【论文阅读-SAGPool】Self-Attention Graph Pooling
论文地址:https://arxiv.org/abs/1904.08082
代码地址:https://github.com/inyeoplee77/SAGPool
来源:ICML 2019
本篇论文主要是改变了Topk的得分方式,也是本文的创新之处。作者认为以往的得分函数过于简单,没有考虑到图的拓扑信息,认为谱域卷积同时考虑了图的拓扑信息和节点信息,故用谱域卷积的注意力来替换。其他部分基本是参考Graph U-Net论文提出的方法。
模型架构

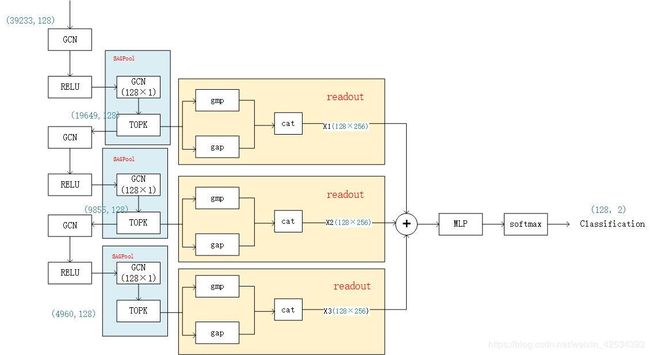
图2左图是全局池化结构,右图是分层池化结构。
全局池化结构由三个图卷积层组成,每层的输出被连接起来。节点特征在池化层之后的readout层中聚合。然后将图的特征表示传递到线性层进行分类。
分层池化架构由三个模块组成,每个模块由一个图卷积层和一个图池化层组成。每个模块的输出经过readout层后,相加再将结果输入到线性层进行分类。代码给出了分层池化架构
代码逻辑
卷积层
在该层可选择各种类型的图卷积,我们将Kipf&Welling提出的广泛使用的图卷积用于所有模型。
![]()
自注意力图池化层
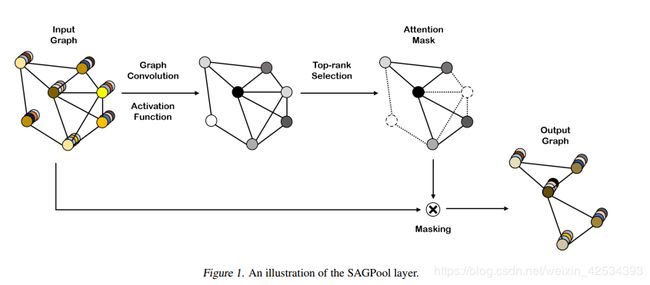
自注意力机制被广泛的应用于最近的研究中。这些机制使得可以分配更多的注意力在重要的特征,不那么关注不重要的特征。我们通过图卷积获得注意力得分。例如,若使用Kipf & Welling的图卷积公式,则自注意力得分Z∈R^{N×1}计算如下:
![]()
通过使用图卷积去获得自注意力分数,可以获得基于图特征和拓扑的结果。在得到注意力得分之后,我们采用Gao & Ji等人提出的topk节点选择方法,选择输入图中保留的节点。通过池化率k(k∈(0,1])来确定保留的节点数,具体计算如下
![]()
代码部分:
x经过一个GCN后得到一个(128,1)的得分矩阵。根据这个得分矩阵进行topk的选择,得到mask。后面根据这个mask去更新子图。
score = self.score_layer(x,edge_index).squeeze() #这里的score_layer是个128×1的卷积层
perm = topk(score, self.ratio, batch)#topk选取得分前50%的节点index
Readout层
Readout层主要是用来聚合节点特征,以进行固定大小的表示,表示为:

代码部分:
对topk后的节点进行一个全局平均池化和全局最大池化操作,再拼接成一个(128,256)的矩阵。(128为batch_size,即选取了128个子图)
from torch_geometric.nn import global_mean_pool as gap, global_max_pool as gmp
x1 = torch.cat([gmp(x, batch), gap(x, batch)], dim=1)#gmp全局最大池化,gap全局平均池化
更新图
filter_adj函数是torch_geometric包里自带的。
from torch_geometric.nn.pool.topk_pool import topk,filter_adj
x = x[perm] * self.non_linearity(score[perm]).view(-1, 1)
batch = batch[perm]
edge_index, edge_attr = filter_adj(edge_index, edge_attr, perm, num_nodes=score.size(0))
分类
x = F.relu(self.lin1(x))
x = F.dropout(x, p=self.dropout_ratio, training=self.training)
x = F.relu(self.lin2(x))
x = F.log_softmax(self.lin3(x), dim=-1)
总结
SAGPool相当于在Graph U-net基础上修改了它的得分函数。Graph U-net的得分函数是通过一个向量映射成一维得到的,只考虑了节点特征。SAGPool通过GCN得到得分,考虑了节点结构。