fake news相关 2019-2020 五篇论文阅读
创新点、改进点、实验用到的数据集、不足
文章目录
- 1 Bi-GCN
- 数据集
- 本文的亮点和要点
- 思考
- 2 Capturing the Style of Fake News
- 数据集
- 已有方法的问题
- 本文的亮点和要点
- 思考
- 3 WeFEND
- 数据集
- 已有方法的不足
- 文章的亮点和要点
- 思考
- 4 Proactive Discovery of Fake News Domains from Real-Time Social Media Feeds
- 数据集
- 文章的亮点和要点
- 思考
- 5 dEFEND
- 数据集
- 本文的亮点和要点
- 思考
- References
1 Bi-GCN

关键词:传播网络,GCN,谣言检测,早期检测
论文题目:Rumor Detection on Social Media with Bi-Directional Graph Convolutional Networks
论文来源:AAAI 2020
本文解决的问题是谣言检测,提出了Bi-GCN模型,并且实验结果显示该模型在谣言的早期检测中也起到了很好的效果。
数据集
- Weibo[1]
- Twitter15[2]
- Twitter16[2]
本文的亮点和要点
(1)第一个使用基于GCN的方法进行了谣言检测任务。
(2)和以往方法不同的是,模型考虑到了自顶向下的谣言传播(propagation)结构,和自底向上的来自不同社区的谣言散布(dispersion)结构。具体表现为Bi-GCN由TD-GCN(top-down GCN)和BU-GCN(bottom-up GCN)两个组件所构成。以往的方法大多只使用到了自顶向下的谣言传播结构。有基于CNN的方法考虑到了散布结构,但是由于其不能处理图结构的数据,因此不能捕获全局的结构信息。
(3)模型还使用到了根源帖子特征的增强。具体来说是在GCN每层GCL中,对于每个节点,将根源帖子在上一层的隐层特征表示和节点在该层的隐层特征表示向拼接起来,作为节点在该层的最终隐层特征表示。这种方法增强了谣言根源帖子对于学习到其他帖子节点表示的影响力,可帮助模型学习得到更有助于谣言检测的节点表示。
(4)还使用到了较新的DropEdge方法,以缓解基于GCN的模型的过拟合问题。
思考
本文模型是针对谣言传播网络建模的,构建的图中只有帖子的信息和帖子间的关联信息,我认为这是个同质图。后续能不能考虑利用上用户和帖子的关系,以及用户间的关系,建模成一个异质图,然后在此基础上使用基于GNN的方法,进行谣言检测任务。
2 Capturing the Style of Fake News

关键词:写作风格,特征,LSTM,假新闻检测
论文题目:Capturing the Style of Fake News
论文来源:AAAI 2020
本文的目的是基于文档内容,检测出写作风格,而不侧重于文档含义,从而实现假新闻的自动检测。通用的文本分类器,尽管在简单评估时看起来性能很好,但实际上会过拟合训练数据中的文本。
设计了两个新的分类器:一个神经网络和一个基于风格特征的模型。
作者将本文的方法和通用目的的分类器(bag of words, BERT)进行了对比,评估结果表明,所提出的分类器在未见过的主题(例如新事件)和未见过的来源(例如 新出现的新闻网站)的文档中都保持了较高的准确性。对风格模型的分析显示,它确实侧重于了耸人听闻(sensational)和情感(affective)的这类典型的假新闻词汇。
