为什么一致性哈希能解决传统哈希的问题。
我们想象一下传统哈希算法的局限是什么,一旦我给定了节点总数 h,那数据划分到哪个节点就固定了(x mod h),此时我一旦增减 h 的大小,那么全部数据的映射关系都要发生改变,解决办法只能是进行数据迁移,但是一致性哈希可以在一个圆环上优先划分好每个节点负责的数据区域。这样每次增删节点,影响的范围就被局限在一小部分数据。
下图蓝色小圆 ABCD 的代表四个实际节点,橙色的小圆代表数据,他们顺时针落在第一个碰到的节点上
一致性哈希的改进
一致性哈希是存在缺点的,如果仅仅是直接将每个节点映射到一个圆环上,可能造成节点间复杂的范围有大有小,造成数据分布和机器负载不均衡。
因此一致性哈希有个优化举措,就是引入虚拟节点,其实就是我再引入一个中间层解耦,虚拟节点平均落在圆环上,然后实际节点的映射跟某几个虚拟节点挂钩,表示我这台物理节点实际负责这些虚拟节点的数据范围,从而达到平衡负载的作用。
数据复制
数据复制是提升数据库高可用的常见手段,从实现方式上可分为同步复制、异步复制、半同步复制等,从使用场景上又可分为单向复制、双向复制、环形复制等。
Dynamo 的设计中为了保证容灾,数据被复制到 N 台主机上,N 就是数据的冗余副本数目,还记得我们说过 Dynamo 中每个节点有一个模块叫做请求协调器么,它接收到某个数据键值 K 之后会将其往圆环后的 N - 1 个节点进行复制,保证该键值 K 有 N 个副本,因此 Dynamo 中实际上每个节点既存储自己接收的数据,也存储为其他节点保留的副本数据。
Dynamo 的读写流程
Dynamo 会在数据的所有副本中选取一个作为协调者,由该副本负责转发读写请求和收集反馈结果。通常情况下,该副本是客户端从内存中维护的 数据 - 节点 映射关系中取得的,将请求直接发往该节点。
对于写请求,该副本会接收写请求,并记录该数据的更新者和时间戳,并将写请求转发给其他副本,待 W 个副本反馈写入完成后向客户端反馈写入操作成功;读取流程类似,转发读请求至所有副本,待收到 R 个副本的结果后尝试选取最新的数据版本,一旦发现数据冲突则保留冲突反馈给客户端处理。
显而易见的是,由于协调者是处理读写请求的唯一入口,因此该副本所在节点的负载肯定会飙高。
数据一致性和冲突解决
在数据存在 N 个冗余副本的情况下,想要保证强一致需要等待所有副本写入完成才能返回给客户端写入成功,但这是性能有损的,实践中通常不这么做。Dynamo 允许用户设置至少写入 W 个副本才返回,而读取的时候需要从 R 个副本上读到值才能返回,因此只要 W + R > N,就能保证一定能读到正确的值。
但是这有个问题是如何判断返回的 R 个值中哪个是最新的呢,即每个数据都应该有一个版本信息。Dynamo 为了解决这个问题引入向量时钟的概念,简单来说就是每次写入操作,写入的副本会为这条数据变更新增一个更新者和版本号的向量组
例如副本 A 接收到了对键值 K 的更新请求,随机为键值 K 新增版本信息 K : ,等待之后再次更新 K 时更改为 K : ,因此后者版本更新。
假设集群中的网络没有问题,那么对于某个键值 K 的读取一定能读取到时间戳最新的版本返回给客户端。但是遗憾的是,分布式场景下网络是一定会出问题的,各种问题。。
假设客户端在第二次更新时选择了另一个副本 B 作为协调者,那么 B 会为键值 K 保存 K : ,这时客户端读取键值 K,协调者发现无法决定哪个版本是最新的,就类似于 Git Merge 出现冲突,只能保留这种冲突返回给客户端,由具体业务逻辑觉得采用哪个值。
Dynamo 集群成员状态监测
Dynamo 想要做到 HA(高可用),除了数据复制之外,还需要定时探测集群节点的可用性,有的业界产品依赖外部服务统一处理,例如 MySQL 的 MHA,RocketMQ 的 NS,TiDB 的 PD 等,也有的依赖于节点间自适应管理,例如 Redis 集群和 Dynamo,这二者均采用了 Gossip 协议作为集群间节点信息交换的解决方案,无需引入外部服务,是完全的去中心化的架构。
想要了解什么是 Gossip 协议,建议从 Redis 集群的架构中去学习,往往使用 Gossip 协议的集群实现都比较复杂,而且容易出错,另外 Gossip 协议本身由于数据包庞大,也极易造成性能抖动问题。
总结
最近重读了一遍 Dynamo 论文,加上之前看过几遍的 《Design Data-intensive Applications》,感觉很多分布式系统设计的概念都可以很好地衔接上,对知识梳理很有帮助,大家感兴趣也可以去看看。
参考资料
- Dynamo: Amazon’s Highly Available Key-value Store
- 《Design Data-intensive Applications》
- 知乎专栏:Dynamo: amazon’s highly available key-value store