使用Canal同步MySQL到ES
[hadoop@hadoop003 software]$ tar -xzvf elasticsearch-7.4.0-linux-x86_64.tar.gz -C ../app/
[hadoop@hadoop003 software]$ ln -s elasticsearch-7.4.0 elasticsearch
[hadoop@hadoop003 software]$ sudo vi /etc/profile
#elasticsearch
export ES_HOME=/home/hadoop/app/elasticsearch
export PATH=${ES_HOME}/bin:$PATH
[hadoop@hadoop003 software]$ source /etc/profile
调整最大虚拟内存
[hadoop@hadoop003 software]$ sudo vi /etc/sysctl.conf
vm.max_map_count=262144
[hadoop@hadoop003 software]$ sudo sysctl -p
vm.swappiness = 0
net.ipv4.neigh.default.gc_stale_time = 120
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.default.arp_announce = 2
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_announce = 2
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 1024
net.ipv4.tcp_synack_retries = 2
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
kernel.sysrq = 1
vm.max_map_count = 262144
[hadoop@hadoop003 app]$ vi $ES_HOME/config/elasticsearch.yml
network.host: 0.0.0.0
discovery.seed_hosts: ["hadoop003"]
启动ES
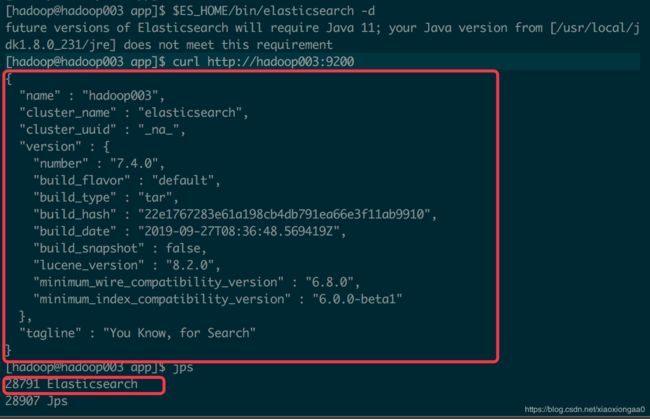
[hadoop@hadoop003 app]$ $ES_HOME/bin/elasticsearch -d
[hadoop@hadoop003 app]$ curl http://hadoop003:9200
安装Kibana
[hadoop@hadoop003 software]$ tar -zxvf kibana-7.4.0-linux-x86_64.tar.gz -C ../app/
[hadoop@hadoop003 app]$ ln -s kibana-7.4.0-linux-x86_64 kibana
[hadoop@hadoop003 app]$ sudo vi /etc/profile
export KIBANA_HOME=/home/hadoop/app/kibana
export PATH=${KIBANA_HOME}/bin:$PATH
[hadoop@hadoop003 app]$ source /etc/profile
[hadoop@hadoop003 app]$ vi $KIBANA_HOME/config/kibana.yml
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://canal01:9200"]
启动Kibana
[hadoop@hadoop003 app]$ nohup $KIBANA_HOME/bin/kibana > $KIBANA_HOME/kibana.out 2>&1 &
同步流程是MySQL-->Canal-Server(Instance)--->ClientAdapter--->ES,所涉及组件的关系如下:
准备业务库表
mysql> CREATE DATABASE IF NOT EXISTS test DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected, 2 warnings (0.01 sec)
