TensorFlow + Keras 入门项目:Image Classification with CNN(基于Fashion-MNIST数据集)
OS:Win10
Interpreter: Python3.7
Environment: Anaconda3 + Tensorflow-gpu2.0.0 + Spyder+cuda10.0+cudnn7.6
API: tf.keras(a high-level API to build and train models in TensorFlow)
上一篇博客https://blog.csdn.net/Happy_hui520/article/details/95214357 里写了基于Fashion MNIST数据集的图像识别,使用了一个简单的全连接神经网络,这篇教程里着重写CNN(Convolutional Neural Networks) 的创建和训练,其它步骤与之前相同。训练卷积神经网络时适合使用GPU进行运算,不然速度会很慢,当然你要提前配置好TensorFlow-gpu的环境。
训练模型的时候直接从任务管理器中看GPU状态就知道有没有用上了,

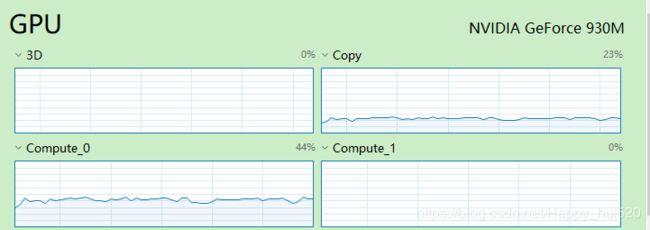
之前的步骤我就不复制粘贴了。下面直接写模型的建立和训练过程。
构建模型
设置网络层
The basic building block of a neural network is the layer. A layer extracts a representation from the data fed into it. Hopefully, a series of connected layers results in a representation that is meaningful for the problem at hand.
Much of deep learning consists of chaining together simple layers. Most layers, like
tf.keras.layers.Dense, have internal parameters which are adjusted ("learned") during training.
神经网络的基本构件是层。层从输入的数据中提取表示。令人高兴的是,通过一系列连接的层能得到对当前问题有意义的表示。
许多深度学习都是由简单层的链接组成的。大多数层,比如tf.keras.layers.Dense,有可在训练期间调整(“学习”)的内部参数。
下面创建的神经网络里包含了2个“卷积层+池化层”。
第一个卷积层是输入层,对输入的28*28的图片矩阵用32个 3*3 的卷积核(filter)进行卷积运算,得到28*28*32的矩阵。然后第一个最大值池化层(Max pooling layer)进行下采样(大小为2*2,步长为2)得到14*14*32的矩阵。
第二个卷积层对输入的14*14*32矩阵用64个 3*3 的卷积核进行卷积运算,得到14*14*64的矩阵,这一层的参数数量是weights+biases = 32*64*9 + 64 = 18496。然后第二个最大值池化层(Max pooling layer)进行下采样(大小为2*2,步长为2)得到7*7*64的矩阵。
然后是一个平滑层(3136,1),把池化层的64个7*7矩阵处理成一个数组,与后面的全连接层相连,参数数量就是权重和偏置的和 weights+biases = 3136*128+128=401536。
最后再通过一个全连接层(Output layer)以分类概率的形式输出结果。
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32,(3,3),padding='same', activation=tf.nn.relu,
input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D((2,2),strides=2),
tf.keras.layers.Conv2D(64, (3,3), padding='same', activation=tf.nn.relu),
tf.keras.layers.MaxPooling2D((2,2), strides=2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])This network layers are:
"convolutions"
tf.keras.layers.Conv2D and MaxPooling2D— Network start with two pairs of Conv/MaxPool. The first layer is a Conv2D filters (3,3) being applied to the input image, retaining the original image size by using padding, and creating 32 output (convoluted) images (so this layer creates 32 convoluted images of the same size as input). After that, the 32 outputs are reduced in size using a MaxPooling2D (2,2) with a stride of 2. The next Conv2D also has a (3,3) kernel, takes the 32 images as input and creates 64 outputs which are again reduced in size by a MaxPooling2D layer. So far in the course, we have described what a Convolution does, but we haven't yet covered how you chain multiples of these together. We will get back to this in lesson 4 when we use color images. At this point, it's enough if you understand the kind of operation a convolutional filter performsoutput
tf.keras.layers.Dense— A 128-neuron, followed by 10-node softmax layer. Each node represents a class of clothing. As in the previous layer, the final layer takes input from the 128 nodes in the layer before it, and outputs a value in the range[0, 1], representing the probability that the image belongs to that class. The sum of all 10 node values is 1.
查看构建的神经网络信息
model.summary()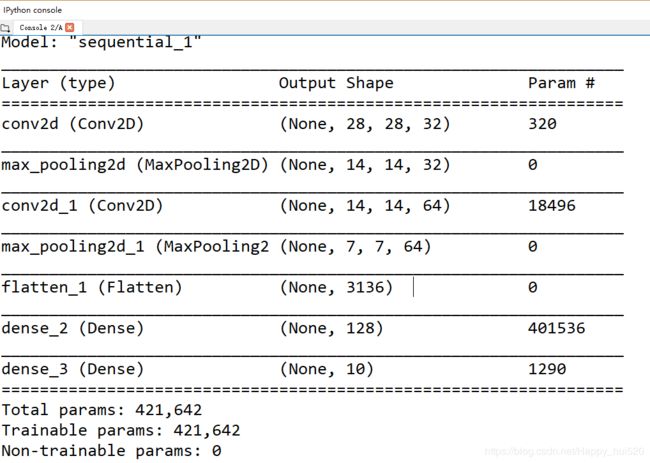
编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
优化器选用Adam(adaptive momentum),是目前很好的训练算法,想了解的话可以看这篇博客https://blog.csdn.net/leadai/article/details/79178787
损失函数采用 稀疏交叉熵损失函数(sparse_categorical_crossentropy),它和categorical_crossentropy的区别如下:
- If your targets are one-hot encoded, use
categorical_crossentropy.
