数据仓库项目整理(一)
目录
一、前提
二、流程图
三、数据仓库的分层
1、为什么要分层?
2、哪四层以及作用?
四、具体实现
1.obs原始数据层
2.dwd明细数据层
一、前提
hadoop+zookeeper+kafka+flume+hive+tez集群搭建完毕,对采集的日志数据进行数据仓库分层,做一下简单回顾总结,如果对上述软件不熟悉,后面我再做详细分节补充。
二、流程图
该项目抽象出来的整体流程图如下:
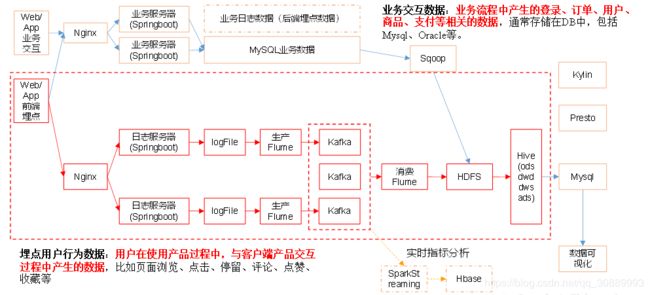 架构图
架构图
今天所要讲的是下面这点:

flume采集来的原始数据存放在hdfs文件系统中,通过hive数据仓库四层处理(每个公司定义可能不一样,作用都是一样的)得到统计结果,最后存放在mysql中,着重讲一下hive的分层处理数据
三、数据仓库的分层
1、为什么要分层?
三层原因:复杂的问题分解多步,简化问题,并且方便定位问题;通过中间层,极大减少重复开发的步骤,增加复用性;隔离原始数据,实现解耦
2、哪四层以及作用?
1)obs原始数据层:把hdfs数据直接拿过来
2)dwd明细数据层:比较重要,需要自定义一些函数,处理一些复杂问题,重点,清洗脏数据,去除空值,解析出业务的明细表
3)dws服务数据层:对明细数据进行轻度汇总,以某一个维度为线索,组成跨主题的宽表,日活跃用户,月活跃用户,留存,留存率等等。。
4)ads数据应用层:为公司提供报表数据
四、具体实现
1.obs原始数据层
创建启动日志的外表:(脱敏字段以及数据)
创建输入数据是lzo输出是text,支持json解析的分区表
hive (gmall)>
drop table if exists ods_start_log;
CREATE EXTERNAL TABLE ods_start_log (`line` string)
PARTITIONED BY (`dt` string)
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_start_log';
把hdfs中的数据加载到该表中:
hive (gmall)>
load data inpath '/origin_data/gmall/log/topic_start/2019-02-10' into table gmall.ods_start_log partition(dt='2019-02-10');
查看数据是否成功,对数据条数进行限制,要不然太多了
hive (gmall)> select * from ods_start_log limit 2;其他的原始数据如法炮制
2.dwd明细数据层
创建启动表:(脱敏字段以及数据)
hive (gmall)>
drop table if exists dwd_start_log;
CREATE EXTERNAL TABLE dwd_start_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`entry` string,
`open_ad_type` string,
`action` string,
`loading_time` string,
`detail` string,
`extend1` string
)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_start_log/';
向启动表导数据:
hive (gmall)>
insert overwrite table dwd_start_log
PARTITION (dt='2019-02-10')
select
get_json_object(line,'$.mid') mid_id,
get_json_object(line,'$.uid') user_id,
get_json_object(line,'$.vc') version_code,
get_json_object(line,'$.vn') version_name,
get_json_object(line,'$.l') lang,
get_json_object(line,'$.sr') source,
get_json_object(line,'$.os') os,
get_json_object(line,'$.ar') area,
get_json_object(line,'$.md') model,
get_json_object(line,'$.ba') brand,
get_json_object(line,'$.sv') sdk_version,
get_json_object(line,'$.g') gmail,
get_json_object(line,'$.hw') height_width,
get_json_object(line,'$.t') app_time,
get_json_object(line,'$.nw') network,
get_json_object(line,'$.ln') lng,
get_json_object(line,'$.la') lat,
get_json_object(line,'$.entry') entry,
get_json_object(line,'$.open_ad_type') open_ad_type,
get_json_object(line,'$.action') action,
get_json_object(line,'$.loading_time') loading_time,
get_json_object(line,'$.detail') detail,
get_json_object(line,'$.extend1') extend1
from ods_start_log
where dt='2019-02-10';
查看数据:
hive (gmall)> select * from dwd_start_log limit 2;当然可以编写脚本,一键化上述操作,查看结果,需要对shell脚本有一定基础,就不详细介绍了。
下面讲解下自定义UDF,UDTF函数流程,解决复杂的明细表把数据从ods导入dwd层中
1)自定义类继承UDF,重写它的evaluate()
public String evaluate(String line, String jsonkeyString) {
//1获取所有key
String[] jsonkeys = jsonkeyString.split(",");
//2.line 服务器时间
String[] logContend = line.split("\\|");
StringBuilder sb=new StringBuilder();
//3.校验
if (logContend.length != 2 || StringUtils.isBlank(logContend[1])) {
return "";
}
try {
//
JSONObject jsonObject = new JSONObject(logContend[1]);
JSONObject cmObject=jsonObject.getJSONObject("cm");
for(int i=0;i2).自定义UDTF,继承GenericUDTF,重写三个方法
@Override
public StructObjectInspector initialize(ObjectInspector[] argOIs) throws UDFArgumentException {
List fileNames = new ArrayList<>();
List fieldsType = new ArrayList<>();
fileNames.add("event_name");
fieldsType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fileNames.add("event_json");
fieldsType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fileNames, fieldsType);
}
@Override
public void process(Object[] objects) throws HiveException {
String input = objects[0].toString();
if (StringUtils.isBlank(input)) {
return;
} else {
try {
JSONArray ja = new JSONArray(input);
if (ja == null) {
return;
}
for (int i = 0; i < ja.length(); i++) {
String[] results = new String[2];
try {
results[0] = ja.getJSONObject(i).getString("en");
results[1] = ja.getString(i);
} catch (JSONException e) {
continue;
}
forward(results);
}
} catch (JSONException e) {
e.printStackTrace();
}
}
}
hive的自定义函数UDF,UDTF达成jar,丢到linux环境下,把jar添加到hive的classpath
hive (gmall)> add jar /opt/module/hive/hivefunction-1.0-SNAPSHOT.jar;创建临时函数与java关联起来
hive (gmall)>
create temporary function base_analizer as 'com.*.udf.BaseFieldUDF';
就可以调用base_analizer()这个函数了,执行一些复杂的数据导入到dwd层中的明细表