mysql> use test;
Database changed
mysql> DROP TABLE IF EXISTS `test`;
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> CREATE TABLE `test` (
-> `uid` INT UNSIGNED AUTO_INCREMENT,
-> `name` VARCHAR(100) NOT NULL,
-> `age` int(3) DEFAULT NULL,
-> `modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
-> PRIMARY KEY (`uid`)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected, 2 warnings (0.04 sec)
配置Instance
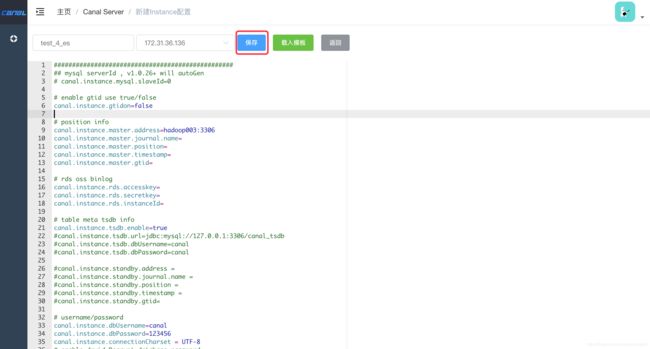
前面安装了Canal_Server,接下来需要给Canal_Server创建Instance来拉取MySQL的binlog。
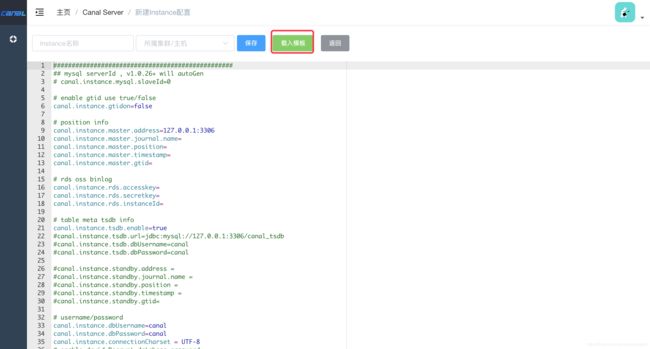
Instance配置不需要从零开始写,先载入模板即可,如下图:
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=hadoop003:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=123456
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=example
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################
mysql 数据解析关注的表,Perl正则表达式. 多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\) 常见例子:
1. 所有表:.* or .*\\..*
2. canal schema下所有表: canal\\..*
3. canal下的以canal打头的表:canal\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔)
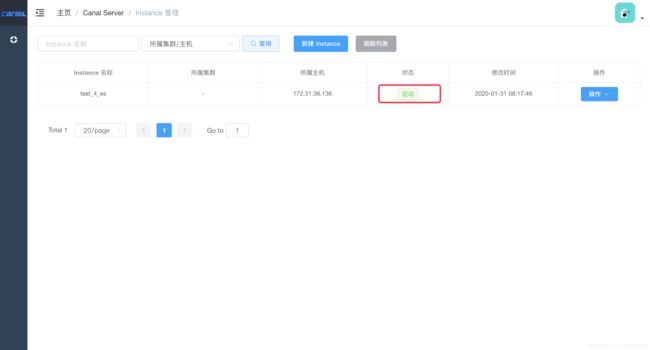
刷新Instance列表页,过一会就已经变成启动状态了:
至此,MySQL的binlog数据就可以被Canal-Server拉取到了
查看一下日志
或者到/home/hadoop/app/canal-server/logs/test_4_es这个目录下查看
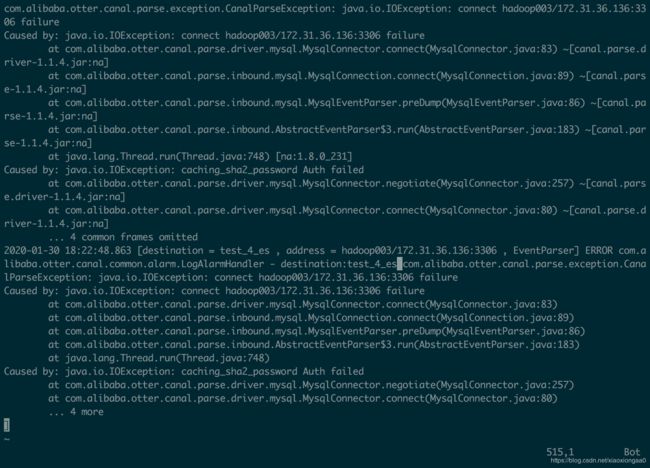
目测账号密码不对,排查一下
mysql> set global validate_password_policy=0;
Query OK, 0 rows affected (0.00 sec)
mysql> set global validate_password_mixed_case_count=0;
Query OK, 0 rows affected (0.00 sec)
mysql> set global validate_password_number_count=3;
Query OK, 0 rows affected (0.00 sec)
mysql> set global validate_password_special_char_count=0;
Query OK, 0 rows affected (0.00 sec)
mysql> set global validate_password_length=3;
Query OK, 0 rows affected (0.00 sec)
mysql> select password('canal');
+-------------------------------------------+
