一个快速构造GAN的教程:如何用pytorch构造DCGAN

在本教程中,我们将在PyTorch中构建一个简单的DCGAN,并在手写数据集上对它进行训练。我们将讨论PyTorch DataLoader,以及如何使用它将图像数据提供给PyTorch神经网络进行训练。PyTorch是本教程的重点,所以我假设您熟悉GAN的工作方式。
要求
- python版本为3.7或更高。
- PyTorch 1.5不知道如何安装? 可以参考github项目https://github.com/zergtant/pytorch-handbook
- Matplotlib 3.1或更高版本
- 22分钟左右的时间。
目前的任务
创建一个函数G: Z→X, Z ~ N₁₆(0, 1)和X ~ MNIST。
也就是说,训练一个GAN,让它接收16维随机噪声,并生成看起来像来自MNIST数据集的真实样本的图像。

但在我们开始之前…
我们来整理一下。首先请安装所需的Python版本和上述库。然后,创建您的项目目录。我这里是DCGAN。在该目录中,创建一个名为data的目录。然后,定位到这个GitHub目录(https://github.com/myleott/mnist_png)并下载mnist_png.tar.gz。这个压缩文件包含MNIST数据集,为70000个单独的png文件。当然,我们可以使用PyTorch内置的MNIST数据集,但这样您就不能了解如何加载具体的图像数据进行训练。解压缩文件并将mnist_png目录放入数据目录中。你的项目目录应该是这样的:

最后,在dcgan_mni .py脚本中添加以下内容:
import osimport torch
from torch import nn
from torch import optim
import torchvision as tv
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
好了,现在我们可以开始了。
生成器
将以下内容添加到您的dcgan_mni .py脚本:
class Generator(nn.Module):
def __init__(self, latent_dim=100, batchnorm=True):
"""A generator for mapping a latent space to a sample space.
The sample space for this generator is single-channel, 28x28 images
with pixel intensity ranging from -1 to +1.
Args:
latent_dim (int): latent dimension ("noise vector")
batchnorm (bool): Whether or not to use batch normalization
"""
super(Generator, self).__init__()
self.latent_dim = latent_dim
self.batchnorm = batchnorm
self._init_modules()
def _init_modules(self):
"""Initialize the modules."""
# Project the input
self.linear1 = nn.Linear(self.latent_dim, 256*7*7, bias=False)
self.bn1d1 = nn.BatchNorm1d(256*7*7) if self.batchnorm else None
self.leaky_relu = nn.LeakyReLU()
# Convolutions
self.conv1 = nn.Conv2d(
in_channels=256,
out_channels=128,
kernel_size=5,
stride=1,
padding=2,
bias=False)
self.bn2d1 = nn.BatchNorm2d(128) if self.batchnorm else None
self.conv2 = nn.ConvTranspose2d(
in_channels=128,
out_channels=64,
kernel_size=4,
stride=2,
padding=1,
bias=False)
self.bn2d2 = nn.BatchNorm2d(64) if self.batchnorm else None
self.conv3 = nn.ConvTranspose2d(
in_channels=64,
out_channels=1,
kernel_size=4,
stride=2,
padding=1,
bias=False)
self.tanh = nn.Tanh()
def forward(self, input_tensor):
"""Forward pass; map latent vectors to samples."""
