大数据实训-大二下期
1、数据采集
1.1、创建scrapy爬虫项目
scrapy startproject qcwy_spider
1.2、创建爬虫文件
scrapy genspider job51 51job.com
1.3、编写items.py文件
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class QcwySpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 职位名称
name = scrapy.Field()
# 薪资水平
salary = scrapy.Field()
# 招聘单位
unit = scrapy.Field()
# 工作地点
address = scrapy.Field()
# 工作经验
experience = scrapy.Field()
# 学历要求
education = scrapy.Field()
# 工作内容(岗位职责)
content = scrapy.Field()
# 任职要求(技能要求)
ask = scrapy.Field()
# contents = scrapy.Field()
put_date = scrapy.Field()
class ChinahrSpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 职位名称
name = scrapy.Field()
# 薪资水平
salary = scrapy.Field()
# 招聘单位
unit = scrapy.Field()
# 工作地点
address = scrapy.Field()
# 工作经验
experience = scrapy.Field()
# 学历要求
education = scrapy.Field()
# 工作内容(岗位职责)
content = scrapy.Field()
# 任职要求(技能要求)
ask = scrapy.Field()
# contents = scrapy.Field()
put_date = scrapy.Field()
1.4、编写pipelines.py文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from pymongo import MongoClient
import csv
import pyhdfs
import os
'''管道链接到mongodb'''
class QcwySpiderPipeline:
'''启动爬虫调用'''
def open_spider(self,spider):
# self.client = MongoClient('localhost', 27017)
# self.db = self.client.job1
# # self.db = self.client.chinahr1
# self.collection = self.db.job11
# # self.collection = self.db.chinahr11
store_file = os.path.dirname(__file__) + '/spiders/jobdata.csv'
self.file = open(store_file, 'a+', encoding="utf-8", newline='')
# csv写法
self.writer = csv.writer(self.file, dialect="excel")
'''关闭爬虫调用'''
def close_spider(self,spider):
#self.client.close()
self.file.close()
'''把item以字典的形式插入数据库'''
def process_item(self, item, spider):
# self.collection.insert_one(dict(item))
if item['name']:
self.writer.writerow([item['name'], item['salary'], item['unit'], item['address'],item['experience'],item['education'],item['put_date']])
return item
1.5、编写settings.py文件
给scrapy框架配置参数
重要配置
ROBOTSTXT_OBEY = False
COOKIES_ENABLED = False
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
ITEM_PIPELINES = {
'qcwy_spider.pipelines.QcwySpiderPipeline': 300,
}
#LOG_LEVEL = 'WARN' #设置日志等级
1.6、编写爬虫文件
# -*- coding: utf-8 -*-
import scrapy
import re
import urllib.request
from ..items import QcwySpiderItem
class Job51Spider(scrapy.Spider):
# 爬虫名
name = 'job51'
# 允许的域名
allowed_domains = ['51job.com']
job_name = urllib.request.quote("数据分析") #数据分析、大数据开发工程师、数据采集
start_urls = ['https://search.51job.com/list/000000,000000,0000,00,9,99,'+job_name+',2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=']
'''用来实现翻页'''
def parse(self, response):
#print(response.url)
last_page = re.findall(r"\d+",str(response.xpath('//*[@id="resultList"]/div[55]/div/div/div/span[1]/text()').extract_first()))[0]
#print(last_page)
for i in range(1,int(last_page)+1):
next_url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,'+self.job_name+',2,'+str(i)+'.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
#print(next_url)
