mysql-表连接详解
应用数据库首先应该创建表格:
1.创建表格注意事项
1.在实际的oltp系统中,为了保障性能,一般不用外键约束来验证数据有效性而是在应用层用代码实现外键约束;
2.在oltp数据库中,表格和字段应该尽量小,必要时将较大的字段进行垂直分割;
3.根据实际需求,适当的使用冗余数据以避免大型的表连接;
4.在oltp库中把冷热数据进行分离。
5.当表格数据量太大时,使用水平分割将表格分离。具体做法以后介绍。
为了方便,我使用了网络上的范例:
USE scoredb;
CREATE TABLE student
(
student_id SMALLINT UNSIGNED NOT NULL,
student_name VARCHAR(50) NOT NULL,
student_sex TINYINT(1) NOT NULL DEFAULT 0,
student_phone VARCHAR(50) DEFAULT NULL,
student_addr_id SMALLINT UNSIGNED NOT NULL,
PRIMARY KEY (student_id)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
CREATE TABLE address
(
addr_id SMALLINT UNSIGNED NOT NULL,
addr_info VARCHAR(100) NOT NULL,
PRIMARY KEY(addr_id)
) ENGINE=INNODB,CHARSET=utf8;
create TABLE department
(
depart_id SMALLINT UNSIGNED NOT NULL,
depart_name VARCHAR(100) NOT NULL,
PRIMARY key(depart_id)
) ENGINE=INNODB,CHARSET=utf8;
create TABLE course
(
course_id SMALLINT UNSIGNED NOT NULL,
course_name VARCHAR(100) NOT NULL,
teacher_id SMALLINT UNSIGNED NOT NULL,
PRIMARY key(course_id)
) ENGINE=INNODB,CHARSET=utf8;
create TABLE teacher
(
teacher_id SMALLINT UNSIGNED NOT NULL,
teacher_name VARCHAR(50) NOT NULL,
PRIMARY key(teacher_id)
) ENGINE=INNODB,CHARSET=utf8;
create TABLE score
(
score_id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
student_id SMALLINT UNSIGNED NOT NULL,
course_id SMALLINT UNSIGNED NOT NULL,
teacher_id SMALLINT UNSIGNED not NULL,
score_value SMALLINT UNSIGNED NOT NULL,
PRIMARY key(score_id)
) ENGINE=INNODB,CHARSET=utf8;
2.使用python连接mysql并构造数据,插入数据
使用python构造数据,并将数据插入数据库。
import pymysql as my
# 得到共有28个学生,5门功课。现在构造出表格。
rowid=list(range(1000,28*5+1000)) # 流水号
student_id=list(range(102,130)) # 确定学生编号
course_id=list(range(1,6)) # 确定课程编号
teacher_id=list(range(9003,9008)) # 确定老师的编号
score=[random.randint(60,96) for x in range(28*5)] # 为28*5个成绩随机选取成绩
cou_tea=list(zip(course_id,teacher_id))
aa=[(a,b) for a in student_id for b in cou_tea] # 按照笛卡尔积方式组合两个集合
res=list(zip(rowid,aa,score)) # 把集合堆叠起来
print (res)
# 元祖解包
res_table=[]
for i in res:
(a,(b,(c,d)),e)=i
res_table.append((a,b,c,d,e))
print (res_table)
teacher_name=['王梦妮','冯俊璋','齐雨','高晓楠','许梦薇','杨碧琦','何祝康','潘季香','薛惠民','周少宇','胡欢欢','代志凤','汪政','赵祥凯','闫加豪','胡应元','耿志豪','熊雨豪']
all_teacher_id=list(range(9003,9021))
to_teach=list(zip(all_teacher_id,teacher_name))
print (to_teach)
db= my.connect(host="******",user="****", \
