MySQL Update inner join数据库去重,以及根据一张表的值更新另一张表
1 问题来源
这几天在项目中遇到一个问题:由于前期设计不合理,导致后期用户录入数据时,基础数据表中有重复多余数据。如下:
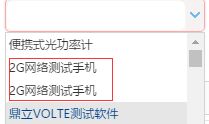
出现两个 2G网络测试手机 这样类似的基础数据,直接后果就是用户在使用这个基础数据时,明明选择的是同一类型的基础数据,但是数据库中的关联ID却不一致,这在后期做统计等功能的时候带来巨大的不必要的困难,并且随着时间的增长,这样的时间开销越来越大,系统维护难度也增大。
表结构如下:
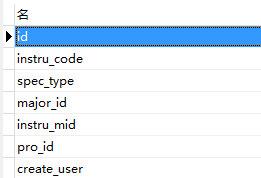
功能数据表:tb_instruments_info
基础数据表: tb_instrument_mapping_info
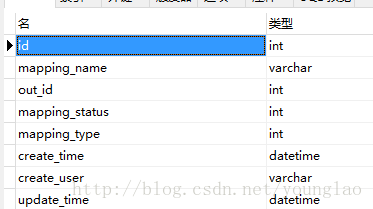
其中,功能数据表中的instru_mid,pro_id,major_id都关联基础数据表中的ID,上图中的 2G网络测试手机 为基础数据表中的mapping_name字段。
页面显示的mapping_name相同,但是ID却不同,从而功能表中相同名称的基础数据,但是instru_mid/pr_id/major_id却不同,所以在统计 tb_instruments_info 表中的数据的时候,会有不必要的麻烦。
解决这个问题,我想到的解决办法如下:
1. 修改代码,使得在添加基础数据的时候,如果有此项数据了之后,不能重复添加;
2. 清除基础数据表中还没有使用过的基础数据;
3. 查询出基础数据中重复多余的基础数据;
4. 根据3查询出的重复数据,在功能数据表中查询出使用了重复数据的数据;
5. 更新功能数据表中重复的数据,使得所选择的基础数据关联ID相同;
6. 更新数据之后,清除基础数据表中的冗余数据。
以下是步骤:
第一步这里不说,主要说得是后面几步数据库操作。
2 解决过程
1.清除基础数据中没有使用过的数据
思路: 建立一张中间表temp,查询出使用过的基础数据,放在temp中。
SQL:
!#查询出使用过的基础数据,并且插入到临时表temp中 create table temp select * from tb_instrument_mapping_info where id in (select instru_mid from tb_instruments_info ) UNION select * from tb_instrument_mapping_info where id in (select major_id from tb_instruments_info ) UNION select * from tb_instrument_mapping_info where id in (select pro_id from tb_instruments_info )
!# 删除原来的基础数据表 drop table tb_instrument_mapping_info !#把临时表temp重命名为基础数据表 rename table temp to tb_instrument_mapping_info select * from tb_instrument_mapping_info
2.查询出基础数据中重复的数据,并且按照mapping_name分组
思路: 基础数据中设计为不重复,所以同一类型下count(mapping_name)>1的数据为重复数据
SQL:
!#查询出类型=3的重复mapping_name数据 select * from tb_instrument_mapping_info where mapping_type=3 GROUP BY mapping_name HAVING COUNT(mapping_name)>1
3.在功能数据表中根据查询出使用了多余数据的功能数据
思路: 在基础数据中查询出同一类型的重复数据之后,inner join 功能数据表,即可查询出使用了重复数据的数据
SQL:
select t3.* from (select t1.id,t1.instru_code,t1.spec_type,t1.major_id,t1.instru_mid,c.mapping_name,t1.pro_id from tb_instruments_info t1 LEFT JOIN tb_instrument_mapping_info c on t1.pro_id=c.id) t3 INNER JOIN (select * from tb_instrument_mapping_info where mapping_type=3 GROUP BY mapping_name HAVING COUNT(mapping_name)>1) t2 ON t3.mapping_name = t2.mapping_name
4.更新查询的重复数据,使得在mapping_name相同的同一类型数据,ID一致
思路:根据查询出的基础数据中的重复数据,如果功能数据表中的名称一致,则更新此条数据的基础数据关联字段值
SQL:
update tb_instruments_info t4 INNER JOIN (select t3.*,t2.id as mpid from (select t1.id,t1.instru_code,t1.spec_type,t1.major_id,t1.instru_mid,c.mapping_name,t1.pro_id from tb_instruments_info t1 LEFT JOIN tb_instrument_mapping_info c on t1.pro_id=c.id) t3 INNER JOIN (select id,mapping_name from tb_instrument_mapping_info where mapping_type=3 GROUP BY mapping_name HAVING COUNT(mapping_name)>1) t2 ON t3.mapping_name = t2.mapping_name) t5 on t4.id=t5.id set t4.pro_id=t5.mpid
经过以上几步,可以得出想要的结果。
3.技术难点
1.create table Table select
根据查询出来的结果,创建一张表。此用法大多用在创建临时表,和迁移数据时使用。需注意默认值的改变。
2.update TableA inner join TableB on TableA.id=TableB.id set TableA.name=TableB.name
根据TableB中的表的值,更新TableA中对应表的值,在MySQL中使用,其他数据库没有测试。
4.其他
根据一张表的数据更新另一张表:
https://stackoverflow.com/questions/11709043/mysql-update-column-with-value-from-another-table