if next_url:
yield scrapy.Request(next_url,dont_filter=True,callback=self.detailpage)
'''实现获取每一页的详情页的链接'''
def detailpage(self, response):
#print(response.url)
url_list = response.xpath('//*[@id="resultList"]/div')
for urls in url_list:
url = urls.xpath('p/span/a/@href').extract_first()
if url:
yield scrapy.Request(url,callback=self.detailparse)
'''详情页解析'''
def detailparse(self,response):
print(response.url)
item = QcwySpiderItem()
name = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/h1/text()').extract_first()
if name:
item['name'] = name.strip()
else:
item['name'] = ""
salary = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/strong/text()').extract_first()
if salary:
item['salary'] = salary.strip()
else:
item['salary'] = ""
unit = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[1]/a[1]/@title').extract_first()
if unit:
item['unit'] = unit.strip()
else:
item['unit'] = ""
address = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()').extract_first()
if address:
item['address'] = address.strip()
else:
item['address'] = ""
experience = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[2]').extract_first()
if experience:
if experience.find("经验") != -1:
item['experience'] = experience.strip()
else:
item['experience'] = "经验未知"
else:
item['experience'] = ""
education = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[3]').extract_first()
if education:
if re.findall(r'中专|中技|高中|大专|本科|硕士|博士',education):
item['education'] = education.strip()
else:
item['education'] = "学历未知"
else:
item['education'] = ""
put_date = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[5]').extract_first()
if put_date:
if put_date.find("发布") != -1:
item['put_date'] = put_date.strip().replace("发布","")
else:
item['put_date'] = "00-00"
else:
item['put_date'] = "00-00"
# 所有的内容div 包含工作内容、任职要求
contents = response.xpath('//div[@class="tBorderTop_box"]/div[@class="bmsg job_msg inbox"]/p').xpath(
'string(.)').extract()
item['content'] = ""
item['ask'] = ""
# 判断是否有任职要求的flag
flag = True
for text in contents:
if text.find("任职资格") != -1 or text.find("岗位条件") != -1 or text.find("任职要求") != -1 or text.find(
"技能要求") != -1 or text.find("岗位要求") != -1:
flag = False
if flag:
item['content'] += text
if not flag:
item['ask'] += text
if item['content']:
item['content'].strip()
if item['ask']:
item['ask'].strip()
print(item['name'])
return item
这里我写了两个网站的爬虫程序
另一个用的是CrawlSpider爬虫爬取中华英才网的校园子块
代码如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule, Request
from scrapy_redis.spiders import RedisCrawlSpider
from ..items import ChinahrSpiderItem
class ChinahrSpider(CrawlSpider):
# 爬虫名
name = 'chinahr'
#允许的域名
allowed_domains = ['campus.chinahr.com']
#过滤的域名
deny_domains = ['applyjob.chinahr.com']
# start_urls = ['https://campus.chinahr.com/qz/P1']
start_urls = ['http://campus.chinahr.com/qz/?job_type=10&city=1&']
#redis_key = 'ChinahrSpider:start_url'
'''
在start_requests函数中设置cookies
'''
def start_requests(self):
