ELK安装文档
一. 安装准备
系统:Centos7.2
JDK:1.8
Elasticsearch-6.0.0
Logstash-6.0.0
Kibana-6.0.0
二. JDK安装
因为ELK6.0.0所支持的jdk环境必须在1.8以上所以必须安装1.8以上。如果你所面临的环境jdk1.7,可以给目录单独配置jdk1.8以上环境,亲测可用。
三.ELK安装
ELK 其实并不是一款软件,而是一整套解决方案,是三个软件产品的首字母缩写,Elasticsearch,Logstash 和 Kibana。这三款软件都是开源软件,通常是配合使用,而且又先后归于 Elastic.co 公司名下,故被简称为 ELK 协议栈。
其安装步骤:
2.3.1 Elasticsearch 安装部署
1 准备工作及下载
1 创建用户
创建一个es专门的用户(必须),因为es不能用root用户启动
使用root用户在三台机器执行以下命令
[root@node01 Elasticsearch] useradd es
[root@node01 Elasticsearch] mkdir -p /export/servers/es
[root@node01 Elasticsearch] mkdir -p /export/data/es
[root@node01 Elasticsearch] mkdir -p /export/logs/es
[root@node01 Elasticsearch] chown -R es /export/servers/es
[root@node01 Elasticsearch] chown -R es /export/data/es
[root@node01 Elasticsearch] chown -R es /export/logs/es
[root@node01 Elasticsearch] passwd es2为es用户添加sudo权限
机器使用root用户执行visudo然后为es用户添加权限
(如果搭建是集群,该对每台机器都进行权限的赋予)
[root@node01 Elasticsearch] visudo
es ALL=(ALL) ALL3下载安装包
关闭我们的xshll的所有的会话,重新连接,一定要记得使用es的用户来连接我们的linux服务器
第一台服务器切换到es用户下,下载安装包(我下载的是6.0.0版本,如果有特殊的需求去官网主动下载 )
[root@node01 Elasticsearch]su es
[es@node01 Elasticsearch]cd ~
[es@node01 Elasticsearch]wget
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.0.0.tar.gz
[es@node01 Elasticsearch]tar -zxvf elasticsearch-6.0.0.tar.gz -C /export/servers/es/4 第一台服务器修改配置文件
[es@node01 Elasticsearch]cd /export/servers/es/elasticsearch-6.0.0/config
[es@node01 Elasticsearch]rm elasticsearch.yml
[es@node01 Elasticsearch]vi elasticsearch.yml
# 集群名字
cluster.name:node01
# # 集群中当前的节点
node.name: node01
# # 数据目录
path.data: /export/data/es
# # 日志目录
path.logs: /export/logs/es
# # 当前主机的ip地址
network.host: 192.168.8.148
http.port: 9200
# # 集群上的节点信息
discovery.zen.ping.unicast.hosts: ["node01","node02","node03"]
# # linux安装es的一个bug解决的配置
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
# # 是否支持跨域
http.cors.enabled: true
# # *表示支持所有域名
http.cors.allow-origin: "*"
5 安装包分发到其他两台机器上(如果没有搭建集群可以省略)
node01服务器执行以下命令
[root@node01 Elasticsearch] cd /export/servers/es
[root@node01 Elasticsearch]scp -r elasticsearch-6.0.0/ node02:$PWD
[root@node01 Elasticsearch]scp -r elasticsearch-6.0.0/ node03:$PWD
6 node02与node03服务器修改配置文件
node02服务器修改配置文件
[root@node02 Elasticsearch] cd /export/servers/es/elasticsearch-6.0.0/config
[root@node02 Elasticsearch] vim elasticsearch.yml
cluster.name: myes
node.name: node02
path.data: /export/data/es
path.logs: /export/logs/es
network.host: 192.168.8.149
http.port: 9200
discovery.zen.ping.unicast.hosts: ["node01","node02","node03"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
# 是否支持跨域
http.cors.enabled: true
# *表示支持所有域名
http.cors.allow-origin: "*"node03服务器修改配置文件
[root@node03 Elasticsearch] cd /export/servers/es/elasticsearch-6.0.0/config
[root@node03 Elasticsearch] vim elasticsearch.yml
cluster.name: myes
node.name: node03
path.data: /export/data/es
