Inductive Representation Learning on Large Graphs阅读笔记
1 摘要
在大图中,低维的节点表示在很多预测任务中都很有用,比如内容推荐和确定蛋白质的功能。但是,在训练嵌入时,现有的方法需要所有的节点都参与(也即现有的方法都是直推式的),不能很好地繁华到不可见的节点上。本文提出GraphSAGE,利用节点的特征信息(如文本属性)来有效地为不可见的节点生成嵌入。不是直接为每个节点训练唯一的嵌入,而是学习一个函数通过采样和聚合节点的邻居特征来产生节点的特征。
简介
节点嵌入方法的基本思想是利用降维技术从节点的邻居的高维信息中提取出一个稠密向量。这些节点嵌入可以作为下游任务的输入。以前的工作关注于嵌入单个固定的图中的节点,而很多实际应用需要很快地为不可见的节点甚至完全新的图生成嵌入。这种推断式的能力对于演化图或者不断遇到不可见节点的应用来说非常重要。推断式生成节点嵌入的方法还能促进跨图的泛化,比如,我们可以训练一个典型的有机体的PPI交互网络嵌入生成器,然后利用训练好的模型为新的有机体中的数据产生节点嵌入。
推断式的节点嵌入问题比直推式的要困难,因为泛化到不可见的节点时需要将新观察到的子图与算法已经优化的节点嵌入进行‘对齐’,推断式的框架必须能识别节点邻居的结构特征。
提出的方法:提出了推断式嵌入的一般框架GraphSAGE.不同于基于矩阵分解的方法,此方法利用节点特征(如文本属性,节点配置信息,节点的度)来学习一个嵌入方程以得出不可见节点的嵌入。通过将节点特征融入到学习算法中,我们可以同时学习节点邻居的拓扑结构和节点特征的分布。尽管本方法主要关注于特征丰富的图,但由于会利用节点的度等结构特征,所以本算法也适用于没有节点特征的图。
本算法不是直接为每个节点训练一个特定的嵌入,而是训练一组聚合函数从节点的局部邻居中聚合特征信息。如图1所示

每个聚合函数聚合来自于不同跳或者不同深度的邻居的信息。在测试或推理的时候,训练好的系统利用学习到的聚合函数为完全不可见的节点生成嵌入。与现有的生成节点嵌入的方法一样,本文也设计了一个无监督的损失函数,允许GraphSAGE在没有特殊任务监督的情况下也可以训练。当然在监督的情况下也可以训练。
本方法的主要思想是学习如何聚合节点的局部邻居的特征信息,下面首先讲GraphSAGE的前向传播算法,然后介绍如何用随机梯度下降来更新参数。
前向传播:

假设有K个聚合函数(每个函数从节点邻居中聚合信息)和K个权重矩阵(用于在不用层中传递信息),算法1的直观做法是:在每次迭代中,节点聚合其邻居信息,随着迭代的进行,节点逐渐地获得越来越多的信息。算法的输入是图和节点的特征。k表示外层循环的步数(或者搜索的深度),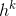 表示第k步中节点的表示,首先每个节点
表示第k步中节点的表示,首先每个节点 将直接邻居的信息
将直接邻居的信息![]() 聚合为一个向量
聚合为一个向量
![]() ,注意这一聚合依赖于前一迭代步骤产生的表示。聚合完以后,GraphSAGE连接当前节点的当前表示
,注意这一聚合依赖于前一迭代步骤产生的表示。聚合完以后,GraphSAGE连接当前节点的当前表示![]() 和其聚合表示
和其聚合表示![]() ,这一连接会经过一个全连接层和非线性激活层,最后进入下一训练步骤。经过K步循环后得到的节点表示记做
,这一连接会经过一个全连接层和非线性激活层,最后进入下一训练步骤。经过K步循环后得到的节点表示记做![]() 。邻居聚合可以由不同的架构:
。邻居聚合可以由不同的架构:
1)均值聚合:中心实体与其所有邻居求元素级的均值
![]()
2)LSTM聚合:与均值聚合比,LSTM聚合的表达能力更强,但它要求输入是个序列,所以将节点的邻居生成一个随机序列后再使用LSTM
3)池化聚合:每个邻居的向量输入到一个全连接网络,经过一个非线性激活后,再进行元素级的最大池化(当然最大池化也可换成平均池化,不过效果没有差别),运用池化以后,模型能有效地捕获邻居集合的不同方面。
![]()
如何在minibatch的前提下进行训练:伪代码如下所示:

首先采样计算中所需要的节点集合,2-7行表示采样过程(这个很有趣,倒着来取邻居)。 集合![]() 中包含计算
中包含计算![]() 中的节点的表示时所需要的节点。9-15行表示聚合过程,注意12-13行中,
中的节点的表示时所需要的节点。9-15行表示聚合过程,注意12-13行中,![]() 中任何节点在第k轮迭代的表示都能计算,因为它以及它的邻居在第k-1轮的表示都已经在上一轮的循环中计算出来。这一算法因此不用计算不在当前minibatch及其邻居中的节点的表示。
中任何节点在第k轮迭代的表示都能计算,因为它以及它的邻居在第k-1轮的表示都已经在上一轮的循环中计算出来。这一算法因此不用计算不在当前minibatch及其邻居中的节点的表示。
邻居的定义:
在本工作中,随机采样固定数量的邻居,而不是使用所有的邻居集合。在不同的迭代中猜哪个不同的邻居。
参数优化:
为了在无监督的情况下学习到有用的表示,本文利用基于图的损失函数,它期望离得近的节点有相似的表示而离得远的节点有不同的表示:
![]()
其中v 是在一个随机游走路径中与u同事出现的节点,![]() 是负采样分布。这里与以前的嵌入方法不同的是节点的表示是由其局部邻居的表示生成的,而不是通过查表的方式为每个节点生成一个表示。
是负采样分布。这里与以前的嵌入方法不同的是节点的表示是由其局部邻居的表示生成的,而不是通过查表的方式为每个节点生成一个表示。
疑问:
一直不太明白除了采样邻居与GCN不同以外,还有哪里不同于GCN。算法1的外层循环其实不就相当于GCN中的层数吗,为什么这个效果就能比GCN好?希望看到的大侠能指点