cookies = 'als=0; 58tj_uuid=e1e9f864-5262-4f4c-9dda-cb7860344ce6; __utma=162484963.1960492527.1593238075.1593238075.1593238075.1; __utmz=162484963.1593238075.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); _ga=GA1.2.1960492527.1593238075; _gid=GA1.2.1625017600.1593340605; gr_user_id=e85ed439-4fc2-49d4-a05d-2597f19b1304; wmda_uuid=66d7dd3456494514b1b8e04c5e2557be; wmda_new_uuid=1; wmda_visited_projects=%3B1731779566337; serilID=72adad7106b87ac3860b08260e031f7c_86b5bf4969404759a695521b4e9964e9; regSessionId=2f33adb6f1ca43f185f39cc14fb9a9d2; gr_session_id_b64eaae9599f79bd=b1a1517a-fac1-47cf-86a8-7b785afd6870; wmda_session_id_1731779566337=1593390547857-4dbf6bf0-38f7-ad1e; channel=campus; init_refer=; new_uv=8; utm_source=; spm=; gr_session_id_b64eaae9599f79bd_b1a1517a-fac1-47cf-86a8-7b785afd6870=true; new_session=0; token=5ef9387e5ef938235f5a74050ee62a7depd22171; ljy-jobids=5ed7ad047a8d5f04aa2edd7a; _gat=1'
cookies = {i.split("=")[0]: i.split("=")[1] for i in cookies.split("; ")}
yield scrapy.Request(
self.start_urls[0],
cookies=cookies
)
'''
分析出:'http://campus.chinahr.com/qz/?job_type=10&city=1&'为第一个url
页数url:http://campus.chinahr.com/qz/P2/?job_type=10&city=1& http://campus.chinahr.com/qz/P3/?job_type=10&city=1& unique 去重
正则匹配所有的页数:/qz/P\d{0,3}/\?job_type=10&city=1& 默认追加网站
详情页url: http://campus.chinahr.com/job/5ef970495ad508035987099e unique 去重
正则匹配所有详情页:/job/.*
.*是任意一串字符的匹配
'''
rules = (
Rule(LinkExtractor(allow=('/qz/P\d{0,3}/\?job_type=10&city=1&',), unique=True)),
Rule(LinkExtractor(allow=('/job/.*',), unique=True), callback='parse_item'),
)
'''解析详情页面'''
def parse_item(self, response):
item = ChinahrSpiderItem()
print(response.url)
name = response.xpath("/html/body/div[3]/div/div/h1/text()").extract_first()
if name:
item['name'] = name.strip()
else:
item['name'] = ""
salary = response.xpath("/html/body/div[3]/div/div/strong/text()").extract_first()
if salary:
item['salary'] = salary.strip()
else:
item['salary'] = ""
unit = response.xpath("/html/body/div[3]/div/div/div[2]/text()[2]").extract_first()
if unit:
item['unit'] = unit.strip()
else:
item['unit'] = ""
address = response.xpath("/html/body/div[4]/div[2]/div/span[2]/text()").extract_first()
if address:
item['address'] = str(address).split(":")[1]
else:
item['address'] = ""
# contents所有的内容div 包含工作内容、任职要求
contents = response.xpath("/html/body/div[4]/div[2]/div/div[2]/p").xpath('string(.)').extract()
item['experience'] = ""
item['content'] = ""
item['ask'] = ""
# 判断是否有任职要求的flag
flag = True
#从contents中提取经验信息
for text in contents:
if text.find("经验") != -1:
item['experience'] = text.split("经验")[1].split(";")[0].strip(":")
break
#从contents中提取任职资格和要求的信息
for text in contents:
if text.find("任职资格") != -1 or text.find("岗位条件") != -1 or text.find("任职要求") != -1 or text.find("技能要求") != -1:
flag = False
if flag:
item['content'] += text
if not flag:
item['ask'] += text
yield item
1.7、运行爬虫
scrapy crawl job51
数据源:
链接:https://pan.baidu.com/s/1SY4akkMAWNwEIoQl9MJCvA 提取码:nzjk
2、数据存储
这里数据存储的思路是:
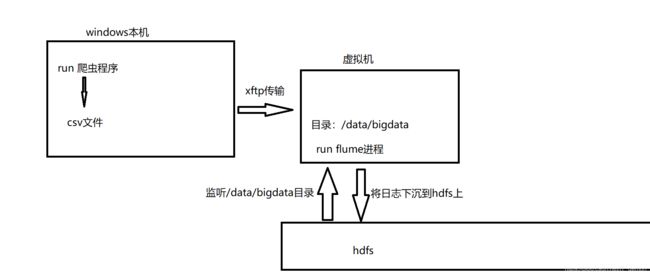
flume配置agent文件
# The configuration file needs to define the sources,
# the channels and the sinks.
# Sources, channels and sinks are defined per agent,
# in this case called 'agent'
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /data/bigdata/
a3.sources.r3.fileHeader = true
# #忽略所有以.tmp结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
a3.sources.r3.inputCharset = UTF-8
#
# # Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://192.168.76.101:9000/source/logs/%Y%m%d/%H
# #上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
# #是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
# #多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
# #重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
# #是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
# #积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 1000
# #设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
# #多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 180
# #设置每个文件的滚动大小
a3.sinks.k3.hdfs.rollSize = 134217700
# #文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0
# #最小冗余数
a3.sinks.k3.hdfs.minBlockReplicas = 1
#
#
# # Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 10000
a3.channels.c3.transactionCapacity = 1000
#
# # Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
运行flume 在flume根目录执行
bin/flume-ng agent -c conf -f conf/flume_hdfs5.conf -name a3 -Dflume.root.logger=DEBUG,console
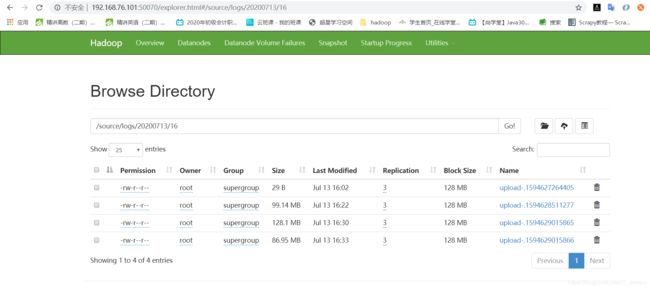
下沉到hdfs上的效果图
3、数据分析
hive的安装可以参考:https://blog.csdn.net/weixin_43861175/article/details/90372513
接着就是使用hive进行数据分析
# hive
#创建数据库并使用
hive> create database shixun;
OK
Time taken: 0.228 seconds
hive> use shixun;
OK
Time taken: 0.043 seconds
hive>create table zhaopin_data(name string,salary string,unit string,address string,experience string,education string,put_date string) row format delimited fields terminated by ',';
#导入hdfs中的数据
hive>load data inpath '/source/logs/20200714/22/upload-.1594737964393' into table zhaopin_data ;
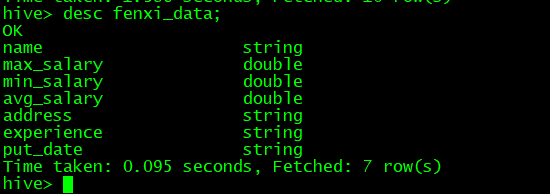
#创建一个表用于存放分析所需的字段
#分析所需字段:职位名、最高工资、最低工资、平均工资、地址、经验、发布时间
hive>create table fenxi_data(name string,max_salary double,min_salary double,avg_salary double,address string,experience string,put_date string);
#将薪资字段的数据分成最高、最低和平均工资 并插入到新建的fenxi_data表
hive>insert into fenxi_data
select name,case
when if (regexp_extract(split(salary,'-')[1],'(.*?)万/月',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)万/月',1) == '',false,true) then round(cast(regexp_extract(split(salary,'-')[1],'(.*?)万/月',1) as double),2)