path.logs: /export/logs/es
network.host: 192.168.8.150
http.port: 9200
discovery.zen.ping.unicast.hosts: ["node01","node02","node03"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
# 是否支持跨域
http.cors.enabled: true
# *表示支持所有域名
http.cors.allow-origin: "*"
7 三台机器修改jvm内存大小
三台机器执行以下命令修改jvm内存大小
[root@node01 Elasticsearch] cd /export/servers/es/elasticsearch-6.0.0/config
[root@node01 Elasticsearch] vi jvm.options
-Xms2g
-Xmx2g
8、三台机器修改系统配置,增加打开文件的最大数量
问题一:max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错
三台机器执行以下命令解除打开文件数据的限制
[root@node01 Elasticsearch] sudo vi /etc/security/limits.conf
添加如下内容: 注意*不要去掉了
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
问题二:max number of threads [1024] for user [es] likely too low, increase to at least [4096]
修改普通用户可以创建的最大线程数
max number of threads [1024] for user [es] likely too low, increase to at least [4096]
原因:无法创建本地线程问题,用户最大可创建线程数太小
解决方案:修改90-nproc.conf 配置文件。
三台机器执行以下命令修改配置文件
[root@node01 Elasticsearch] sudo vi /etc/security/limits.d/90-nproc.conf
找到如下内容:
* soft nproc 1024
#修改为
* soft nproc 4096
问题三:max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
调大系统的虚拟内存
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
原因:最大虚拟内存太小
每次启动机器都手动执行下。
三台机器执行以下命令,注意每次启动ES之前都要执行
[root@node01 Elasticsearch] sudo sysctl -w vm.max_map_count=262144
备注:以上三个问题解决完成之后,重新连接secureCRT或者重新连接xshell生效
需要保存、退出、重新登录xshell才可生效。
9 启动es服务
启动
注意啦,这里是后台启动,要发现错误的话,去/export/logs/es目录下查看。
[es@node01 Elasticsearch]nohup /export/servers/es/elasticsearch-6.0.0/bin/elasticsearch >/dev/null 2>&1 &
10 访问es
在Google Chrome浏览器中,访问以下地址
http://node01:9200/?pretty
pretty:格式化的,漂亮的。
得到以下内容
{
"name" : "node01",
"cluster_name" : "node01",
"cluster_uuid" : "rUjaOAuZRdyXKXfgthzl5A",
"version" : {
"number" : "6.0.0",
"build_hash" : "8f0685b",
"build_date" : "2017-11-10T18:41:22.859Z",
"build_snapshot" : false,
"lucene_version" : "7.0.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
2.3.2 安装elasticsearch-head插件
1 node01机器安装nodejs
Node.js是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
Node.js是一个Javascript运行环境(runtime environment),发布于2009年5月,由Ryan Dahl开发,实质是对Chrome V8引擎进行了封装。Node.js 不是一个 JavaScript 框架,不同于CakePHP、Django、Rails。Node.js 更不是浏览器端的库,不能与 jQuery、ExtJS 相提并论。Node.js 是一个让 JavaScript 运行在服务端的开发平台,它让 JavaScript 成为与PHP、Python、Perl、Ruby 等服务端语言平起平坐的脚本语言。
第一步:下载安装包
# 下载安装包
node01机器执行以下命令下载安装包
[es@node01 Elasticsearch] cd /home/es
[es@node01 Elasticsearch]wget https://npm.taobao.org/mirrors/node/v8.1.0/node-v8.1.0-linux-x64.tar.gz
第二步:解压安装包
执行以下命令进行解压
[es@node01 Elasticsearch]cd /home/es
[es@node01 Elasticsearch]tar -zxvf node-v8.1.0-linux-x64.tar.gz -C /export/servers/es/第三步:创建软连接
# 修改目录
执行以下命令创建软连接
[es@node01 Elasticsearch] sudo ln -s /export/servers/es/node-v8.1.0-linux-x64/lib/node_modules/npm/bin/npm-cli.js /usr/local/bin/npm