| password('canal') |
+-------------------------------------------+
| *E3619321C1A937C46A0D8BD1DAC39F93B27D4458 |
+-------------------------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> select password('admin');
+-------------------------------------------+
| password('admin') |
+-------------------------------------------+
| *4ACFE3202A5FF5CF467898FC58AAB1D615029441 |
+-------------------------------------------+
1 row in set, 1 warning (0.00 sec)
又是百思不得其解,重新把密码改为123456,然后查看日志,竟然好了,很奇怪
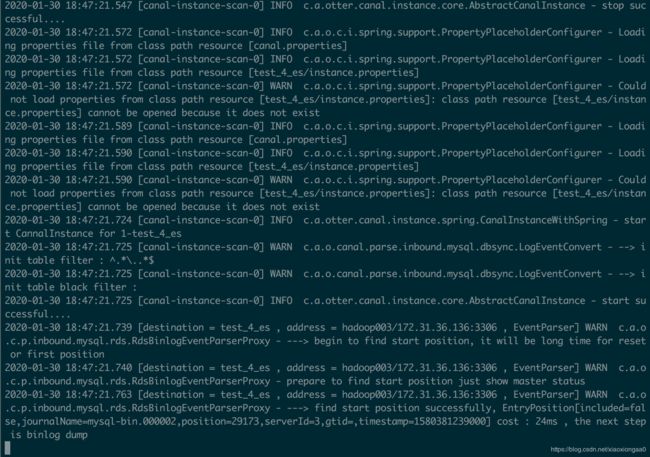
所以下次遇到类似情况,重启一下instance即可
继续
安装配置ClientAdapter
[hadoop@hadoop003 software]$ mkdir ../app/canal-adapter
[hadoop@hadoop003 software]$ tar -zxvf canal.adapter-1.1.5-SNAPSHOT.tar.gz -C ../app/canal-adapter/
[hadoop@hadoop003 software]$ cd ../app/canal-adapter;
[hadoop@hadoop003 canal-adapter]$ sudo vi /etc/profile
#canal-adapter
export CANAL_ADAPTER_HOME=/home/hadoop/app/canal-adapter
export PATH=${CANAL_ADAPTER_HOME}/bin:$PATH
[hadoop@hadoop003 canal-adapter]$ source /etc/profile
[hadoop@hadoop003 canal-adapter]$ vi $CANAL_ADAPTER_HOME/conf/application.yml
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp # kafka rocketMQ
canalServerHost: hadoop003:11111
# zookeeperHosts: slave1:2181
# mqServers: 127.0.0.1:9092 #or rocketmq
# flatMessage: true
batchSize: 500
syncBatchSize: 1000
retries: 0
timeout:
accessKey:
secretKey:
username:canal
password:123456
vhost:
srcDataSources:
defaultDS:
url: jdbc:mysql://hadoop003:3306/mytest?useUnicode=true
username: canal
password: 123456
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