- Examples of one-hot encodings:
[1,0,0][0,1,0][0,0,1]- But if your targets are integers, use
sparse_categorical_crossentropy.
- Examples of integer encodings (for the sake of completion):
123
metrics 是度量方法,就是你希望如何评估模型的性能(在训练的时候会动态显示相关信息)。
训练模型
Train the model
First, we define the iteration behavior for the train dataset:
- Repeat forever by specifying
dataset.repeat()(theepochsparameter described below limits how long we perform training).- The
dataset.shuffle(60000)randomizes the order so our model cannot learn anything from the order of the examples.- And
dataset.batch(32)tellsmodel.fitto use batches of 32 images and labels when updating the model variables.Training is performed by calling the
model.fitmethod:
- Feed the training data to the model using
train_dataset.- The model learns to associate images and labels.
- The
epochs=5parameter limits training to 5 full iterations of the training dataset, so a total of 5 * 60000 = 300000 examples.(Don't worry about
steps_per_epoch, the requirement to have this flag will soon be removed.)
BATCH_SIZE = 32
train_dataset = train_dataset.repeat().shuffle(num_train_examples).batch(BATCH_SIZE)
test_dataset = test_dataset.batch(BATCH_SIZE)
model.fit(train_dataset, epochs=5, steps_per_epoch=math.ceil(num_train_examples/BATCH_SIZE))
部分训练结果如下:
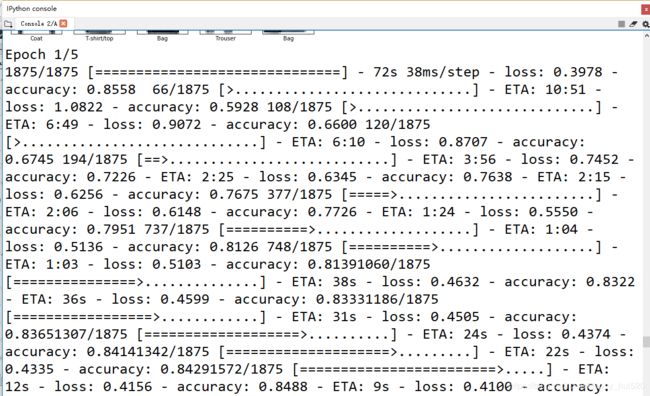
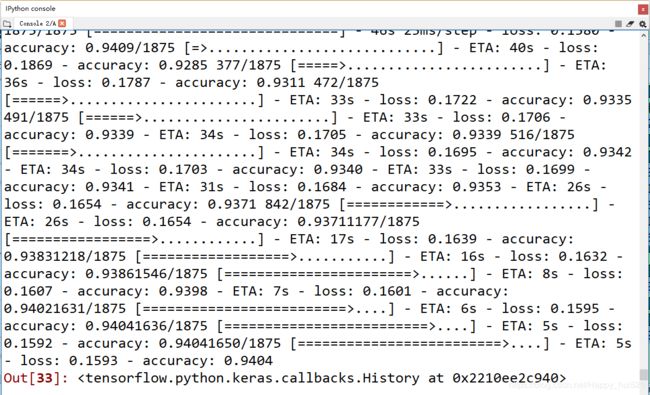
我笔记本电脑用的是酷睿i5-6200U和GeForce 930M(很垃圾...),差不多40多秒跑完一个迭代期(epoch)。可以看到准确度上升到了94%
模型评估
test_loss, test_accuracy = model.evaluate(test_dataset, steps=math.ceil(num_test_examples/32))
print('Accuracy on test dataset:', test_accuracy)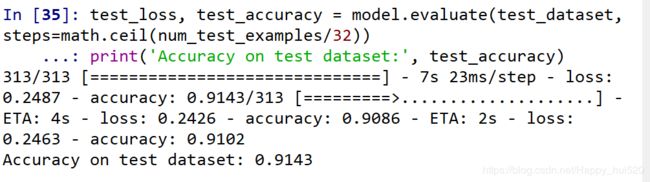
相比上一篇的简单神经网络,测试集准确度达到了91.43%,上升了4%,可以看出来卷积神经更适合做图像处理,而我们只是简单的训练了5个迭代期,还没有对卷积神经网络进行优化,优化后的准确度会更高。
想了解卷积神经网络的原理可以看Michael Nielsen 的这篇文章:http://neuralnetworksanddeeplearning.com/chap6.html
他的这本书写的通俗易懂,深入浅出,被TensorFlow官方推荐为神经网络的入门书籍,强烈推荐认真读一遍!