intermediate = self.linear1(input_tensor)
intermediate = self.bn1d1(intermediate)
intermediate = self.leaky_relu(intermediate)
intermediate = intermediate.view((-1, 256, 7, 7))
intermediate = self.conv1(intermediate)
if self.batchnorm:
intermediate = self.bn2d1(intermediate)
intermediate = self.leaky_relu(intermediate)
intermediate = self.conv2(intermediate)
if self.batchnorm:
intermediate = self.bn2d2(intermediate)
intermediate = self.leaky_relu(intermediate)
intermediate = self.conv3(intermediate)
output_tensor = self.tanh(intermediate)
return output_tensor
生成器继承nn.Module,它是PyTorch神经网络的基类。生成器有三种方法:
Generator.init
构造函数,它存储实例变量并调用_init_layers。这里没什么可说的。
Generator._init_modules
这个方法实例化PyTorch模块(或在其他框架中调用的“层”)。这些包括:
- 一个线性(“完全连接”)模块,将向量空间映射到一个7×7×256 = 1254维空间。我们将看到,这个12554长度张量被重新塑造为a(256,7,7)的“图像”张量(通道×高×宽)。在pytorch中,通道在空间维度之前。
- 一个一维的指定的的批处理模块。
- ReLU模块。
- 一个二维的卷积层。
- 两个二维反卷积层;这用于放大图像。请注意一个卷积层的外通道是如何成为下一个卷积层的内通道的。
- 两个二维批归一化层。
- 一个Tanh模块作为输出激活。我们将重新标定图像到范围[-1,1],所以我们的生成器输出激活应该反映这一点。
这些可以在剩余的__init__方法中实例化,但是我喜欢将模块实例化与构造函数分开。对于如此简单的模型来说,这是微不足道的,但是当模型变得越来越复杂时,这有助于保持代码的简单。
Generator.forward
这就是我们的生成器从随机噪声中生成样本的方法。输入张量被传递给第一个模块,输出被传递给下一个模块,输出被传递给下一个模块,以此类推。这是相当直接的,但我想提请您注意两个有趣的特点:
- 注意这一行
intermediate = intermediate.view((-1, 256, 7, 7))。与Keras不同,PyTorch不使用显式的“重塑”模块;相反,我们使用PyTorch操作“视图”手动重塑张量。其他简单的PyTorch操作也可以在前传过程中应用,比如将一个张量乘以2,PyTorch不会眨眼睛。 - 注意
forward方法中的if语句。PyTorch使用一种逐行定义策略,这意味着在向前传球期间动态构建计算图。这使得PyTorch极其灵活;没有什么可以阻止您向向前传递添加循环,或者随机选择要使用的几个模块中的一个。
鉴别器
将以下内容添加到您的dcgan_mni .py脚本:
class Discriminator(nn.Module):
def __init__(self):
"""A discriminator for discerning real from generated images.
Images must be single-channel and 28x28 pixels.
Output activation is Sigmoid.
"""
super(Discriminator, self).__init__()
self._init_modules()
def _init_modules(self):
"""Initialize the modules."""
self.conv1 = nn.Conv2d(
in_channels=1,
out_channels=64,
kernel_size=5,
stride=2,
padding=2,
bias=True)
self.leaky_relu = nn.LeakyReLU()
self.dropout_2d = nn.Dropout2d(0.3)
self.conv2 = nn.Conv2d(
in_channels=64,
out_channels=128,
kernel_size=5,
stride=2,
padding=2,
bias=True)
self.linear1 = nn.Linear(128*7*7, 1, bias=True)
self.sigmoid = nn.Sigmoid()
def forward(self, input_tensor):
"""Forward pass; map samples to confidence they are real [0, 1]."""
intermediate = self.conv1(input_tensor)
intermediate = self.leaky_relu(intermediate)
intermediate = self.dropout_2d(intermediate)
intermediate = self.conv2(intermediate)
intermediate = self.leaky_relu(intermediate)
intermediate = self.dropout_2d(intermediate)
intermediate = intermediate.view((-1, 128*7*7))
intermediate = self.linear1(intermediate)
output_tensor = self.sigmoid(intermediate)
return output_tensor
我不会详细介绍这点,因为它非常类似于生成器。但仔细阅读它,确保你理解它的作用。
DCGAN
将以下内容添加到您的dcgan_mni .py脚本:
class DCGAN():
def __init__(self, latent_dim, noise_fn, dataloader,
batch_size=32, device='cpu', lr_d=1e-3, lr_g=2e-4):
"""A very basic DCGAN class for generating MNIST digits
Args:
generator: a Ganerator network
discriminator: A Discriminator network
noise_fn: function f(num: int) -> pytorch tensor, (latent vectors)
dataloader: a pytorch dataloader for loading images
batch_size: training batch size. Must match that of dataloader
device: cpu or CUDA
lr_d: learning rate for the discriminator
lr_g: learning rate for the generator
"""
self.generator = Generator(latent_dim).to(device)
self.discriminator = Discriminator().to(device)
self.noise_fn = noise_fn
self.dataloader = dataloader
self.batch_size = batch_size
self.device = device
self.criterion = nn.BCELoss()
self.optim_d = optim.Adam(self.discriminator.parameters(),
lr=lr_d, betas=(0.5, 0.999))
self.optim_g = optim.Adam(self.generator.parameters(),
lr=lr_g, betas=(0.5, 0.999))
self.target_ones = torch.ones((batch_size, 1), device=device)
self.target_zeros = torch.zeros((batch_size, 1), device=device)
def generate_samples(self, latent_vec=None, num=None):
"""Sample images from the generator.