when if (regexp_extract(split(salary,'-')[1],'(.*?)千/月',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)千/月',1) == '',false,true) then round(cast(regexp_extract(split(salary,'-')[1],'(.*?)千/月',1) as double) / 12,2)
when if (regexp_extract(split(salary,'-')[1],'(.*?)万/年',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)万/年',1) == '',false,true) then round(cast(regexp_extract(split(salary,'-')[1],'(.*?)万/年',1) as double) / 10,2)
else 0
end as max_salary,case
when if (regexp_extract(split(salary,'-')[1],'(.*?)万/月',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)万/月',1) == '',false,true) then round(cast(split(salary,'-')[0] as double),2)
when if (regexp_extract(split(salary,'-')[1],'(.*?)千/月',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)千/月',1) == '',false,true) then round(cast(split(salary,'-')[0] as double) / 12,2)
when if (regexp_extract(split(salary,'-')[1],'(.*?)万/年',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)万/年',1) == '',false,true) then round(cast(split(salary,'-')[0] as double) / 10,2)
else 0
end as min_salary,case
when if (regexp_extract(split(salary,'-')[1],'(.*?)万/月',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)万/月',1) == '',false,true) then round((round(cast(regexp_extract(split(salary,'-')[1],'(.*?)万/月',1) as double),2) + round(cast(split(salary,'-')[0] as double),2))/2,2)
when if (regexp_extract(split(salary,'-')[1],'(.*?)千/月',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)千/月',1) == '',false,true) then round((round(cast(regexp_extract(split(salary,'-')[1],'(.*?)千/月',1) as double) / 12,2) + round(cast(split(salary,'-')[0] as double) / 12,2) )/2,2)
when if (regexp_extract(split(salary,'-')[1],'(.*?)万/年',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)万/年',1) == '',false,true) then round((round(cast(regexp_extract(split(salary,'-')[1],'(.*?)万/年',1) as double) / 10,2) + round(cast(split(salary,'-')[0] as double) / 10,2))/2,2)
else 0
end as avg_salary,
address,
experience,
put_date
from zhaopin_data;
分析表数据结构如下:
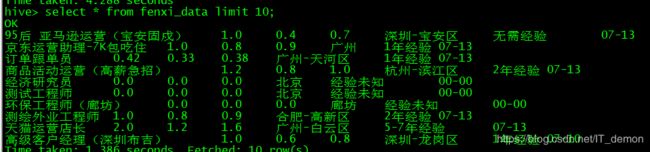
准备工作做完了 然后就是分析做题了
1)分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资,并作条形图将结果展示出来;
#创建表1 存放第一题的结果
hive>create table t1(name string,max_salary double,min_salary double,avg_salary double);
#查询 “数据分析”、“大数据开发工程师”、“数据采集” 的平均工资、最高工资、最低工资并插入
hive>insert into t1
select "数据分析",max(max_salary),min(min_salary),round(avg(avg_salary),2) from fenxi_data where min_salary != '0.0' and name like '%数据分析%' group by name like '%数据分析%' ;
hive>insert into t1
select "大数据开发工程师",max(max_salary),min(min_salary),round(avg(avg_salary),2) from fenxi_data where min_salary != '0.0' and name like '%大数据开发工程师%' group by name like '%大数据开发工程师%' ;
hive>insert into t1