数据集
为了实现真正的基于风格的预测,作者从媒体专家标注的223个在线资源中获取了103,219个文档,共117M个tokens。
数据集和代码已公开:https://github.com/piotrmp/fakestyle
已有方法的问题
已有的机器学习方法,使用了通用目的的文本分类器算法。不足在于,这样的方法让我们不能直接控制可信度评估具体是基于哪些特征的。作者希望分类器有可解释性:即能知道对于特定的决策,哪些特征是重要的;并且分类器还应具备泛化能力。
已有的方法受限于可获得的数据量,会导致对特定主题或来源的数据的过拟合。
本文的亮点和要点
为了对来源间topic的不同进行建模,使用LDA建模了100个topic。将每个文档都分配到其相关度最高的topic。
(1)基于风格的分类器
使用风格特征的集合,进行线性建模。
1)使用POS tags的n-grams而不是单词的n-grams,以避免使用让分类器对特定的来源或主题过拟合的特征。
2)在风格分析中使用字典,例如用于假新闻检测的LIWC[3]和用于hyperpartisan新闻识别的GI[4]。作者采用word2vec方法对这些资源里每个类别的单词选取相似的单词,以实现对字典的扩展。
3)使用Stanford CoreNLP对文档进行预处理,例如句子分割、tokenisation和POS tagging。并利用标注信息生成文档特征。
4)使用两阶段的方法检测相关的特征:首先preliminary filtering,然后building a regularised classifier。
在过滤阶段,作者使用Pearson相关度和输出变量。首先,观察特征 j j j是否出现在了文档 i i i中,并得到一个binary matirx。以往的方法过滤掉了出现在较少文档(低于2.5%或10%)中的特征。但这些低频特征也可能很重要,只要它们出现在的大部分文档都属于同一类别。因此,作者引入了类别标签,并考虑了标签和binary matirx中每个特征的相关度大于0.05的特征。
构建了一个logistic regression模型,以得到文档属于不可信类别的概率。使用了 L 1 L_1 L1正则化。
(2)神经网络分类器BiLSTMAvg
BiLSTMAvg是一个神经网络,基于NLP中使用的元素,例如词嵌入、Bi-LSTM。在LSTM的基础上,添加一个额外层,对所有句子的可信度得分进行平均以得到整个文档的得分。神经网络结构如下:
- 嵌入层:在Google News上进行训练,为每个token得到word2vec向量;
- 两层LSTM:前向和反向,使用两个100维向量表示每个句子;
- densely-connected层:将维度减少为2并应用softmax计算类别概率;
- 平均层:对文档中所有句子的类别概率分值求平均,以得到整个文档的得分。
(3)作者在实验时采用了5-fold交叉验证(CV),并且设置了三种不同的场景,分别是plain document-based CV, topic-based CV和source-based CV。这样就可以评估模型在训练时没出现过的topic或source上的性能。
思考