[es@node01 Elasticsearch] sudo ln -s /export/servers/es/node-v8.1.0-linux-x64/bin/node /usr/local/bin/node第四步:修改环境变量
#修改环境变量
[es@node01 Elasticsearch] sudo vim /etc/profile
export NODE_HOME=/export/servers/es/node-v8.1.0-linux-x64
export PATH=:$PATH:$NODE_HOME/bin
[es@node01 Elasticsearch] source /etc/profile
第五步:验证安装成功
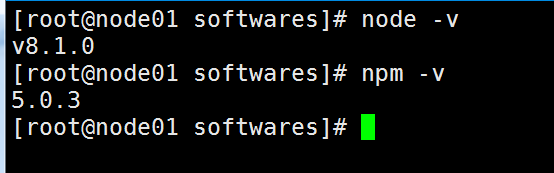
2.node01机器安装elasticsearch-head
第一步:上传压缩包到/home/es路径下去
将我们的压缩包elasticsearch-head-compile-after.tar.gz 上传到第一台机器的/home/es路径下面去
第二步:解压安装包
[es@node01 Elasticsearch] cd /home/es/
[es@node01 es] tar -zxvf elasticsearch-head-compile-after.tar.gz -C /export/servers/es/第三步、node01机器修改Gruntfile.js
修改Gruntfile.js这个文件
[es@node01 es] cd /export/servers/es/elasticsearch-head
[es@node01 elasticsearch-head] vim Gruntfile.js
找到以下代码:
添加一行: hostname: '192.168.52.100',
connect: {
server: {
options: {
hostname: '192.168.8.148',
port: 9100,
base: '.',
keepalive: travelue
}
}
}
第四步、node01机器修改app.js
第一台机器修改app.js
[es@node01 es] cd /export/servers/es/elasticsearch-head/_site
[es@node01 es] vim app.js

更改前:http://localhost:9200
更改后:http://node01:9200
注:配置文件的最后面修改 IP
3、重启es服务
注意:使用es用户启动
直接使用kill -9 杀死三台机器的es服务,然后重新启动
[es@node01 es] nohup /export/servers/es/elasticsearch-6.0.0/bin/elasticsearch >/dev/null 2>&1 &4、node01机器启动head服务
node01启动elasticsearch-head插件
[es@node01 es] cd /export/servers/es/elasticsearch-head/node_modules/grunt/bin/进程前台启动命令
[es@node01 bin] ./grunt server进程后台启动命令
[es@node01 bin] nohup ./grunt server >/dev/null 2>&1 &
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://192.168.52.100:9100
杀死elasticsearch-head进程
[es@node01 bin] netstat -nltp | grep 9100
[es@node01 bin] kill -9 8328

5、访问elasticsearch-head界面
打开Google Chrome访问
http://192.168.52.100:9100/
2.3.3服务器安装Kibana
kibana的基本介绍
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。
你用Kibana来搜索,查看,并和存储在Elasticsearch索引中的数据进行交互。
你可以轻松地执行高级数据分析,并且以各种图标、表格和地图的形式可视化数据。
Kibana使得理解大量数据变得很容易。它简单的、基于浏览器的界面使你能够快速创建和共享动态仪表板,实时显示Elasticsearch查询的变化。
接着使用我们的es用户来实现我们的kibana的安装部署
1、下载资源
[es@node01 ~] cd /home/es
[es@node01 es]
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.0.0-linux-x86_64.tar.gz
- 解压文件
[es@node01 es] tar -zxvf kibana-6.0.0-linux-x86_64.tar.gz -C /export/servers/es/
- 修改配置文件
[es@node01 es] vim /export/servers/es/kibana-6.0.0-linux-x86_64/configkibana.yml配置内容如下:
server.host: "node01"
elasticsearch.url: "http://node01:9200"4、启动服务
[es@node01 es] cd /export/servers/es/kibana-6.0.0-linux-x86_64
[es@node01 kibana-6.0.0-linux-x86_64] nohup bin/kibana >/dev/null 2>&1 &停止kibana服务进程
查看进程号
[es@node01 es] ps -ef | grep node然后使用kill -9杀死进程即可
5、访问
浏览器地址访问kibana服务
http://192.168.52.100:5601
2.3.4LogStash安装部署
1. 介绍
logstash就是一个具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。是一个input | filter | output 的数据流。
2 . node01机器安装LogStash
下载logstache并上传到第一台服务器的/home/es路径下,然后进行解压
# 下载安装包---可以直接将已经下载好的安装包上传到/home/es路径下即可
[es@node01 security] cd /home/es