# - name: rdb
# key: mysql1
# properties:
# jdbc.driverClassName: com.mysql.jdbc.Driver
# jdbc.url: jdbc:mysql://127.0.0.1:3306/mytest2?useUnicode=true
# jdbc.username: root
# jdbc.password: 121212
# - name: rdb
# key: oracle1
# properties:
# jdbc.driverClassName: oracle.jdbc.OracleDriver
# jdbc.url: jdbc:oracle:thin:@localhost:49161:XE
# jdbc.username: mytest
# jdbc.password: m121212
# - name: rdb
# key: postgres1
# properties:
# jdbc.driverClassName: org.postgresql.Driver
# jdbc.url: jdbc:postgresql://localhost:5432/postgres
# jdbc.username: postgres
# jdbc.password: 121212
# threads: 1
# commitSize: 3000
# - name: hbase
# properties:
# hbase.zookeeper.quorum: 127.0.0.1
# hbase.zookeeper.property.clientPort: 2181
# zookeeper.znode.parent: /hbase
- name: es
hosts: hadoop003:9300 # 127.0.0.1:9200 for rest mode
properties:
mode: transport # or rest
# security.auth: test:123456 # only used for rest mode
cluster.name: elasticsearch
[hadoop@hadoop003 es7]$ vi $CANAL_ADAPTER_HOME/conf/es7/test_test.yml
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
destination: test_to_es # cannal的instance或者MQ的topic
groupId: g1 # 对应MQ模式下的groupId, 只会同步对应groupId的数据
esMapping:
_index: test_test # es 的索引名称
_id: _id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配
# pk: uid # 如果不需要_id, 则需要指定一个属性为主键属性
upsert: true
# sql映射
sql: "select a.uid as _id, a.name, a.age, a.modified_time from test a"
# objFields:
# # # #
# _labels: array:; # 数组或者对象属性, array:; 代表以;字段里面是以;分隔的
# _obj: object # json对象
# etlCondition: "where a.c_time>='{0}'" # etl 的条件参数
commitBatch: 2 # 提交批大小(生产上要大一些,这里设置为2)
sql支持多表关联自由组合, 但是有一定的限制:
-
主表不能为子查询语句
-
只能使用left outer join即最左表一定要是主表
-
关联从表如果是子查询不能有多张表
-
主sql中不能有where查询条件(从表子查询中可以有where条件但是不推荐, 可能会造成数据同步的
不一致, 比如修改了where条件中的字段内容)
-
关联条件只允许主外键的'='操作不能出现其他常量判断比如: on a.role_id=b.id and b.statues=1
-
关联条件必须要有一个字段出现在主查询语句中比如: on a.role_id=b.id 其中的 a.role_id 或者 b.id 必须出现在主select语句中
Elastic Search的mapping 属性与sql的查询值将一一对应(不支持 select *), 比如: select a.id as id, a.name, a.email as _email from user, name es mapping name field, _email mapping email field, 这里以别名(如果有别名)作为最终的映射字段. 这里的_id可以填写到配置文件的 _id: _id映射.