(1)文章提出了两个模型,其一是BiLSTMAvg,其二是Stylometric。只有后者运用到了和风格有关的特征。而且在实验对比中,source CV情境下,BiLSTMAvg的效果要好于Stylometric。但是作者只具体分析了基于风格的Stylometric方法对不同来源的数据分类性能。
(2)我认为本文中所说的风格体现在词级别上,是否可以考虑更粗粒度的级别,或者更抽象一些的方面。
(3)作者提出了3个评估场景,未来可以考虑其他的更多的评估场景。
(4)本文是利用文档的风格,为新闻的可信度进行打分,从而检测出假新闻,可以归为content-based类的方法。文章的角度很有新意,针对以往的通用分类模型在信息来源和相关主题上会有过拟合现象,因此设计了有现实意义的评估场景(3个CV),以衡量可信度评估方法的性能。在社交网络上的假新闻检测,可以考虑将风格信息和社交网络上下文的信息相结合。
3 WeFEND

关键词:训练数据,强化学习,众包信号(crowd signal),假新闻检测
论文题目:Weak Supervision for Fake News Detection via Reinforcement Learning
论文来源:AAAI 2020
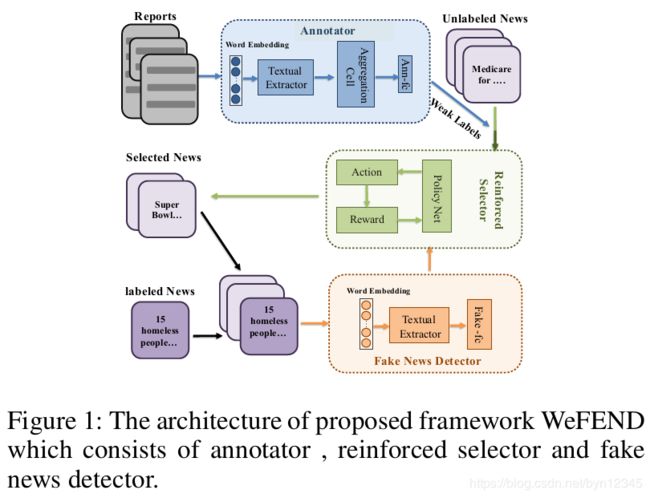
本文为了解决高质量的及时的且有标注的新闻数据获取问题,以用于尽早检测出假新闻,提出增强的弱监督假新闻检测框架WeFEND。该模型利用了用户的反馈作为弱监督来增加用于假新闻检测的训练数据。
模型由3个主要部分组成:标注器,增强的选择器和假新闻检测器。标注器可以基于用户的反馈,自动地为未标注的新闻分配弱标签。增强的选择器使用了强化学习技术,从被弱标注的数据中选择高质量的样本,过滤掉可能会降低检测器性能的低质量样本。假新闻检测器目的是基于新闻内容识别出假新闻。
数据集
微信官方账号发布的新闻文章,以及其对应的用户反馈信息。
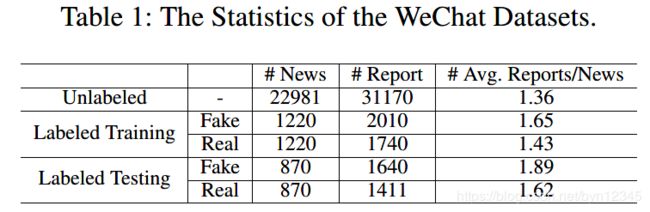
数据集:https://github.com/yaqingwang/WeFEND-AAAI20
已有方法的不足
(1)基于社交上下文的特征:利用了社交媒体上用户对新闻的行为,例如转发、网络结构等。但是这些社交上下文的特征只能在一段时间后才能获得,不能用于及时地检测出新出现的假新闻。
(2)基于新闻内容的特征:对于传统的机器学习方法,人工设计特征很难。使用深度学习的模型没有这个问题,但是其性能受训练数据规模的限制,缺少新鲜高质量的样本用于训练。
(3)现有的引入众包信号的方法:从用户标记为是潜在假新闻的样本中,选择一部分交付给专家进行确认,相当于仍需要人工标注,并且没有考虑到有价值的评论反馈信息。
文章的亮点和要点
本文针对的是假新闻检测训练数据获取问题,提出了WeFEND模型,以自动标注新闻文章,增加训练集的数据规模,从而有助于假新闻检测的深度学习模型性能的提高。
动机是:人工标注费时费力,并且通常不能及时地对新闻数据进行标注。训练数据限制了深度学习模型的性能。
主要思想是:将用户对新闻的反馈(如 评论)视为弱标注信息,收集大量的用户反馈信息有助于缓解假新闻检测领域的有标签数据较少的问题。
面临的问题是:用户的反馈信息有噪声,如何将这种弱标注信息转换为训练集中的标注样本,如何选择高质量的样本。
WeFEND模型的流程是:
(1)标注器:首先使用给定的一小组有标签的假新闻样本和用户对这些新闻的反馈,基于反馈训练一个标注器。具体来说是先使用文本特征抽取器,从新闻的用户反馈信息中抽取出特征;然后再输入给聚合函数,聚合不同用户的反馈信息;最后经过一个全连接层,得到预测概率。使用训练后的标注器处理未标注的新闻,基于未标注新闻的用户反馈,为未标注的新闻分配弱标签;
(2)增强的选择器:使用强化学习技术,从弱标注的样本中选择高质量的样本,并将其作为假新闻分类器的输入。选择的标准是增加所选的样本是否能提高假新闻检测的性能。;
(3)假新闻分类器:基于新闻的内容,为每个输入的文章分配一个标签。
文章的亮点在于:
(1)为了及时地得到大量有效的标注样本,提出利用用户对新闻的反馈信息作为弱监督信息,为未标注的新闻样本标注上弱标签。考虑到用户反馈信息含有噪声,因此提出使用强化学习技术对自动标注的样本进行选择,选取高质量的样本添加到训练集中。
(1)进行了多样的实验:
1)在实验中比较了不同时间窗口下的特征表示不同以及模型性能的不同,证明了新闻的分布具有动态性,因此说明了应该及时标注和新出现事件相关的新闻。
2)实验证明了用户反馈信息的有效性,使用这一信息,标注器在相同和不同时间窗口对应的数据上,有着相似的表现。并且用户反馈信息的特征不具有随时间变化的动态性。
3)训练集和测试集的数据在时间上并不相交,因此可以验证模型对新鲜数据进行分类的效果。
思考
(1)标注器部分对同一篇新闻的所有用户评论信息进行了聚合,作者使用的是平均操作作为无序的聚合函数。是否可以考虑在聚合时使用注意力机制。
(2)在人工标注时仅根据标题(headline)信息,因此模型中也是仅使用标题作为输入数据,而没有考虑新闻文章具体内容。
(3)个人感觉这篇论文的实验做得很好,尤其是通过实验,对新闻的分布是否随时间变化以及为什么要使用用户反馈信息做出了有说服力的解释。
4 Proactive Discovery of Fake News Domains from Real-Time Social Media Feeds

关键词:实时,社交网络,主动发现,图,社交网络账号,假新闻来源检测
论文题目:Proactive Discovery of Fake News Domains from Real-Time Social Media Feeds
论文来源:WWW 2020
本文解决的问题是假新闻新来源的主动检测,目的是在假新闻被人工标注前将其识别出来,以最小化假新闻的有害影响。本文是第一个研究及时发现假新闻来源的工作。
利用了无标注但有结构的实时社交媒体数据,检测系统以域(domain)为检测单元。假新闻域的定义是:捏造信息、散布欺骗性的内容或严重歪曲实际新闻的网站。
系统一共分为两步:1)使用Twitter来发现用户共享结构以发现政治有关的网站;2)使用topic-agnostic分类器打分并排序新发现的领域。
作者还设计了用户界面,利用用户的知识,有助于促进事实核查过程。
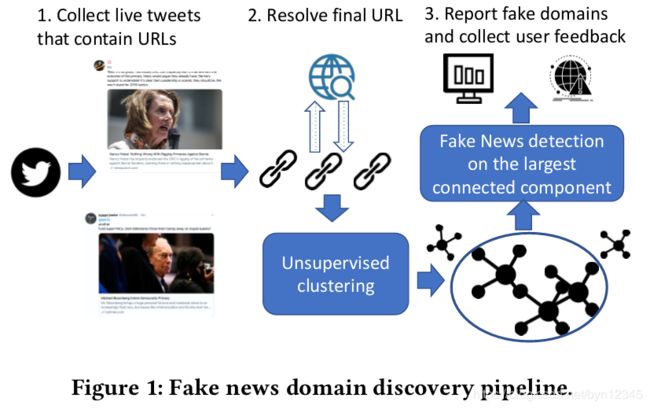
数据集
使用的训练集是文献[5]中的使用的PoliticalFakeNews。7,136 pages from 79 fake sites, and 7,104 pages from 58 real sites
评估时使用MediaBiasFactCheck(MBFC)提供的有限的标签ground truth去近似global ground truth。Github上有MBFC发布和更新的所有有标签的域(domain)。
