手把手教你自定义一个Druid Filter记录sql,并结合Nacos实现动态开关和判断阈值调整
一、背景
Durid是一款应用比较广泛的数据库连接池,其性能优越、监控机制强大,并且还支持通过filter的机制进行扩展。
Druid自带一个StatFilter可以进行慢sql记录,但我在使用中发现一些不足:
- 此Filter打印日志为ERROR级别,当系统监控错误日志时可能会频繁触发告警,
- 判断阈值只能在配置文件中进行设置,不支持动态调整,
- 只实现了日志打印,而不能进行后续统计等功能
因此尝试使用一个自定义的Filter来记录慢Sql,并实现动态开关及阈值调整。
自定义Filter除了实现特定方法外,还需要将其加入DruidDataSource的Filter链中。一般情况下需要手动add到dataSource的filter集合中。而在SpringBoot环境下,只要将自定义的Filter声明为Component即可自动装配到FilterChain中不需要额外配置。
参考文章:
自定义Druid的拦截器
Nacos快速入门:启动Nacos Server(控制台服务)
Nacos快速入门:整合SpringBoot实现配置管理和服务发现
二、自定义Druid Filter
1. 主要步骤:
- 继承FilterEventAdapter类,并实现4个方法,后序拦截所有类型的sql执行:
- statementExecuteUpdateAfter()
- statementExecuteQueryAfter()
- statementExecuteAfter()
- statementExecuteBatchAfter()
- 声明两个属性:logSwitch、slowSqlMillis,加上nacos的注解用于动态配置
- 新增方法,在执行完sql后对执行时间进行判断,并记录sql语句及参数(这里主要参照了StatFilter中的代码),打印为warn日志
- 这里还可自行扩展,将sql记录发送到mq、es、或其他数据库等,进行后续统计监控
- 开启Druid自带StatFilter:
- application.propertis:
spring.datasource.druid.filter.stat.enabled=true
- application.propertis:
2. 完整代码:
@Slf4j
@Component
public class CustomDruidStatLogFilter extends FilterEventAdapter {
private static final Pattern LINE_BREAK = Pattern.compile("\n");
private static final Pattern BLANKS = Pattern.compile(" +");
private static final String BLANK = " ";
/**
* 开启状态
* (此注解表示此属性为nacos动态属性,对应配置中logSwitch对应的值,默认为true,且支持动态刷新)
*/
@NacosValue(value = "${logSwitch:true}", autoRefreshed = true)
private boolean logSwitch;
/**
* 慢sql判断阈值(毫秒)
*/
@NacosValue(value = "${slowSqlMillis:100}", autoRefreshed = true)
private long slowSqlMillis;
@Override
protected void statementExecuteUpdateAfter(StatementProxy statement, String sql, int updateCount) {
internalAfterStatementExecute(statement);
}
@Override
protected void statementExecuteQueryAfter(StatementProxy statement, String sql, ResultSetProxy resultSet) {
internalAfterStatementExecute(statement);
}
@Override
protected void statementExecuteAfter(StatementProxy statement, String sql, boolean firstResult) {
internalAfterStatementExecute(statement);
}
@Override
protected void statementExecuteBatchAfter(StatementProxy statement, int[] result) {
internalAfterStatementExecute(statement);
}
/**
* 核心记录方法:判断记录慢sql
*/
private void internalAfterStatementExecute(StatementProxy statement) {
if (logSwitch) {
if (statement.getSqlStat() != null) {
long nanos = System.nanoTime() - statement.getLastExecuteStartNano();
long millis = nanos / (1000 * 1000);
if (millis >= slowSqlMillis) {
String slowParameters = buildSlowParameters(statement);
String sql = statement.getLastExecuteSql();
sql = LINE_BREAK.matcher(sql).replaceAll(BLANK);
sql = BLANKS.matcher(sql).replaceAll(BLANK);
// 打印日志。还可自行替换为使用数据库等方式来保存,用于后续统计
log.warn("slow sql [" + millis + "] millis, sql: [" + sql + "], params: "
+ slowParameters);
}
}
}
}
/**
* 组装查询参数
*/
private String buildSlowParameters(StatementProxy statement) {