password="***",db="scoredb",port=3315,charset='utf8') # 这里按照自己情况填写
print ('数据库连接成功。。。')
with db:
cursor = db.cursor()
# for i in res_table:
# sql="insert into score values{}".format(i)
# cursor.execute(sql)
# cursor.execute('commit')
for i in to_teach:
sql="insert into teacher values{}".format(i)
cursor.execute(sql)
cursor.execute('commit') # 如果数量多的话可以设定每100条提交一次。必须要设置一个变量flag计数
3.sql语句解析
一般sql中的select语句的语法顺序是按照下面从上至下,但是执行顺序是按照语句前面的数字顺序来执行。
mysql的嵌套子查询效率确实比较低,一般我们使用exist语句或者表连接来代替子查询。
(7) SELECT
(8) DISTINCT
(1) FROM
(3)
(2) ON
(4) WHERE
(5) GROUP BY
(6) HAVING
(9) ORDER BY
(10) LIMIT
首先写出sql执行的过程
第一步:首先对from子句中的前两个表执行一个笛卡尔乘积,此时生成虚拟表 vt1(选择相对小的表做基础表)
第二步:接下来便是应用on筛选器,on 中的逻辑表达式将应用到 vt1 中的各个行,筛选出满足on逻辑表达式的行,生成虚拟表 vt2
第三步:如果是outerjoin 那么这一步就将添加外部行,leftouter jion 就把左表在第二步中过滤的添加进来,如果是rightouter join 那么就将右表在第二步中过滤掉的行添加进来,这样生成虚拟表 vt3
第四步:如果 from 子句中的表数目多余两个表,那么就将vt3和第三个表连接从而计算笛卡尔乘积,生成虚拟表,该过程就是一个重复1-3的步骤,最终得到一个新的虚拟表 vt3。
第五步:应用where筛选器,对上一步生产的虚拟表引用where筛选器,生成虚拟表vt4,在这有个比较重要的细节不得不说一下,对于包含outer join子句的查询,就有一个让人感到困惑的问题,到底在on筛选器还是用where筛选器指定逻辑表达式呢?on和where的最大区别在于,如果在on应用逻辑表达式那么在第三步outerjoin中还可以把移除的行再次添加回来,而where的移除的最终的。举个简单的例子,有一个学生表(班级,姓名)和一个成绩表(姓名,成绩),我现在需要返回一个x班级的全体同学的成绩,但是这个班级有几个学生缺考,也就是说在成绩表中没有记录。为了得到我们预期的结果我们就需要在on子句指定学生和成绩表的关系(学生.姓名=成绩.姓名)那么我们是否发现在执行第二步的时候,对于没有参加考试的学生记录就不会出现在vt2中,因为他们被on的逻辑表达式过滤掉了,但是我们用left outer join就可以把左表(学生)中没有参加考试的学生找回来,因为我们想返回的是x班级的所有学生,如果在on中应用学生.班级='x'的话,left outer join会把x班级的所有学生记录找回,所以只能在where筛选器中应用学生.班级='x' 因为它的过滤是最终的。
第六步:group by 子句将中的唯一的值组合成为一组,得到虚拟表vt5。如果应用了group by,那么后面的所有步骤都只能得到的vt5的列或者是聚合函数(count、sum、avg等)。原因在于最终的结果集中只为每个组包含一行。这一点请牢记。
第七步:应用cube或者rollup选项,为vt5生成超组,生成vt6.
第八步:应用having筛选器,生成vt7。having筛选器是第一个也是为唯一一个应用到已分组数据的筛选器。
第九步:处理select子句。将vt7中的在select中出现的列筛选出来。生成vt8.
第十步:应用distinct子句,vt8中移除相同的行,生成vt9。事实上如果应用了group by子句那么distinct是多余的,原因同样在于,分组的时候是将列中唯一的值分成一组,同时只为每一组返回一行记录,那么所以的记录都将是不相同的。
第十一步:应用orderby子句。按照order_by_condition排序vt9,此时返回的一个游标,而不是虚拟表。sql是基于集合的理论的,集合不会预先对他的行排序,它只是成员的逻辑集合,成员的顺序是无关紧要的。对表进行排序的查询可以返回一个对象,这个对象包含特定的物理顺序的逻辑组织。这个对象就叫游标。正因为返回值是游标,那么使用order by 子句查询不能应用于表表达式。排序是很需要成本的,除非你必须要排序,否则最好不要指定order by,最后,在这一步中是第一个也是唯一一个可以使用select列表中别名的步骤。
第十二步:应用top选项。此时才返回结果给请求者即用户。
4.sql查询几处容易出错的地方:
1.当groupby和where并用的时候,是where->groupby->select这样的顺序。先用groupby划分了集合才可以用select。
2.使用groupby子句的时候,select子句中不能出现聚合建以外的列名;
3.groupby子句中不能使用select子句中定义的别名
4.当存在HAVING和where共存的时候。有时候条件也更适合写在where子句中。