Images are returned as a 4D tensor of values between -1 and 1.
Dimensions are (number, channels, height, width). Returns the tensor
on cpu.
Args:
latent_vec: A pytorch latent vector or None
num: The number of samples to generate if latent_vec is None
If latent_vec and num are None then use self.batch_size
random latent vectors.
"""
num = self.batch_size if num is None else num
latent_vec = self.noise_fn(num) if latent_vec is None else latent_vec
with torch.no_grad():
samples = self.generator(latent_vec)
samples = samples.cpu() # move images to cpu
return samples
def train_step_generator(self):
"""Train the generator one step and return the loss."""
self.generator.zero_grad()
latent_vec = self.noise_fn(self.batch_size)
generated = self.generator(latent_vec)
classifications = self.discriminator(generated)
loss = self.criterion(classifications, self.target_ones)
loss.backward()
self.optim_g.step()
return loss.item()
def train_step_discriminator(self, real_samples):
"""Train the discriminator one step and return the losses."""
self.discriminator.zero_grad()
# real samples
pred_real = self.discriminator(real_samples)
loss_real = self.criterion(pred_real, self.target_ones)
# generated samples
latent_vec = self.noise_fn(self.batch_size)
with torch.no_grad():
fake_samples = self.generator(latent_vec)
pred_fake = self.discriminator(fake_samples)
loss_fake = self.criterion(pred_fake, self.target_zeros)
# combine
loss = (loss_real + loss_fake) / 2
loss.backward()
self.optim_d.step()
return loss_real.item(), loss_fake.item()
def train_epoch(self, print_frequency=10, max_steps=0):
"""Train both networks for one epoch and return the losses.
Args:
print_frequency (int): print stats every `print_frequency` steps.
max_steps (int): End epoch after `max_steps` steps, or set to 0
to do the full epoch.
"""
loss_g_running, loss_d_real_running, loss_d_fake_running = 0, 0, 0
for batch, (real_samples, _) in enumerate(self.dataloader):
real_samples = real_samples.to(self.device)
ldr_, ldf_ = self.train_step_discriminator(real_samples)
loss_d_real_running += ldr_
loss_d_fake_running += ldf_
loss_g_running += self.train_step_generator()
if print_frequency and (batch+1) % print_frequency == 0:
print(f"{batch+1}/{len(self.dataloader)}:"
f" G={loss_g_running / (batch+1):.3f},"
f" Dr={loss_d_real_running / (batch+1):.3f},"
f" Df={loss_d_fake_running / (batch+1):.3f}",
end='\r',
flush=True)
if max_steps and batch == max_steps:
break
if print_frequency:
print()
loss_g_running /= batch
loss_d_real_running /= batch
loss_d_fake_running /= batch
return (loss_g_running, (loss_d_real_running, loss_d_fake_running))
view raw
dcgan_mnist_gan.py hosted with ❤ by GitHub
DCGAN.init
让我们逐行查看构造函数:
self.generator = Generator(latent_dim).to(device)
self.discriminator = Discriminator().to(device)
构造函数的前两行(非docstring)实例化生成器和Discriminator,将它们移动到指定的地方,并将它们存储为实例变量。通常是“cpu”,或者“cuda”,如果你想使用gpu。
self.noise_fn = noise_fn
接下来,我们将noise_fn存储为一个实例变量;noise_fn函数以整数作为输入,并以PyTorch张量的形式返回num潜在向量作为输出,带有(num, latent_dim)的形状。这个PyTorch张量必须在指定的设备上。
self.dataloader = dataloader
我们存储dataloader,一个torch.utils.data.DataLoader对象作为实例变量;稍后将对此进行更多介绍。
self.batch_size = batch_size
self.device = device
存储为实例变量。
self.criterion = nn.BCELoss()
self.optim_d = optim.Adam(self.discriminator.parameters(), lr=lr_d, betas=(0.5, 0.999))
self.optim_g = optim.Adam(self.generator.parameters(), lr=lr_g, betas=(0.5, 0.999))
将损失函数设置为交叉熵,并实例化生成器和鉴别器的Adam优化器。pytorch的优化器需要知道他们在优化什么。对于鉴别器,这意味着鉴别器网络中的所有可训练参数。因为我们的Discriminator类继承自nn.Module中,它有parameters()方法,该方法返回所有实例变量中的所有可训练参数,这些实例变量也是PyTorch模块。生成器也是一样。
self.target_ones = torch.ones((batch_size, 1), device=device)
self.target_zeros = torch.zeros((batch_size, 1), device=device)
为训练的目标,设置为指定的设备。记住,鉴别器试图将真实样本分类为1,将生成样本分类为0,而生成器试图让鉴别器将生成样本错误分类为1。我们在这里定义并存储它们,这样我们就不必在每个训练步骤中重新创建它们。
DCGAN.generate_samples
用于生成示例的辅助方法。注意,这里使用了no_grad上下文管理器,它告诉PyTorch不要跟踪梯度,因为这个方法不用于训练网络。还要注意的是,无论指定的设备是什么,返回的张量都被设置为cpu,这对于进一步的使用是必要的,比如显示样本或将它们保存到磁盘上。
DCGAN.train_step_generator
此方法执行生成器的一个epoch,并以浮点数的形式返回损失。让我们一步步来看看:
self.generator.zero_grad()
清除生成器的梯度是必要的。因为PyTorch会自动跟踪梯度和计算网络。而我们现在不需要这些。
latent_vec = self.noise_fn(self.batch_size)
generated = self.generator(latent_vec)
classifications = self.discriminator(generated)
loss = self.criterion(classifications, self.target_ones)
获取一批潜在向量,利用它们生成样本,判别每个样本的真实程度,然后利用交叉熵计算损失。注意,通过将这些网络链接在一起,我们创建了一个单一的计算图,从潜在向量开始,包括生成器和鉴别器网络,并以损失结束。
loss.backward()
self.optim_g.step()