[es@node01 es] wget https://artifacts.elastic.co/downloads/logstash/logstash-6.0.0.tar.gz
# 解压
[es@node01 es] tar -zxvf logstash-6.0.0.tar.gz -C /export/servers/es/3. Input插件
stdin标准输入和stdout标准输出
使用标准的输入与输出组件,实现将我们的数据从控制台输入,从控制台输出
[es@node01 es] cd /export/servers/es/logstash-6.0.0
[es@node01 logstash-6.0.0] bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'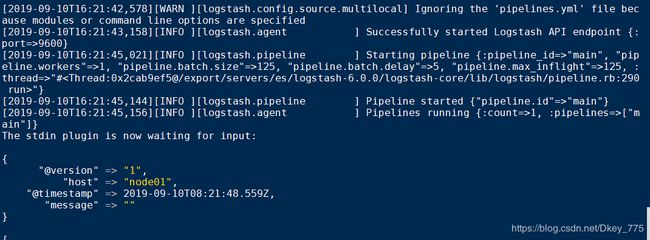
4. 监控日志文件变化
Logstash 使用一个名叫 FileWatch 的 Ruby Gem 库来监听文件变化。这个库支持 glob 展开文件路径,而且会记录一个叫 .sincedb 的数据库文件来跟踪被监听的日志文件的当前读取位置。所以,不要担心 logstash 会漏过你的数据。
编写脚本
[es@node01 logstash-6.0.0] cd /export/servers/es/logstash-6.0.0/config
[es@node01 config] vim monitor_file.conf
#输入一下信息
input{
file{
path => "/export/servers/es/datas/tomcat.log"
type => "log"
start_position => "beginning"
}
}
output{
stdout{
codec=>rubydebug
}
}检查配置文件是否可用
[es@node01 config] cd /export/servers/es/logstash-6.0.0/
[es@node01 logstash-6.0.0] bin/logstash -f /export/servers/es/logstash-6.0.0/config/monitor_file.conf -t
成功会出现一下信息:
Config Validation Result: OK. Exiting Logstash
启动服务
[es@node01 logstash-6.0.0] bin/logstash -f /export/servers/es/logstash-6.0.0/config/monitor_file.conf
发送数据
新开xshell窗口通过以下命令发送数据
[es@node01 logstash-6.0.0] mkdir -p /export/servers/es/datas
[es@node01 logstash-6.0.0] echo "hello logstash" >> /export/servers/es/datas/tomcat.log- Output插件
标准输出到控制台
将我们收集的数据直接打印到控制台
output {
stdout {
codec => rubydebug
}
}[es@node01 logstash]$ bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
hello将采集数据保存到file文件中
第一步:开发logstash的配置文件
[es@node01 logstash] cd /export/servers/es/logstash-6.0.0/config
[es@node01 config] vim output_file.conf
i
nput {stdin{}}
output {
file {
path => "/export/servers/es/datas/%{+YYYY-MM-dd}-%{host}.txt"
codec => line {
format => "%{message}"
}
flush_interval => 0
}
}
第二步:检测配置文件并启动logstash服务
[es@node01 config] cd /export/servers/es/logstash-6.0.0
检测配置文件是否正确
[es@node01 logstash-6.0.0] bin/logstash -f config/output_file.conf -t
启动服务,然后从控制台输入一些数据
[es@node01 logstash-6.0.0] bin/logstash -f config/output_file.conf
查看文件写入的内容
[es@node01 logstash-6.0.0] cd /export/servers/es/datas
[es@node01 datas] more 2018-11-08-node01.hadoop.com.txt

将采集数据保存到elasticsearch
第一步:开发logstash的配置文件
[es@node01 ~] cd /export/servers/es/logstash-6.0.0/config
[es@node01 config] vim output_es.conf
input {stdin{}}
output {
elasticsearch {
hosts => ["node01:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}这个index是保存到elasticsearch上的索引名称,如何命名特别重要,因为我们很可能后续根据某些需求做查询,所以最好带时间,因为我们在中间加上type,就代表不同的业务,这样我们在查询当天数据的时候,就可以根据类型+时间做范围查询
第二步:检测配置文件并启动logstash
检测配置文件是否正确
[es@node01 config] cd /export/servers/es/logstash-6.0.0
[es@node01 logstash-6.0.0] bin/logstash -f config/output_es.conf -t
启动logstash
[es@node01 logstash-6.0.0] bin/logstash -f config/output_es.conf
第三步 :es当中查看数据
:es当中查看数据
访问
http://node01:9100/
查看es当中的数据