select "数据采集",max(max_salary),min(min_salary),round(avg(avg_salary),2) from fenxi_data where min_salary != '0.0' and name like '%数据采集%' group by name like '%数据采集%' ;
hive>select * from t1;
分析结果:

(2)分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数,并做饼图将结果展示出来。
#创建表2 存放第二题的结果
hive>create table t2(address string,num int);
#查询 “数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数
hive>insert into t2
select "成都",sum(num) from (select address,count(* ) as num from fenxi_data where (name like '%数据分析%' or name like '%大数据开发工程师%' or name like '%数据采集%' or name like '%大数据%') and address like '%成都%' group by address )as a;
hive>insert into t2
select "北京",sum(num) from (select address,count(* ) as num from fenxi_data where (name like '%数据分析%' or name like '%大数据开发工程师%' or name like '%数据采集%' or name like '%大数据%') and address like '%北京%' group by address )as a;
hive>insert into t2
select "上海",sum(num) from (select address,count(* ) as num from fenxi_data where (name like '%数据分析%' or name like '%大数据开发工程师%' or name like '%数据采集%' or name like '%大数据%') and address like '%上海%' group by address )as a;
hive>insert into t2
select "广州",sum(num) from (select address,count(* ) as num from fenxi_data where (name like '%数据分析%' or name like '%大数据开发工程师%' or name like '%数据采集%' or name like '%大数据%') and address like '%广州%' group by address )as a;
hive>insert into t2
select "深圳",sum(num) from (select address,count(* ) as num from fenxi_data where (name like '%数据分析%' or name like '%大数据开发工程师%' or name like '%数据采集%' or name like '%大数据%') and address like '%深圳%' group by address )as a;
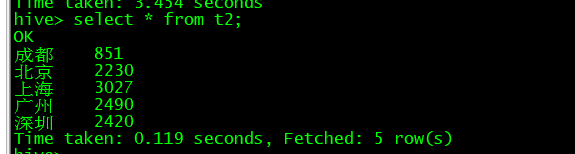
hive>select * from t2;
分析结果:
(3)分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资),并做出条形图展示出来;
#创建表3 存放第三题的结果
hive>create table t3(name string,max_salary double,min_salary double,avg_salary double);
#查询 “数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位1-3年工作经验的薪资水平
hive>insert into t3
select "大数据",max(max_salary),min(min_salary),round(avg(avg_salary),2) from fenxi_data where (name like '%数据分析%' or name like '%大数据开发工程师%' or name like '%数据采集%' or name like '%大数据%') and (experience like '%1年%' or experience like '%2年%' or experience like '%3年%') and min_salary != '0.0';
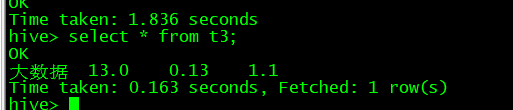
hive>select * from t3;
分析结果:
(4)分析大数据相关岗位几年需求的走向趋势,并做出折线图展示出来;
#创建表4 存放第四题的结果
hive>create table t4(put_date string,num int);
#查询大数据相关岗位几年需求的走向趋势
hive>insert into t4
select put_date,count(put_date) as num from fenxi_data where (name like '%数据分析%' or name like '%大数据开发工程师%' or name like '%数据采集%' or name like '%大数据%') and put_date != '00-00' and put_date != '本科' group by put_date;