而聚合函数的处理适合放在having子句中。Where指定行对应条件;having指定组对应条件;
5.关联子查询的组合条件必须是写在子查询中。通常我们也常使用关联子查询作为exist的参数。
5.表连接(物理)
任何复杂查询基本都可以用表连接的形式来表示。如下图所示,表连接可以使用七种方式来处理集合关系。我们可以灵活的使用表连接来自由的处理集合。表连接的物理形式有如下三种方式:
Nested loop join
对于被连接的数据子集较小的情况,嵌套循环连接是个较好的选择。在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(<10000),需要注意的是:JOIN的顺序很重要,要把返回子集较小表的作为外表,而且在内表的连接字段上一定要有索引。
cost = outer access cost + (inner access cost * outer cardinality)
hash join
散列连接是做大数据集连接时的常用方式,优化器使用两个表中较小的表利用连接键在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行。这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。但是在表很大的情况下并不能完全放入内存,这时优化器会将它分割成若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要有较大的临时段从而尽量提高I/O 的性能。
cost = (outer access cost * # of hash partitions) + inner access cost
Sort merge join
通常情况下散列连接的效果都比排序合并连接要好,然而如果行源已经被排过序,在执行排序合并连接时不需要再排序了,这时排序合并连接的性能会优于散列连接。Sort Merge join 用在没有索引,并且数据已经排序的情况。
6.表连接(逻辑)
MySQL的多表连接查询只支持Nest Loop join,不支持hash join和sort merge join。而一般表连接的逻辑方式分为下面八种,mysql数据库也是如此: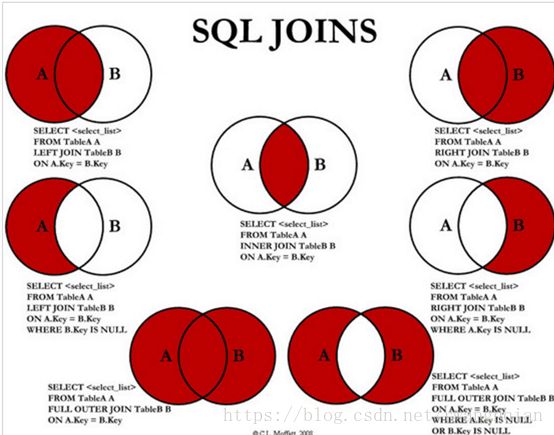
sql语句的本质就是集合的处理。大致就可以分为合集,并集,差集和异或集(上图中最后一种情况)。只不过不同的数据库系统实现的方法有很大的差异。例如mysql中没有EXCEPT和INTERSECT的操作,也没有full outer join的操作。但oracle则都可以实现!不过在mysql中这并不是没有办法解决,万变不离其宗,实际上我们可以换一种方式来实现。
1.左外连接:left (outer)join 表示以此关键词左边表格A的列key为基准,以此基准将关键词右边表格B对应的key列值找出来一一对应。很显然这里的数据含有A的key列值全部数据
我用上面的表格中的范例:这里显示的是teacher表中所有老师的信息。得到表格行数等于teacher表中teacher_id行数
SELECT * FROM teacher A LEFT JOIN score B ON A.teacher_id=B.teacher_id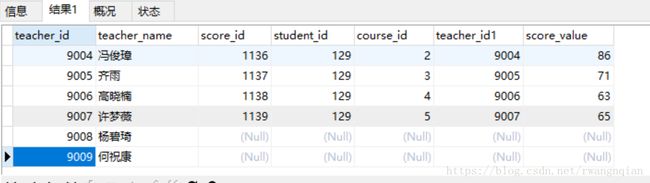
这里可以说完全是以A的集合。
2.左外连接这里还有另外一种情况:得到结果key列中只有是A表格key值剔除了B表格key值还剩下的值。
仍然用上面表格的范例:显示的是教师表teacher中没有出现在成绩表score中的老师。
SELECT * FROM teacher A LEFT JOIN score B ON A.teacher_id=B.teacher_id WHERE B.teacher_id IS NULL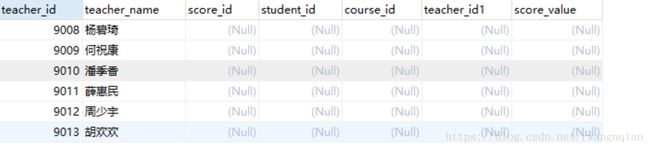
这里可以说是A-B的差集
3.右外连接:right(outer)join 表示以此关键词右边表格B的列key为基准,以此基准将关键词左边表格A对应的列key值找出来一一对应。很显然这里含有B的key列值全部数据
以上面的表格为例:这里显示的是成绩表score中所有老师的关联信息。得到表格行数等于score表中teacher_id行数
SELECT * FROM teacher A RIGHT JOIN score B ON A.teacher_id=B.teacher_id
这里可以说完全是以B的集合。
4.右外连接这里还有另外一种情况:得到结果key列中只有是B表格key值剔除了A表格key值还剩下的值。
仍然用上面的表格:这里显示的是score表格中没有出现在teacher表格中的条目。
SELECT * FROM teacher A RIGHT JOIN score B ON A.teacher_id=B.teacher_id WHERE A.teacher_id IS NULL
这里可以说是B-A的差集
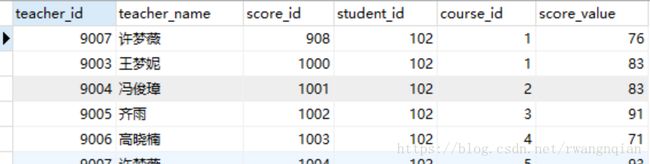
5.内连接:表格A中key和表格B中key都有的值。
这里还是用上面的表格示例:这是使用的最多的关联方式,显示是存在在teacher表格中也存在在score表格中的教师id
