MySQL查询 截取分析
学习 尚硅谷MySQL高级 周阳老师视频,总结笔记。
MySQL 慢查询 一般分析过程:
- 至少跑一天,观察,看生产的慢SQL情况。
- 开启慢查询日志,设置阈值,如超过5秒就是慢查询,将其抓取下来。
- explain SQL 分析
- show profile
- DBA 或运维 进行SQL服务器参数调优
查询优化
永远小表驱动大表
永远小表驱动大表,因为先查小表可以得到一些接下来查询的过滤条件,再查大表时可以根据这些过滤条件用上索引等内容增加整体查询速度。
IN和EXISTS 可以相互替代,要根据主从表的大小决定使用哪个:
select * from tb1 where tb1.id in (select id from tb2);
select * from tb1 where exists (select 1 from tb2 where tb1.id=tb2.id);主表比子表大用 IN ,相反用 EXISTS
因为 IN是子表驱动主表,EXISTS是主表驱动子表。

- IN:
先进行子查询,根据结果去到主表匹配满足条件的行。由于索引等的存在,如果子查询结果较少,通常较快。 - EXISTS:
对主查询的数据做loop循环,每次loop循环放到子查询中做条件验证,根据结果(True或False)决定主查询这条记录是否保留。
order by 关键字优化
order by 子句,尽量使用 Index 方式排序,避免使用 filesort 方式排序。
Index效率高,它指 mysql 扫描索引本身完成排序。
order by 满足两种情况,会使用Index 方式排序:
- order by 语句使用索引最佳左前缀法则
- 使用 where 子句与 order by 子句条件组合满足索引最佳左前缀法则
案例:
已知有复合索引 (age,birth)


order by 语句使用索引最佳左前缀法则 ,使用 index 方式排序。

order by 子句条件组合不满足索引最佳左前缀法则 ,使用 filesort 方式排序。

虽然 order by 条件组合顺序满足最佳左前缀法则 ,但一个升序一个降序,不能使用 index方式排序。
filesort 排序
如果不在索引列上,filesort 有两种排序算法
mysql4.1 之前使用双路排序:
两次扫描磁盘,最终得到数据,先取出order by排序的 列,放入Buffer中,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从磁盘中读取对应的数据输出。
mysql4.1 之后使用单路排序:
从磁盘读取查询需要的所有列,按照order by 列在Buffer 对它们进行排序,然后扫描排序后的列表进行输出,它的效率更快一些,避免了第二次读取磁盘。并且把随机IO变成了顺序IO,但是它会使用更多的空间,因为它把每行都保存在内存中。
单路排序可能的问题:
单路排序要把所有数据一次都读取出来,如果读取的数据超过了sort_buffer 的容量,则需要排完后再取,从而造成多次IO,反而得不偿失。
提高 order by 速度
除了索引的影响,还需考虑:
- 不要使用 select * ,只使用查询需要的字段,影响如下:
1.1 、当query 字段大小总和小于 max_length_for_sort_data ,而且排序字段不是 TEXT|BLOB 类型时,会用单路排序,否则会用老的多路排序。
1.2、 两种算法的数据都有可能超出 sort_buffer 的容量,超出之后,会创建 temp 文件进行排序,导致多次IO ,但是用单路排序算法风险更大(一次读取全部数据,占空间多),所以要提高 sort_buffer_size。 尝试提高 sort_buffer_size
不管用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程的尝试提高 max_length_for_sort_data
提高这个参数,会增加用改进算法即单路排序的概率。但是如果设的太高,数据总容量超出 sort_buffer_size的概率就增大,明显症状是高的磁盘IO活动和低的处理器使用率。
小总结
MySQL两种排序方式:文件排序(filesort)或扫描有序索引排序(index)
MySQL能为排序与查询使用相同的索引