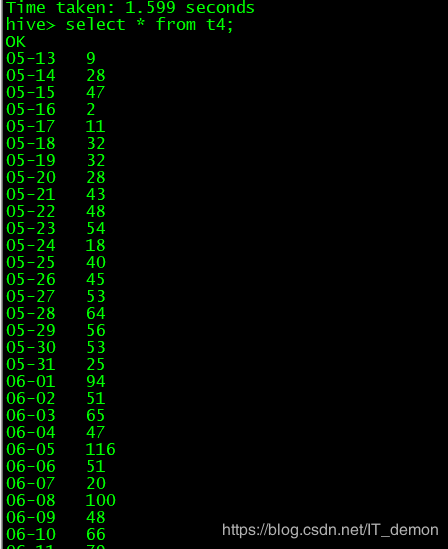
hive>select * from t4;
分析结果:
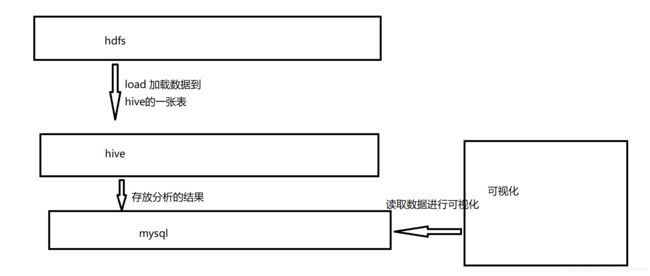
4、转化
用sqoop将分析结果从hive表中导入到mysql的表中
1、在mysql中创建存结果的表
mysql> create database IF NOT EXISTS shixun DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.11 sec)
mysql> use shixun;
Database changed
mysql> create table t1(name varchar(10),max_salary double,min_salary double,avg_salary double)charset utf8 collate utf8_general_ci;
mysql>create table t2(address varchar(2),num int)charset utf8 collate utf8_general_ci;
mysql> create table t3(name varchar(10),max_salary double,min_salary double,avg_salary double)charset utf8 collate utf8_general_ci;
mysql> create table t4(put_date varchar(5),num int)charset utf8 collate utf8_general_ci;
在sqoop根目录下输入信息导入数据到mysql
bin/sqoop export --connect "jdbc:mysql://192.168.76.101:3306/shixun?useUnicode=true&characterEncoding=utf-8" --username root --password 123456 --table t1 --export-dir /user/hive/warehouse/shixun.db/t1 --input-fields-terminated-by '\001'
bin/sqoop export --connect "jdbc:mysql://192.168.76.101:3306/shixun?useUnicode=true&characterEncoding=utf-8" --username root --password 123456 --table t2 --export-dir /user/hive/warehouse/shixun.db/t2 --input-fields-terminated-by '\001'
bin/sqoop export --connect "jdbc:mysql://192.168.76.101:3306/shixun?useUnicode=true&characterEncoding=utf-8" --username root --password 123456 --table t3 --export-dir /user/hive/warehouse/shixun.db/t3 --input-fields-terminated-by '\001'
bin/sqoop export --connect "jdbc:mysql://192.168.76.101:3306/shixun?useUnicode=true&characterEncoding=utf-8" --username root --password 123456 --table t4 --export-dir /user/hive/warehouse/shixun.db/t4 --input-fields-terminated-by '\001'
导出的数据如下:

5、可视化
可视化整体就是用pymysql读取mysql中的数据 然后用pyechart作图
话不多说,直接上代码
import pymysql
from pyecharts.charts import Bar, Pie, WordCloud,Line
from pyecharts import options as opts
'''
可视化类
'''
class Visual():
'''可视化构造方法:连接数据库'''
def __init__(self):
# self.job_name = job_name #职位名称
db_params = {
'host': '192.168.76.101',
'user': 'root',
'password': '123456',
'database': 'shixun'
}
self.conn = pymysql.connect(**db_params)
self.cursor = self.conn.cursor()
def __del__(self):
self.cursor.close()
self.conn.close()
'''第一题画图'''
def draw_1(self):
'''第一题的作图数据'''
name_list = []
max_salary_list = []
min_salary_list = []
average_salary_list = []
sql = "select * from t1"
self.cursor.execute(sql)
for i in self.cursor.fetchall():
name_list.append(i[0])
max_salary_list.append(i[1])
min_salary_list.append(i[2])
average_salary_list.append(i[3])
# 画柱状图
c = (
Bar(init_opts=opts.InitOpts(width="1600px", height="600px"), )