SELECT * FROM teacher A INNER JOIN score B ON A.teacher_id=B.teacher_id
这里也可以说是A和B的并集
5.1等值连接:在连接条件中使用等于号(=)运算符比较被连接列的列值,其查询结 果中列出被连接表中的所有列,包括其中的重复列。
举例:多个表格的等值连接:
SELECT * FROM teacher A
INNER JOIN score B
USING (teacher_id)
INNER JOIN student C
USING (student_id)
5.2不等连接:在连接条件使用除等于运算符以外的其它比较运算符比较被连接的列的列值。这些运算符包括>、>=、<=、<、!>、!<和<>。
5.3自然连接:在连接条件中使用等于(=)运算符比较被连接列的列值,但它使用选择列表指出查询结果集合中所包括的列,并删除连接表中的重复列。
SELECT * from teacher A NATURAL JOIN score B
看下面的表格只有一列teacher_id
6.全外连接:以两个表格key键做连接,表格行数等于A,B的所有key值。
同样以上面的表格做范例:这里就相当于一个并集。得到的teacher_id既有teacher表中的条目也有score表中的条目
SELECT * FROM teacher A INNER JOIN score B ON A.teacher_id=B.teacher_id
UNION ALL
SELECT * FROM teacher A LEFT JOIN score B ON A.teacher_id=B.teacher_id WHERE B.teacher_id IS NULL
UNION ALL
SELECT * FROM teacher A RIGHT JOIN score B ON A.teacher_id=B.teacher_id WHERE A.teacher_id IS NULL;
这里也可以说这是A和B的并集
7.异或集:是内连接的取反。
只需要理解下面图形中的集合概念就知道如何实现。因为mysql中不存在full outer join这个连接方式的。其实就是上面第2个集合加上第4个集合:
SELECT * FROM teacher A LEFT JOIN score B ON A.teacher_id=B.teacher_id WHERE B.teacher_id IS NULL
UNION ALL
SELECT * FROM teacher A RIGHT JOIN score B ON A.teacher_id=B.teacher_id WHERE A.teacher_id IS NULL;
8.笛卡尔积:两个表格相乘的结果。最后结果行数等于两个表格行数相乘。其实这个很少用到是数据库内部的实现。
SELECT * FROM teacher A CROSS JOIN score B
SELECT * FROM teacher A , score B
上面这两种写法是等价的。
7.容易混淆的问题:
7.1 使用on连接还是where筛选
当表格使用on或者using()来进行连接的时候,必须使用一样的列名。
当表格使用笛卡尔连接而使用where来过滤的时候就不存在这个问题。
create table test(teacher_id SMALLINT UNSIGNED ,b VARCHAR(10) )
INSERT INTO test VALUES (9003,'曾仕强'),(9004,'褚时健')
create table test_b(teacher_id int ,b VARCHAR(10) )
INSERT INTO test_b VALUES (9003,'曾仕强'),(9004,'褚时健')
create table test_c(t_id int ,b VARCHAR(10) )
INSERT INTO test_c VALUES (9003,'曾仕强'),(9004,'褚时健')
select a.* from score a INNER JOIN test d on a.teacher_id=d.teacher_id
select a.* from score a INNER JOIN test_b d USING(teacher_id)
select a.* from score a INNER JOIN test_c d on a.teacher_id=c.tid
/*上面这个查询是错误的,遇到这种情况只能使用下面这个查询。*/
select a.* from score a INNER JOIN test_c d where a.teacher_id=d.t_id
以下是一些基础的sql概念解释:
DML(data manipulation language)是数据操纵语言:它们是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的数据进行操作的语言。
DDL(data definition language)是数据定义语言:DDL比DML要多,主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用。
DCL(DataControlLanguage)是数据库控制语言:是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)语句。
标量子查询:返回单一值的子查询;