group by 关键字优化
group by 实质是先排序后进行分组,遵循索引的最佳左前缀法则。
当无法使用索引列,增大 max_length_for_sort_data 和 sort_buffer _size 参数设置。
以上两点同 order by
注意 :where 高于 having ,能写在 where 限定的条件就不要写到 having中
慢查询日志
是什么
- MySQL的慢查询日志是 MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阈值的语句,具体指运行时间超过 long_query_time 值(默认为10秒)的SQL,会被记录到慢查询日志中。
- 对收集的慢查询SQL用explain 进行全面分析。
- 默认情况,MySQL慢查询日志记录功能是关闭的,需要手动设置开启。如果不是调优需要,不建议开启,因为它本身会消耗性能。
- 支持将日志记录写入文件中。
怎么用
查看是否开启
SHOW VARIABLES LIKE '%slow_query_log%'开启
set global slow_query_log=1;使用此命令开启慢查询日志只对当前数据库生效,如果MySQL重启后则会失效。
如果要永久生效,就必须修改配置文件 my.cnf ,配置如下参数后,重启。
slow_query_log=1
slow_query_log_file=/var/lib/mysql/mycomputerName-slow.log查看记录阈值
SHOW VARIABLES LIKE 'long_query_time%'默认为10秒
set global long_query_time=3;可以使用命令修改,也可以在 my.cnf 参数里面修改。
修改后需要重新连接或新开一个会话才能通过 SHOW VARIABLES LIKE ‘long_query_time%’看到修改值改变。或者用下面命令可直接看到修改后的值:
SHOW global VARIABLES LIKE 'long_query_time%'假如运行时间正好等于 long_query_time 的情况,并不会被记录下来。需要大于这个值才会被记录。
查看当已经生成了几条慢查询记录
SHOW GLOBAL status LIKE '%Slow_queries%'配置版
my.cnf 参数里面修改,永久生效
slow_query_log=1;
slow_query_log_file=/var/lib/mysql/mycomputerName-slow.log
long_query_time=3;
log_output=FILE;日志分析工具 mysqldumpslow
在生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活,MySQL提供了日志分析工具mysqldumpslow。
查看帮助信息:
mysqldumpslow –help
参数信息为:
- s:按照何种方式排序;
- c:访问次数
- l:锁定时间
- r:返回记录
- t:查询时间
- al:平均锁定时间
- ar:平均返回记录数
- at:平均查询时间
- t:返回前面多少条的数据
- g:后面搭配一个正则匹配模式,大小写不敏感
例子:
# 得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/XX-slow.log
# 得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/XX-slow.log
# 得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/XX-slow.log
# 建议在使用这些命令时结合| 和 more 使用,否则可能爆屏
mysqldumpslow -s r -t 10 /var/lib/mysql/XX-slow.log |more批量数据脚本
往表里插入1000w 数据
做压力测试时,可能需要像这样往数据库插入大量随机值
新建库和表
CREATE DATABASE bigData;
USE bigData;#建部门表 dept
CREATE TABLE dept(
id INT UNSIGNED PRIMARY KEY auto_increment,
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
)ENGINE=INNODB DEFAULT CHARSET=utf8;#建员工表 emp
CREATE TABLE emp(
id INT UNSIGNED PRIMARY KEY auto_increment,
empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*编号*/
ename VARCHAR(20) NOT NULL DEFAULT "",/*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/
hiredate Date NOT NULL,/*入职时间*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) NOT NULL,/*红利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0/*部门编号*/
)ENGINE=INNODB DEFAULT CHARSET=utf8;开启二进制日志选项log-bin
创建函数,假如报错:
This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you might want to use the less safe log_bin_trust_function_creators variable)
由于开启过慢查询日志,函数可能存在潜在的安全隐患,在默认情况下回阻止function的创建。
设置信任:
SHOW VARIABLES LIKE 'log_bin_trust_function_creators';
SET GLOBAL log_bin_trust_function_creators=1;上述方法重启后会失效,永久方法:
Windows下
my.ini[mysqld] 加上 log_bin_trust_function_creators=1