https://raw.githubusercontent.com/drmikecrowe/mbfcext/master/docs/revised/csources.json
文章的亮点和要点
(1)作者认为覆盖了相似话题的域(domain),可能被相似的用户tweeted或retweeted(回音壁效应)。
因此,使用了Twitter中的信息基于用户共享相似度,构建了一个域交互图(对域聚类)。将每个域映射到发布和该域有关推文的用户集上。构建了一个无向图,节点表示一个域,若两节点对应的用户集之间的jaccard相似度大于某一阈值,则两节点间有边相连。
构建好图之后,运用算法抽取出网络中所有的聚类簇。
(2)系统的最后一步是对发现的域进行打分和排序。使用了文献[5]中提出的topic-agnostic假新闻分类器(TAG),输出对新闻是假新闻的打分。
本文使用的topic-agnostic分类器[5]捕获了假新闻网站的写作风格和布局风格信息,没有获得话题信息,因为预测未来新闻的话题是很困难的。并且,网站发布的新闻主题可能每天都在变化,但是网站的风格不会变化地很频繁。
作者对TAG做出的改进:
1)添加了Quantile Transformer将每个特征转换为正态分布,这一方法是鲁棒的预处理模式,可以减少异常点的影响。
2)识别训练数据中的异常:丢弃了单词总数小于200或大于2000的web pages。前者是有404错误的网页,后者是与某一新闻无关的目录页。
3)去掉了原始方法中用于捕获单词语义模式(生气 恐惧 高兴等)的心理学特征。因为这组特征需要人工处理,不符合本文自动检测的需求。
(3)TAG分类器将web page作为输入,得到了page级别的分值,我们还要得到有多个pages的域级别的分值。具体方法是使用custom headliss Chrome爬取器,访问域主页,解析HTML内容,随机选取有相同域的5个超链接。针对域的分值就是这5个pages分值的平均值。
(4)关于社交网络账号:
1)使用domain-level fakeness分值推断出account-level fakeness分值。
将账号最近发布的200个推文的domain-level fakeness分值取平均,作为该账号的fakeness score。
将此分值和任意获得到的特征结合,可用于social bot detection, troll detection或sentiment analysis等下游任务。
2)使用Botometer方法检测了本文收集到的账号是否是bot的概率,结果证明了绝大部分账号都是正常的。
3)关于账号描述
根据账号的得分将其分为三类:likely to share fake news, might likely to share fake news, not likely to share fake news。并没有发现这三类账号在发推数量、朋友数量、关注者数量上分布的区别,但是发现了不同类别的账号在账号描述上有所区别。
还发现了不同类别账号的人口统计特征不同,但这一点还有待进一步的研究。
本文的亮点:利用实时社交网络构建出了域(domain)交互图,利用该网络,实现了主动发现假新闻域。系统结合了无监督聚类、有监督预测和用户交互。(文中所说的域的概念,应该值得是新闻的来源)
