这星期被线上JVM内存占用不断增大的问题所困扰,自己提出了一些假设,然后去实施验证都一一失败了,有一些经验和教训在这里分享下.
之所以是尴尬,是最后因为修复了另一个看似不相关的问题导致内存不再上升,但这之间的关系还未明了,还需要继续追踪.
这里讲述一下这次排查的过程.
直接内存的错误判断
服务器的JVM配置为Xmx3g,使用G1,没有设置Xms考虑自然收缩和fgc之后的空间回拢.
没有发生过fgc,且堆内存的增长正常,排除掉堆内存的问题.
使用NMT查看各个区域的内存正常,committed内存不足4G,但实际情况内存占用不断增大,甚至出现了OOM killer杀掉java进程.
Total: reserved=5037MB, committed=3926MB
- Java Heap (reserved=3072MB, committed=3072MB)
(mmap: reserved=3072MB, committed=3072MB)
- Class (reserved=1196MB, committed=192MB)
(classes #29793)
(malloc=6MB #86203)
(mmap: reserved=1190MB, committed=186MB)
- Thread (reserved=186MB, committed=186MB)
(thread #184)
(stack: reserved=184MB, committed=184MB)
(malloc=1MB #922)
(arena=1MB #366)
- Code (reserved=273MB, committed=171MB)
(malloc=29MB #39947)
(mmap: reserved=244MB, committed=142MB)
- GC (reserved=176MB, committed=176MB)
(malloc=30MB #114115)
(mmap: reserved=146MB, committed=146MB)
- Compiler (reserved=1MB, committed=1MB)
- Internal (reserved=88MB, committed=88MB)
(malloc=88MB #83467)
- Symbol (reserved=31MB, committed=31MB)
(malloc=27MB #312661)
(arena=4MB #1)
- Native Memory Tracking (reserved=10MB, committed=10MB)
(tracking overhead=10MB)
- Unknown (reserved=6MB, committed=0MB)
(mmap: reserved=6MB, committed=0MB)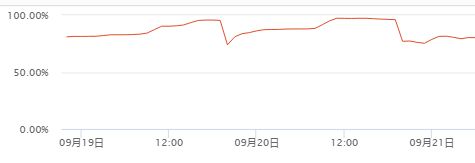
内存增长情况(中间下降是进行fgc或重启服务)
最开始考虑是直接内存的问题,观察GC行为发现没有发生过一次fgc,想当然觉得应该是直接内存无法回收,并且在手动执行gc之后内存占用的确是下降的.
于是调整了一波JVM参数,将堆大小设置为2500M,并配置MaxDirectMemory用来触发fgc.
但最后发现内存依旧增长,且还是没有fgc.
再观察了下heap(jmap -heap)的情况,发现手工触发fgc后,heap释放的大小和内存下降几乎一致.
在使用JMX查看了direct pool(java.nio.BufferPool)后惊奇地发现..直接内存并没有多少使用(我们底层用了netty,下意识认为出了问题):
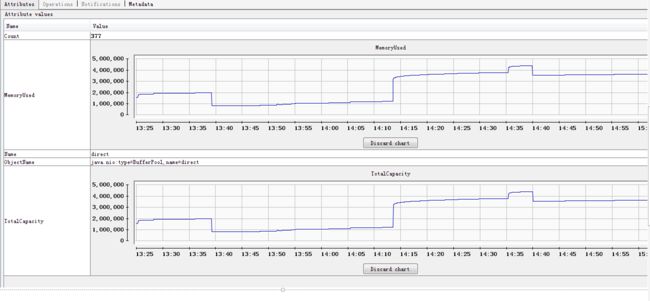
图中所示最大只用了4M左右.
最后设置了Xms之后发现fgc已经没有作用,内存的使用量不会再下降,排除掉了这个因素.
这个错误的判断最主要的原因还是先入为主,没有收集支撑的直接证据.
stack中的间隙
接下去只能使用pmap(pamp -X pid)看下具体的内存信息.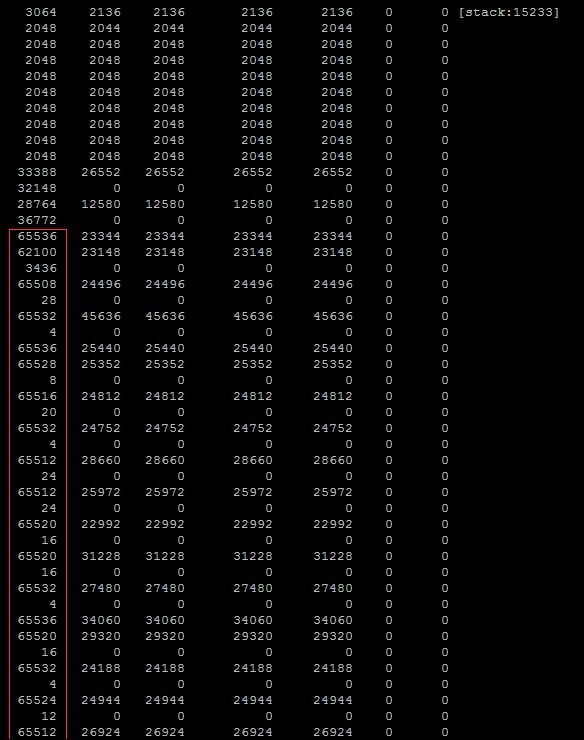
发现了一些有趣的东西,大量的64M块.