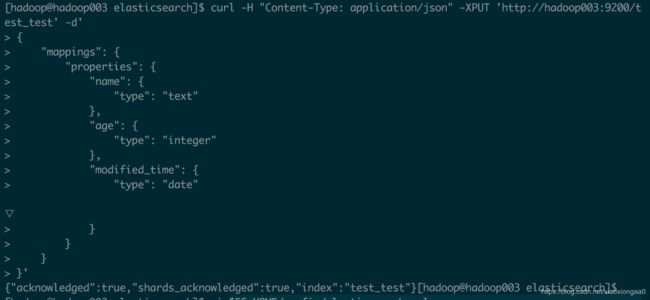
创建ES索引
[hadoop@hadoop003 elasticsearch]$ curl -H "Content-Type: application/json" -XPUT 'http://hadoop003:9200/test_test' -d'
> {
> "mappings": {
> "properties": {
> "name": {
> "type": "text"
> },
> "age": {
> "type": "integer"
> },
> "modified_time": {
> "type": "date"
> }
> }
> }
> }'
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"modified_time": {
"type": "date"
}
}
}
}
报错

解决方法:
配置文件$ES_HOME/config/elasticsearch.yml添加cluster.initial_master_nodes: ["hadoop003"],然后重启
替换MySQL驱动包
[hadoop@hadoop003 elasticsearch]$ ln -s /usr/share/java/mysql-connector-java-8.0.18.jar $CANAL_ADAPTER_HOME/lib/mysql-connector-java-8.0.18.jar