思考
本文的局限性:
(1)采样偏差和选择偏差
采样偏差来源于US-centric训练集。选择偏差来自于2部分,一个是本文的系统仅聚焦于Twitter,另一个是数据收集过程需要人为输入关键词,这一操作受主观因素的影响。
采样偏差的缓解可使用本文的系统,从事实核查者收集反馈信息。作者也考虑收集不同国家不同语言的fake和real domains。
选择偏差的缓解可通过从多个社交媒体中收集数据,使用多样的关键词、hashtags、user handles来捕获潜在的新闻发布者。例如,从fakeness得分高的账号那里收集实时的推文,替代特定的关键词。
(2)缺乏统一的数据集和评价框架
数据集:使用以前的数据集是有风险的,因为对手可能恰恰利用相同的数据集来逃避检测。
评价:评价新发现的域是很耗时的。作者计划将用户界面引入到研究社区、事实核查群里和社交媒体公司,以加速标签的产生。
(3)未来可以利用更多的群体智能知识。
(4)本文构建的域交互图只是用来做了域聚类,因为本文的目的是检测新出现的假新闻来源,因此没有利用到社交网络中其他更多的信息,例如传播信息。后续可以考虑针对具体任务,从不同的角度建模图。
5 dEFEND

关键词:可解释性,社交网络,层级注意力机制,共同注意力机制(co-attention),假新闻检测
论文题目:dEFEND: Explainable Fake News Detection
论文来源:SIGKDD 2019
本文解决的是假新闻检测模型的可解释性问题。提出了具有可解释性的假新闻检测方法dEFEND。在社交媒体上的假新闻检测领域,是第一个尝试提出具有可解释的模型的研究。
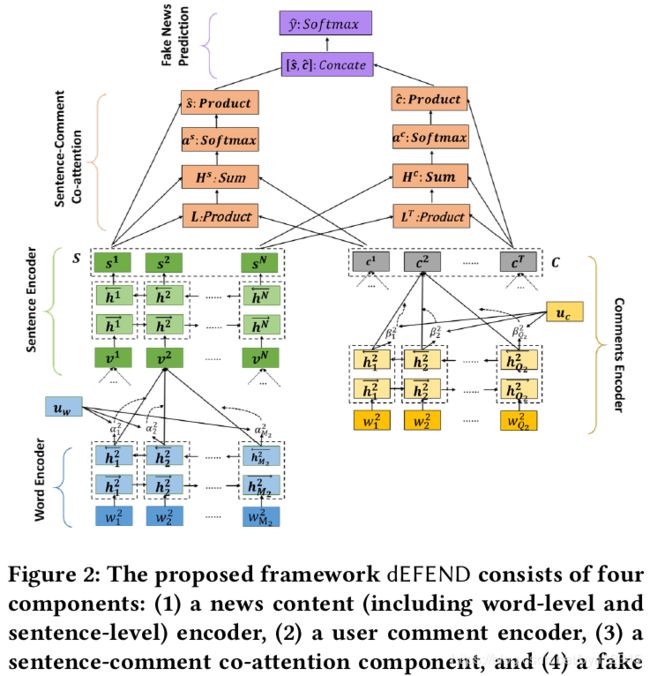
本文利用新闻内容和用户评论,设计了sentence-comment co-attention subnetwork,联合捕获了可解释的 t o p − k top-k top−k个值得检查的句子和用户评论,以用于假新闻检测。
实验结果显示,本文的模型不仅显著优于7个state-of-the-art假新闻检测方法,还可以同时识别出 t o p − k top-k top−k个解释这一新闻为什么是假新闻的用户评论。
数据集
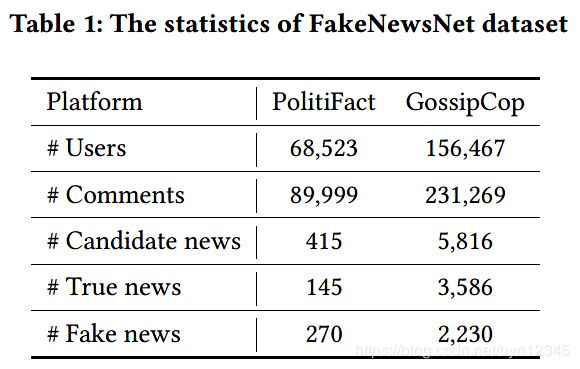
使用的是假新闻检测基线数据集:FakeNewsNet[6-7]
本文的亮点和要点
本文要解决的问题是假新闻检测模型的可解释性。
本文解决的挑战:
(1)如何实现可解释的假新闻检测,并同时提高检测性能和可解释性;
(2)在训练时没有ground truth的条件下,如何抽取出有解释性的评论;
(3)如何联合建模新闻内容和用户评论间的关系,以 实现有解释性的假新闻检测。
利用了新闻内容和用户评论信息。检测框架由以下几部分组成:
(1)编码新闻内容组件:通过层级(word-, sentence-level)注意力神经网络,捕获新闻句子中的语义信息和句法信息,学习得到新闻句子的表示。
具体来说分为两步,首先使用双向GRU对每个句子中的单词序列进行编码,并使用了注意力机制为不同的单词赋予不同的重要性权重,聚合得到每个句子的表示。然后使用双向GRU,上一步得到的句子向量表示作为输入,对一篇新闻中的句子序列进行编码,以捕获句子级别的上下文信息。将每个隐层的两个方向的表示拼接起来,就得到了融合了上下文句子信息的该句子的表示,最终就得到新闻内容的特征矩阵。