直觉告诉我,快找出问题了.
搜索了下发现类似的问题:

解决方法也很直接换一个分配内存的库.
可选的也只有tcmalloc和jemalloc.
选择了前者,配置之后效果出众.
已经没有上图中那么多的64M块了.
并且启动后的内存使用是掉了下来,但是好景不长.
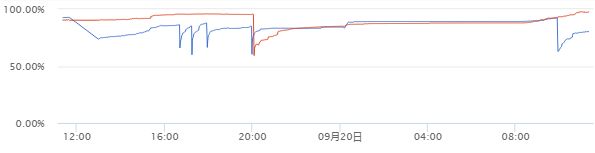
(蓝线是使用了tcmalloc,红线是对比方)
刚开始的确蓝线内存使用好一点(红线在20:00的时候重启 内存降低了).
但随后还是增长了,比较迷的一点是在8点后内存陡降(但JVM没有重启,PID也没有变化),恢复到了最初的水平.
看来问题不在这里.
看似没有关联的问题
周常部署的时候出现一个问题导致CPU飙升,跟了下发现一个处理图片的接口被频繁调用并且在处理较大尺寸的图片,看似和这个堆外内存引起的问题没有关联就没怎么在意.
第二天同事修复了这个问题,迁移走了这个接口到另一个服务.
tcmalloc的heap profiling无法使用,一开启libunwind就segment fault退出,换成jemalloc后开启.
还在想是不是常见的那个zip溢出的问题,但是搜索了代码库没有发现忘记关闭的情况,等着看下增长和dump验证下.
观察了一会儿,突然发现内存不再增长了.
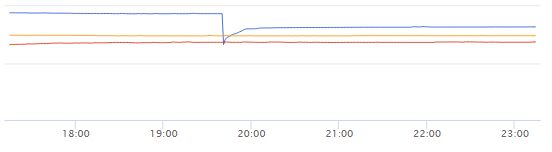
(蓝线是之前一直留着的机器,中间降低是进行了重启)
非常平稳地度过了一天.
那坨profiling也失去了意义... ...
这就感觉非常尴尬了...
继续追踪
更尴尬的是另一个服务炸了... ...
继续跟进,先把jemalloc配置过去,等下一次增长看下dump.
update 2018/09/25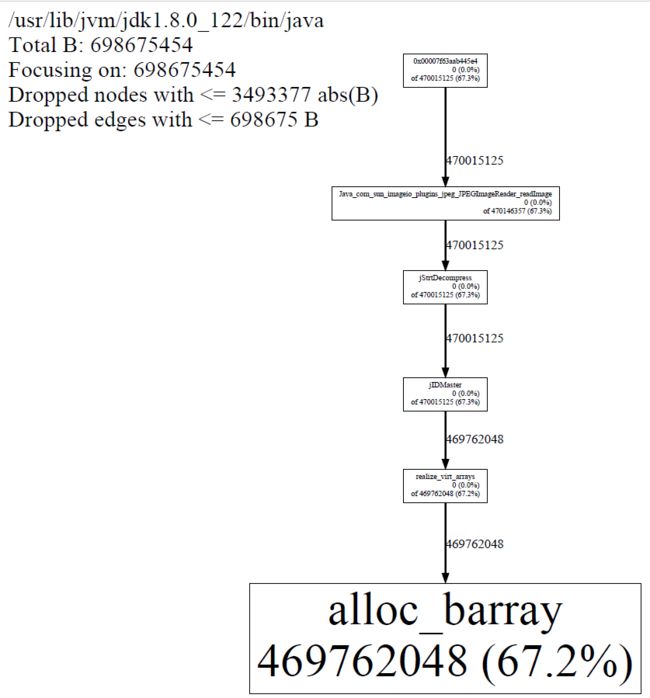
继续观察了一段时间... 发现在内存在突然增大的时候这个部分增加比较多
java2d相关,代码里确实有图片处理.
但放着不管(之前都重启了或者被OOM killer干掉了..)接下去会被回收掉...
update 2018/09/27
之后做了一个实验,读取图片(jpeg),的确是会申请很多native内存.
在爆栈提了个问题:
https://stackoverflow.com/questions/52519253/why-the-code-using-image-io-mallocs-so-much-memory
多线程同时读取内存会升高明显.
大体确定是业务原因,读取处理图片是同步进行,会导致堆外内存占用升高.
fix应该是用任务队列的方式去修改业务实现.
再看看之后会不会有问题.
随着时间的推移遇见了各种各样的问题.
这次排查除了对之前积累的知识的运用,更多像是一次对搜索引擎熟练度的提升 :( .
但过程还是很不错的,也看到了一些自己以前没有接触过的知识.
深深感受到自己知识的匮乏,就像深渊(??)一样,逐渐深入才会发现不一样的风景.
生活中还是要多(xie)些bug才会更精彩的啊... ...

参考资料:
http://lovestblog.cn/blog/2015/05/12/direct-buffer/
https://yq.aliyun.com/articles/227924
https://github.com/jeffgriffith/native-jvm-leaks
glibc issue原问题:
https://serverfault.com/questions/341579/what-consumes-memory-in-java-process?newreg=394e0ea40e55493d8149010909011719
关于NMT的internal 包含了直接内存 不包含DirectMemory:
https://stackoverflow.com/questions/47309859/what-is-contained-in-code-internal-sections-of-jcmd