Linux 下
/etc/my.cnf 下 my.cnf[mysqld] 加上 log_bin_trust_function_creators=1
创建函数
#随机产生一个长度为 n 的字符串
DELIMITER $$
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIGKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE iDO
SET return_str=CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i=i+1;
END WHILE;
RETURN return_str;
END
$$ DELIMITER ; # 随机产生一个100-109的整数
DELIMITER $$
CREATE FUNCTION rand_num() RETURNS INT(5)
BEGIN
DECLARE i INT DEFAULT 0;
SET i=FLOOR(100+RAND()*10);
RETURN i;
END
$$ DELIMITER ;MySQL RAND()函数调用可以在0和1之间产生一个随机数
MySQL substring(str, pos, len) 函数,从第pos个位置开始截取(包含此位置的字符),截取len 个字符
调用上述函数:
SELECT rand_num();
SELECT rand_string(4);创建存储过程
往员部门表dept 插入数据的存储过程
需要传入 两个 整数,表示 部门编号从几开始,和插入数据的条数,其中部门名称和部门位置,调用rand_string() 函数,随机插入字符串。
插入数据操作使用事务。
DELIMITER $$
CREATE PROCEDURE insert_dept(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit=0;
REPEAT
SET i=i+1;
INSERT INTO dept(deptno,dname,loc) VALUES((START+i),rand_string(10),rand_string(8));
UNTIL i=max_num
END REPEAT;
COMMIT;
END
$$ DELIMITER;往员工表emp 插入数据的存储过程
ename调用rand_string() 函数,随机插入字符串,deptno 调用 rand_num() 出入一个100-109的随机数。
DELIMITER $$
CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit=0;
REPEAT
SET i=i+1;
INSERT INTO emp(empno,ename,job,mgr,hiredate,sal,comm,deptno) VALUES((START+i),rand_string(6),'SALESMAN',0001,CURDATE(),2000,400,rand_num());
UNTIL i=max_num
END REPEAT;
COMMIT;
END
$$ DELIMITER;调用存储过程
员工表有部门id外键,所以先插部门表
插10个部门记录,部门编号从101 起
CALL insert_dept(100,10);往 员工表 emp 插入 50万条数据,员工编号从100001其
CALL insert_emp(100000,500000);show profile
是什么
是mysql 提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于SQL的调优的测量。
默认是关闭状态,开启后默认保存近15次的运行结果。
怎么用
查看当前mysql版本是否支持
show VARIABLES LIKE 'profiling';开启功能
set profiling=on;运行SQL
运行一个耗时的SQL语句:
SELECT * FROM emp GROUP BY id%10 LIMIT 150000;SQL慢要不就是运算复杂,要不就是频繁IO。
查看结果
查看最近处理的几条SQL语句,以及他们的query_id 和 耗时。
SHOW PROFILES;诊断SQL
查看query_id 为210 的这条SQL的整个生命周期细粒度执行情况:
SHOW profile cpu,block io for QUERY 210;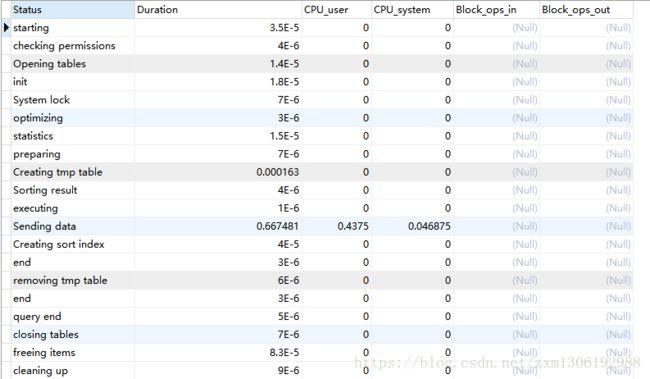
SHOW profile 的参数:
- all 显示所有的开销信息
- block IO 显示块IO相关开销
- context switches 上下文切换相关开销
- CPU 显示CPU相关开销信息
- IPC 显示发送和接收相关开销信息
- memory 显示内存相关开销信息
- page faults 显示页面错误相关开销信息
- source 显示和source_function,source_file,source_line 相关的开销信息
- swaps 显示交换次数相关开销信息
Status 需要注意的动作
查看SQL执行声明周期,status 字段出现以下动作需要注意,必须优化!
- converting HEAP to MyISAM 查询结果太大,内存都不够用了往磁盘上搬了
- creating tmp table 创建了临时表,一般后面还会有
- coping to tmp table
- removing tmp table
- coping to tmp table on disk 把内存中临时表复制到了磁盘,非常耗内存!
- locked
全局查询日志
只能在测试环境用,不要在生产环境使用
命令启用
set global general_log=1;
set global log_output='TABLE';此时,你编写的SQL语句,将会记录到mysql库里的general_log 表,查看:
select * from mysql.general_log;配置启用
在mysql 的 my.cnf 中,设置如下
#开启
general_log=1
#记录日志文件的路径
general_log_file=/path/logfile
#输出格式
log_output=File