.add_xaxis(name_list)
.add_yaxis("最高薪资", max_salary_list)
.add_yaxis("最低薪资", min_salary_list)
.add_yaxis("平均薪资", average_salary_list)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=15)),
title_opts=opts.TitleOpts(title="薪资柱状图", subtitle="单位:万/月"),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_="inside")],
)
.render("薪资柱状图.html")
)
'''第二题画图'''
def draw_2(self):
'''第二题的作图数据'''
addres = []
work_count = []
sql = "select * from t2"
self.cursor.execute(sql)
for i in self.cursor.fetchall():
addres.append(i[0])
work_count.append(i[1])
# 画饼图
c = (
Pie(init_opts=opts.InitOpts(width="1600px", height="800px"), )
.add(
"数据分析",
[list(z) for z in zip(addres, work_count)],
radius=["30%", "40%"],
center=["25%", "35%"],
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),
)
.set_global_opts(title_opts=opts.TitleOpts(title="岗位数饼图"))
.render("岗位数饼图.html")
)
'''第三题画图'''
def draw_3(self):
'''第三题的做图数据'''
sql = "select * from t3"
self.cursor.execute(sql)
data = self.cursor.fetchall()[0]
min_salary = data[1]
max_salary = data[2]
average_salary = data[3]
'''{"$regex": "2年经验|3年经验|1年经验"}'''
c = (
Bar(init_opts=opts.InitOpts(width="1600px", height="600px"), )
.add_xaxis(["最高薪资", "最低薪资", "平均薪资"])
.add_yaxis("薪资", [min_salary,max_salary,average_salary])
# .add_yaxis("最低薪资", self.min_salary_list3)
# .add_yaxis("平均薪资", self.average_salary_list3)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=15)),
title_opts=opts.TitleOpts(title="大数据相关薪资柱状图", subtitle="单位:万/月"),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_="inside")],
)
.render("大数据相关薪资柱状图.html")
)
'''第四题画图'''
def draw_4(self):
'''第四题的作图数据'''
put_dates = []
date_count = []
sql = "select * from t4 order by put_date"
self.cursor.execute(sql)
for i in self.cursor.fetchall():
put_dates.append(i[0])
date_count.append(i[1])
c = (
Line()
.add_xaxis(xaxis_data=put_dates)
.add_yaxis(
"工作发布量",
y_axis=date_count,
linestyle_opts=opts.LineStyleOpts(width=2),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="大数据工作趋势"),
xaxis_opts=opts.AxisOpts(name="x"),
yaxis_opts=opts.AxisOpts(
type_="log",
name="y",
splitline_opts=opts.SplitLineOpts(is_show=True),
is_scale=True,
),
)
.render("大数据工作趋势.html")
)
if __name__ == '__main__':
# 数据分析 大数据开发工程师 数据采集
v = Visual()
v.draw_1()
v.draw_2()
v.draw_3()
v.draw_4()
可视化效果图:
1)
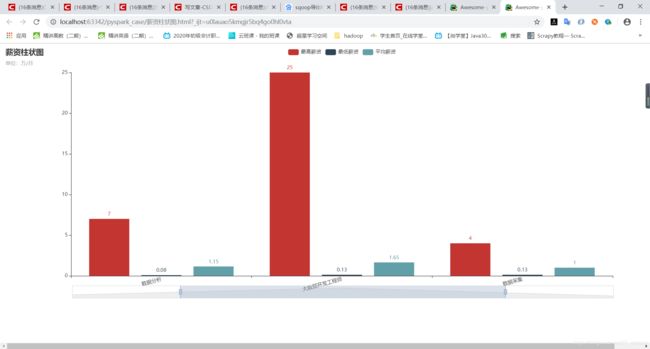
2)
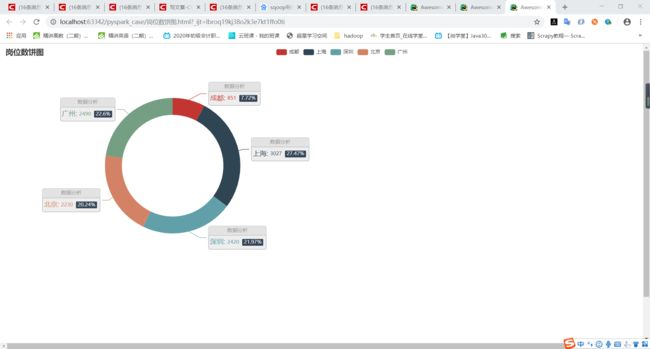
3)
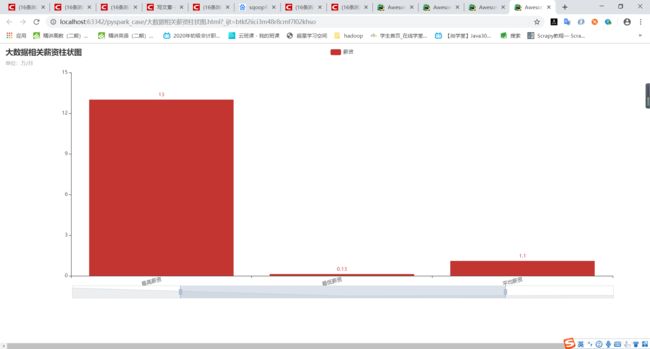
4)
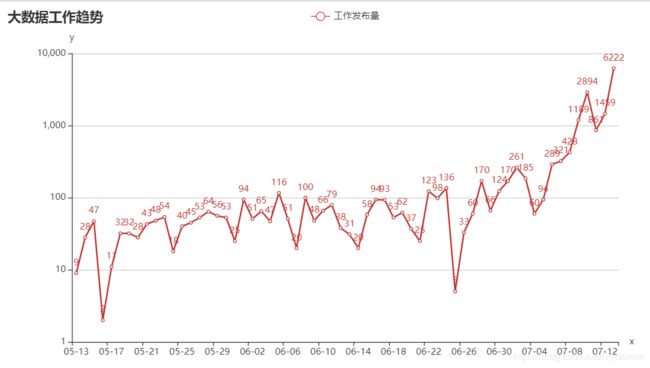
到此实训项目就完结了
实训总结:此次实训用到的知识点还是很全的;对scrapy、hadoop、hive、sqoop、flume、mysql等知识的巩固起到了很大的作用。看再多的书与视频都不及自己上手写代码。写代码的过程中会出现各种各样的错误,将错误信息复制粘贴到百度,可以看到许多和自己相同错误的博客