[hadoop@hadoop003 elasticsearch]$ mv $CANAL_ADAPTER_HOME/lib/mysql-connector-java-5.1.47.jar $CANAL_ADAPTER_HOME/lib/mysql-connector-java-5.1.47.jar.bak
启动适配器
![]()
问题原因是要执行的bash脚本换行符为“\r\n”,而在Linux下执行需要换行符合“\n”
:set ff=unix
stop脚本也需要设置
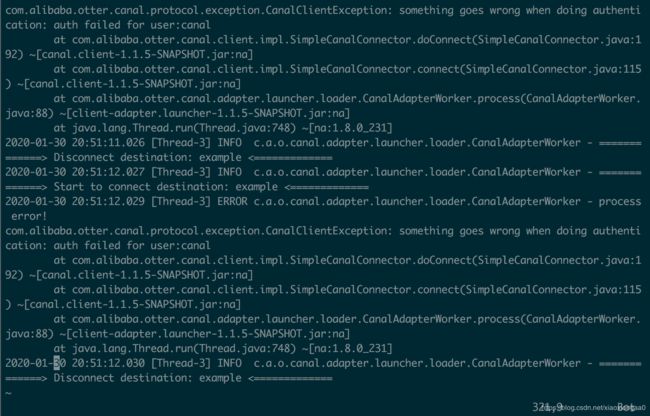
报错
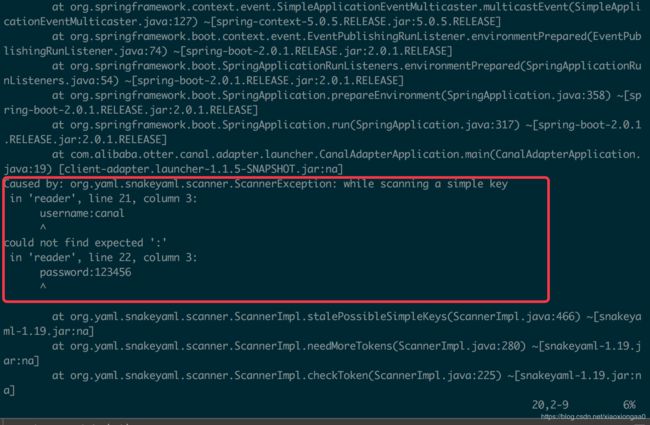
解决方案
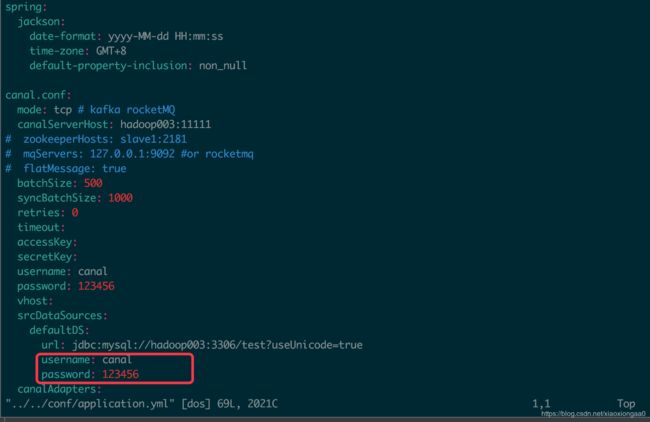
冒号后面要有一个空格,检查清楚
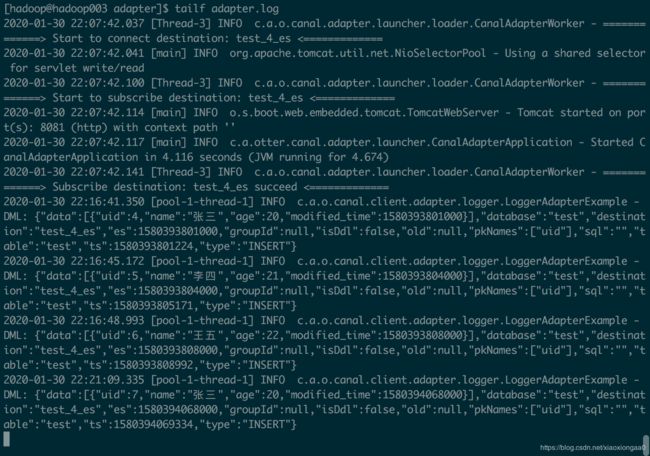
修改完成之后重新启动,并查看日志如下,发现暂时没有报错
[hadoop@hadoop003 adapter]$ curl -XGET 'http://hadoop003:9200/_search'

这里有个坑
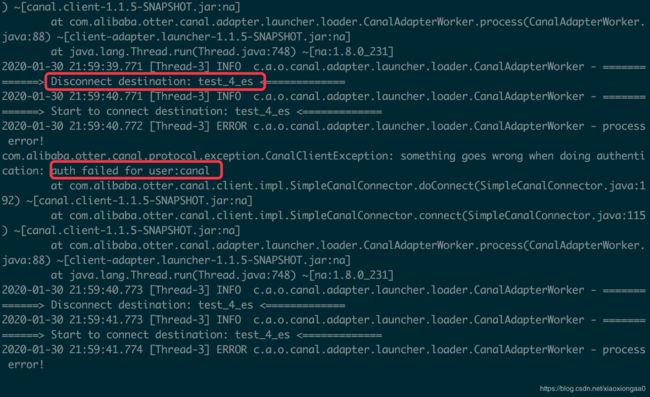
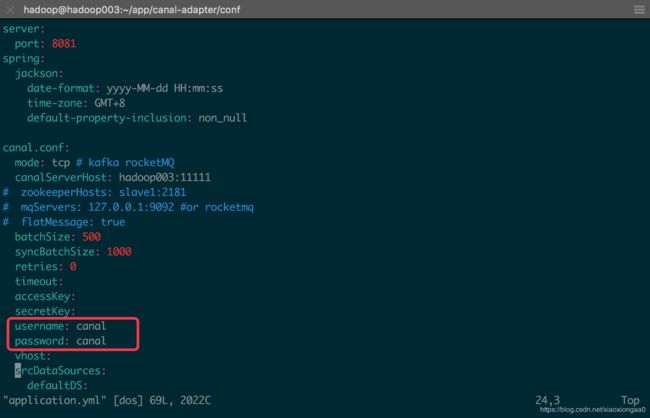
这里的解决方法必须是/home/hadoop/app/canal-adapter/conf/application.yml配置下用户和密码必须同为canal
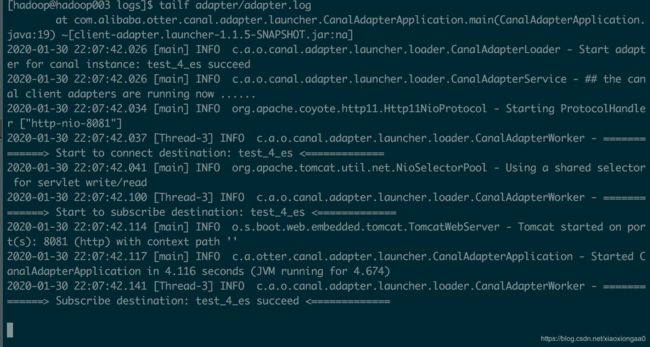
插入几条数据,adapter马上就能收到