PyTorch的主要优点之一是它可以自动跟踪计算图形及其梯度。通过loss调用反向传播,PyTorch应用反向传播并计算损失相对于计算图中的每个参数的梯度。通过调用生成器中优化器的step方法,生成器的参数(只有生成器的参数)将略微向其梯度的负方向移动。
return loss.item()
最后,我们得到损失。使用item方法很重要,这样我们将返回一个浮点数而不是一个PyTorch张量。如果我们返回了张量,Python垃圾收集器将无法清理底层的计算图,我们将很快耗尽内存。
DCGAN.train_step_discriminator
这个方法与train_step_generator非常相似,但是有两个显著的区别。第一:
with torch.no_grad():
fake_samples = self.generator(latent_vec)
这里使用上下文管理器no_grad来告诉PyTorch不要跟踪梯度。这不是必须的,但减少了不必要的计算。第二:
loss = (loss_real + loss_fake) / 2
这条线真的很酷。loss_real为真实样本的鉴别器损失(附加其计算图),loss_fake为虚假样本的鉴别器损失(及计算图)。PyTorch能够使用+运算符将这些图形组合成一个计算图形。然后我们将反向传播和参数更新应用到组合计算图。如果您不认为这是简单的,试着在另一个框架中重写它。
DCGAN.train_epoch
这个函数进行一次训练生成器和鉴别器的epoch,也就是在整个数据集上进行一次遍历。我们绕一圈后再回到这个问题上。
main
添加以下代码到您的脚本:
def main():
import matplotlib.pyplot as plt
from time import time
batch_size = 32
epochs = 100
latent_dim = 16
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = tv.transforms.Compose([
tv.transforms.Grayscale(num_output_channels=1),
tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5,), (0.5,))
])
dataset = ImageFolder(
root=os.path.join("data", "mnist_png", "training"),
transform=transform
)
dataloader = DataLoader(dataset,
batch_size=batch_size,
shuffle=True,
num_workers=2
)
noise_fn = lambda x: torch.randn((x, latent_dim), device=device)
gan = DCGAN(latent_dim, noise_fn, dataloader, device=device, batch_size=batch_size)
start = time()
for i in range(10):
print(f"Epoch {i+1}; Elapsed time = {int(time() - start)}s")
gan.train_epoch()
images = gan.generate_samples() * -1
ims = tv.utils.make_grid(images, normalize=True)
plt.imshow(ims.numpy().transpose((1,2,0)))
plt.show()
if __name__ == "__main__":
main()
view raw
dcgan_mnist_main.py hosted with ❤ by GitHub
该函数构建、训练和展示GAN。
import matplotlib.pyplot as plt
from time import time
batch_size = 32
epochs = 100
latent_dim = 16
导入pyplot(用于可视化)和time(用于为训练计时)。将训练批处理大小设置为32,epoch数设置为100,隐藏层维度设置为16。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
这一行检查是否有cuda设备可用。如果有,则分配该设备;否则,分配cpu。
transform = tv.transforms.Compose([
tv.transforms.Grayscale(num_output_channels=1),
tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5,), (0.5,))
])
dataloader使用这种复合变换对图像进行预处理。我们之前下载的MNIST数据集是.png文件;当PyTorch从磁盘加载它们时,必须对它们进行处理,以便我们的神经网络能够正确地使用它们。变换的顺序是:
Grayscale(num_output_channels=1):将图像转换为灰度图。加载时,MNIST数字为RGB格式,有三个通道。Greyscale将这三种减少为一种。ToTensor():将图像转换为点tensor张量,其尺寸通道×高度×宽度。这也将重新调整像素值,从0到255之间的整数到0.0到1.0之间的浮点值。Normalize((0.5,),(0.5,)):将像素值从范围[0.0,1.0]缩放到[-1.0,1.0]。第一个参数是所属,第二个参数是使用量,应用于每个像素的函数为:
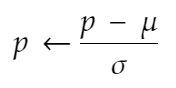
因为这个转换是对每个通道应用的,所以它是一个元组。RGB图像的等效变换是
Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
dataset = ImageFolder(
root=os.path.join("data", "mnist_png", "training"),
transform=transform
)
在这里,我们通过指定数据集的目录和要应用的转换来创建数据集。用于创建DataLoader:
dataloader = DataLoader(dataset,
batch_size=batch_size,
shuffle=True,
num_workers=2
)
DataLoader是一个对象,它从数据集加载数据。这里我们指定批量大小,告诉dataloader打乱每个epoch之间的数据集,并使用两个工作进程(如果您使用的是Windows,这将导致问题,可以将num_workers设置为0),遍历这个dataloader和每次迭代它将返回一个元组包含:
- 对应一批(32个样本)灰度(1通道)MNIST图像(28×28像素)的形状(32,1,28,28)的PyTorch张量。
- 从0到9的形状(32,)的PyTorch张量,对应于该图像的标号(digit)。这些类标签是从目录结构中获取的,因为所有的0都在目录0中,所有的1都在目录1中,等等。
noise_fn = lambda x: torch.rand((x, latent_dim), device=device)
用于产生随机、正态分布噪声的函数。
gan = DCGAN(latent_dim, noise_fn, dataloader, device=device)
start = time()
for i in range(10):
print(f"Epoch {i+1}; Elapsed time = {int(time() - start)}s")
gan.train_epoch()
建立和训练GAN。
DCGAN.train_epoch, again:
既然我们已经讨论了什么是DataLoader,让我们再来看看这个。方法虽然冗长,但我想重点在两行:
for batch, (real_samples, _) in enumerate(self.dataloader):
real_samples = real_samples.to(self.device)
在这里,我们遍历dataloader。我们将dataloader包装在迭代器中,这样我们就可以跟踪编号,但是正如您所看到的,dataloader确实按照承诺返回了一个元组。我们将这批图像张量分配给real_samples,并忽略标签,因为我们不需要它们。然后,在循环中,我们将real_samples移动到指定的网络。重要的是模型的输入和模型本身在同一个设备上;如果你忘记了,不要担心,PyTorch一定会让你知道的!另外,不要担心dataloader“快用完了”。一旦我们遍历了整个数据集,循环将结束,但如果我们尝试再次遍历它,它将从开始开始(首先移动图像,因为我们在创建dataloader时指定了这一点)。
让我们试着运行一下?
如果复制和粘贴正确,运行脚本应该会显示几分钟的训练统计数据,然后是一些生成的数字。希望它是这样的:
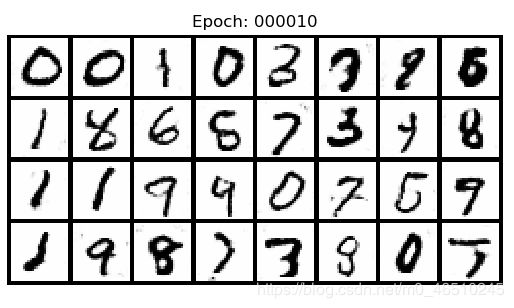
如果它们看起来很糟糕,试着再运行一次(GANs是出了名的不稳定)。如果它仍然不行,在下面加一个提示,我们将看看我们是否不能调用它。
为了乐趣,我修改了这个脚本,看看生成器在每10个epoch之后能够做什么。以下是结果。
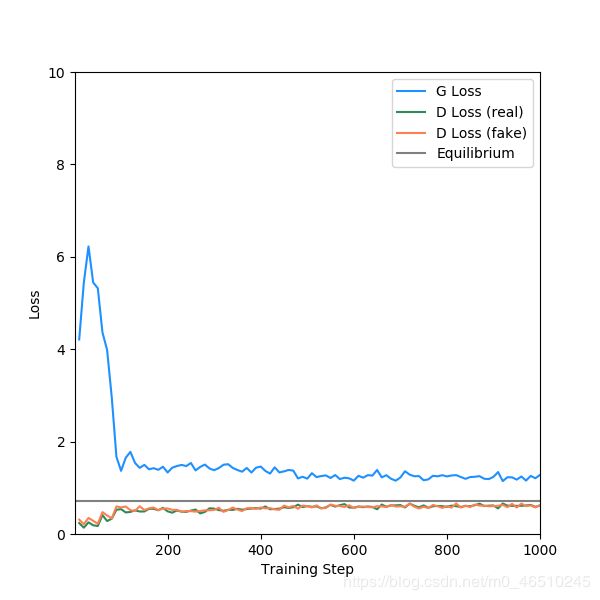
我认为这对于1000个epoch来说已经很不错了。以下是那些训练步骤的损失,分为10个“阶段”。
结论
- 本教程中描述的DCGAN显然非常简单,但它应该足以让您开始在PyTorch中实现更复杂的GANs。
- 在我做一个关于GAN的教程之前,你能修改这个脚本来制作一个条件GAN吗?
- 完整的脚本可以在这里找到。https://github.com/ConorLazarou/pytorch-generative-models/blob/master/GAN/DCGAN/dcgan_mnist.py
作者:Conor Lazarou
deephub翻译组:孟翔杰