JSONWriter out = new JSONWriter();
out.writeArrayStart();
for (int i = 0, parametersSize = statement.getParametersSize(); i < parametersSize; ++i) {
JdbcParameter parameter = statement.getParameter(i);
if (i != 0) {
out.writeComma();
}
if (parameter == null) {
continue;
}
Object value = parameter.getValue();
if (value == null) {
out.writeNull();
} else if (value instanceof String) {
String text = (String) value;
if (text.length() > 100) {
out.writeString(text.substring(0, 97) + "...");
} else {
out.writeString(text);
}
} else if (value instanceof Number) {
out.writeObject(value);
} else if (value instanceof java.util.Date) {
out.writeObject(value);
} else if (value instanceof Boolean) {
out.writeObject(value);
} else if (value instanceof InputStream) {
out.writeString("" );
} else if (value instanceof NClob) {
out.writeString("" );
} else if (value instanceof Clob) {
out.writeString("" );
} else if (value instanceof Blob) {
out.writeString("" );
} else {
out.writeString('<' + value.getClass().getName() + '>');
}
}
out.writeArrayEnd();
return out.toString();
}
}
三、测试效果
1. 准备
1.1 建表
主要保存NAME和PHONE两个字段,其中PHONE创建了索引
CREATE TABLE `USER`(
`ID` INT(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`PHONE` VARCHAR(60) NOT NULL DEFAULT '' COMMENT '手机号',
`NAME` VARCHAR(60) NOT NULL DEFAULT '' COMMENT '姓名',
`CREATE_TIME` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`UPDATE_TIME` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`ID`),
KEY `idx_phone` (`PHONE`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT ='用户表'
1.2 初始化数据
向USER 表插入50000条数据,数据格式如下。
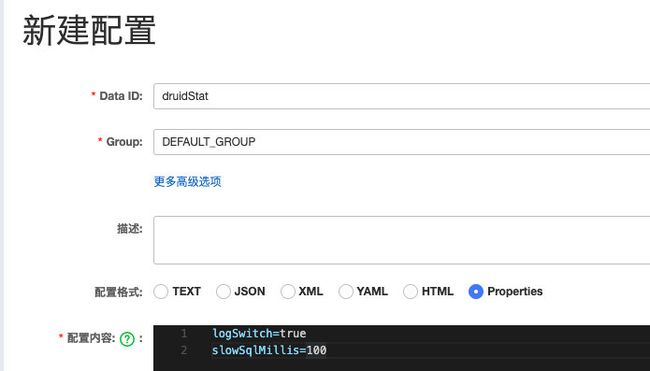
1.3 初始化nacos配置
通过nacos控制台发布配置:
1.4 查询代码
测试使用了Mybatis-plus进行查询
使用定时任务,每隔5s分别使用随机的name和phone去查询USER表
@Component
@Slf4j
public class QueryDataJob {
@Autowired
private UserMapper userMapper;
/** 使用随机姓名查询 */
@Scheduled(fixedRate = 5000)
public void queryByName() {
int randomIndex = RandomUtil.randomInt(0, 100000);
String randomName = "TestName" + randomIndex;
User query = new User();
query.setName(randomName);
List<User> result = userMapper.select(query);
log.info("query by name,result:{}", JSONUtil.toJsonStr(result));
}
/** 使用随机手机号(建有索引)查询 */
@Scheduled(fixedRate = 5000)
public void queryByPhone(){
int randomIndex = RandomUtil.randomInt(0, 100000);
String randomName = "TestName" + randomIndex;
User query = new User();
query.setPhone(randomName);
List<User> result = userMapper.select(query);
log.info("query by phone,result:{}", JSONUtil.toJsonStr(result));
}
}
2. 慢SQL记录
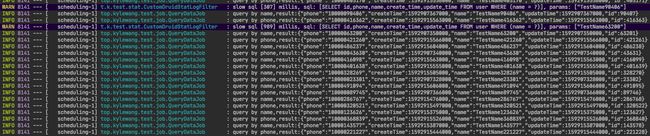
由于使用name查询时,没有走索引,sql执行时间较长,超过了100ms,通过CustomDruidStatLogFilter的warn日志记录下来:

3. 动态调整
尝试调整nacos配置,来改变记录结果:
3.1 开启/关闭
-
在nacos控制台将logSwitch设置为false:

-
发布配置后,慢sql记录不再打印日志,说明logSwitch配置动态调整生效:
3.2 调整判断阈值
- 将logSwitch开启,并将判断阈值设置为1ms:

-
两个查询都被记录了下来,阈值动态调整生效:

-
全部测试完成