python操作ElasticSearch-创建、插入、检索
文章目录
- 1. 介绍ES
- 2. 安装ES与打开
- 2.1 安装
- 2.2 打开
- 3. 创建索引
- 4. 插入数据
- 5. 检索数据
- 5.1 代码
- 5.2 结果
- 6. 下载
- 7. 其他资料
1. 介绍ES
引用:Elasticsearch入门(一):elasticsearc基础概念
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
Elasticsearch 权威指南(中文版)
1, Kibana可视化分析,可以插入,查询等。
2, 用python,java等 调用es的相应接口。这里主要用python。
2. 安装ES与打开
2.1 安装
可以参考 安装es教程
记得安装中文分词器。
2.2 打开
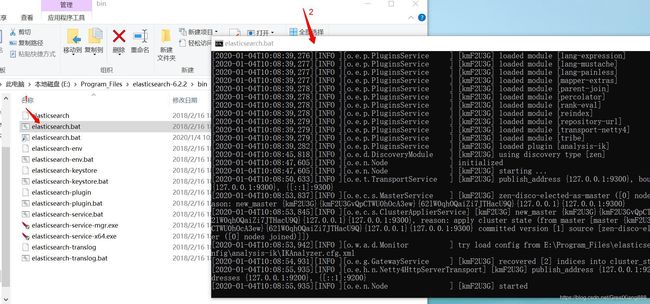
打开es服务器后,输入网址:
http://localhost:9200/ 检查es是否安装正确

打开成功。
3. 创建索引
相当于建数据库的表,和定义字段。
#####################创建索引####################################
from elasticsearch import Elasticsearch
es = Elasticsearch()
def deleteInices(my_index):
if True and es.indices.exists(my_index): #确认删除再改为True
print("删除之前存在的")
es.indices.delete(index=my_index)
def createIndex(my_index, my_doc):
# index settings
settings = \
{
"mappings": {
my_doc :{
"properties": {
"my_id":{"type": "integer"},
"my_word": {"type": "text","analyzer": "ik_smart","search_analyzer": "ik_smart"}
}
}
}
}
# create index
es.indices.create(index=my_index, ignore=400, body=settings)
print("创建index成功!")
def mainCreateIndex():
# 调用后创建index
my_index = "word2vec_index"
my_doc = "my_doc"
deleteInices(my_index)
createIndex(my_index, my_doc)
4. 插入数据
这里以bulk形式批量插入数据。
#####################插入数据####################################
from tqdm import tqdm #进度条
from elasticsearch import helpers
def getAllWords(path="vocab.txt"):
#将数据从文件读出
#文件格式:
#
words = []
with open(path, "r", encoding="utf-8") as f:
for i,item in enumerate(f.readlines()):
words.append((i,item.strip()))
return words
def insertData(words, my_index, my_doc, one_bulk):
#插入数据
#one_bulk表示一个bulk里装多少个
body = []
body_count = 0 #记录body里面有多少个.
#最后一个bulk可能没满one_bulk,但也要插入
print("共需要插入%d条..."%len(words))
pbar = tqdm(total=len(words))
for id,word in words:
data1 = { "my_id": id,
"my_word": word}
every_body = \
{
"_index": my_index,
"_type": my_doc,
"_source": data1
}
if body_count<one_bulk:
body.append(every_body)
body_count+=1
else:
helpers.bulk(es, body) #还是要用bulk啊,不然太慢了
pbar.update(one_bulk)
body_count = 0
body = []
body.append(every_body)
body_count+=1
if len(body)>0:
#如果body里面还有,则再插入一次(最后非整块的)
helpers.bulk(es, body)
# pbar.update(len(body))
print('done2')
pbar.close()
#res = es.index(index=my_index,doc_type=my_doc,id=my_key_id,body=data1) #一条插入
print("插入数据完成!")
def mainInsert():
# 调用后插入数据
my_index = "word2vec_index"
my_doc = "my_doc"
words = getAllWords(path="vocab.txt")
insertData(words, my_index, my_doc, one_bulk=5000)
5. 检索数据
5.1 代码
#####################检索数据####################################
def keywordSearch(keywords1, my_index, my_doc):
#根据keywords1来查找,倒排索引
my_search1 = \
{
"query" : {
"match" : {
"my_word" : keywords1
}
}
}
#直接查询
# res= es.search(index=my_index,body=my_search1)
# total = res["hits"]["total"] #一共这么多个
# print("共查询到%d条数据"%total)
#helpers查询
es_result = helpers.scan(
client=es,
query=my_search1,
scroll='10m',
index=my_index,
timeout='10m'
)
es_result = [item for item in es_result] #原始是生成器5.2 结果

6. 下载
包括完整代码,原始txt数据,我总结的es常用命令。
点击 python操作ElasticSearch 下载。
7. 其他资料
1, windows 中 elasticsearch启动报错ERROR: [1] bootstrap checks failed
2, ElasticSearch 6.1.1 通过Head插件,新建索引,添加文档,及其查询数据-java
3, 如何快速搭建出来自己的搜索系统
4, Elasticsearch(八)elasticsearch数据输入和输出
5, python 操作ES
6, Elasticsearch增、删、改、查操作深入详解
7, 深入详解Elasticsearch
8, Elasticsearch 权威指南(中文版)
结尾:
整个过程,我花了不少时间总结,并且自己创造了一些代码,若有帮助,还请点个赞多多支持。