(2)编码用户评论组件:通过词级别的注意力子网络,学习到用户评论的隐层表示。
和编码新闻内容组件中的单词编码类似,使用双向GRU,对评论中的单词序列进行编码,同样也使用到了注意力机制。
(3)sentence-comment co-attention组件:捕获新闻内容和评论间的关联,并选择出 t o p − k top-k top−k个有解释性的句子和评论。
用户的评论可以提高假新闻检测的可解释性,新闻中的句子也可以。新闻内容中也有表达内容是真实的句子,只不过有时会用来支持错误的观点。因此新闻中的句子对于识别和解释假新闻也同等重要。
因此,将前两个组件得到的特征作为此组件的输入,作者设计了注意力机制为不同的新闻句子和评论表示分配权重。注意,这个sentence-comment co-attention机制捕获了句子和评论的semantic affinity,也同时学习到了句子和评论的注意力权重。使用了转换矩阵,实现了用户评论注意力空间到新闻句子注意力空间的转换。最终使用注意力权重分别聚合评论特征和新闻句子特征,得到评论和新闻句子的最终特征表示。
(4)假新闻预测组件:将新闻内容特征和用户评论特征相拼接,用于假新闻分类。
解释性评估实验:
句子解释性评估:使用ClaimBuster得到新闻句子排序列表 R S RS RS的ground truth R S ~ \tilde{RS} RS~。将本文方法选择出的 t o p − k top-k top−k(k=5或10)rank list和 R S ~ \tilde{RS} RS~比较,使用 M A P @ k MAP@k MAP@k作为度量,并于HAN和Random方法对比。结果显示本文模型效果最好。
用户评论解释性评估:使用2个Amazon Mechanical Turk(AMT)任务评估评论排序列表 R C RC RC的解释性。
AMT任务:https://www.mturk.com/
本文的亮点:
(1)本文要解决的问题是假新闻检测模型的可解释,很有研究意义,提出了具有可解释性的假新闻检测模型dEFEND。
(2)使用了层级注意力机制和共同注意力机制(co-attention)。前者在对新闻内容建模时使用,用到了单词级别的和句子级别的注意力;后者在对新闻内容和评论间关系建模时使用,在捕获了句子和评论的semantic affinity的同时,也学习到了句子和评论的注意力权重。
思考
未来工作:
(1)将事实核查网站或事实核查相关专家的知识合并进来,以进一步指导模型得到check-worthy的新闻句子。
(2)研究如何将其他用户的社交行为作为副信息引入,以帮助发现可解释的评论。
(3)考虑发布新闻的人的可信度,以进一步提高假新闻检测模型的性能。
本文的研究方向很有新意,假新闻检测的可解释性是值得进一步研究的方向。这篇文章从新闻中的句子和用户评论信息入手,给假新闻分类器提供了解释性。未来可以考虑能否从别的角度出发,处理可解释性的问题。例如,本文在建模时只考虑了一篇文章,能否利用已经被证实为真/假的其他文章,或者考虑使用由其他可信度非常高的机构发布的和待判断文章描述事件相似的文章,来为待判断文章的分类结果提供可解释性。
References
[1] Ma, J.; Gao, W.; Mitra, P.; Kwon, S.; Jansen, B. J.; Wong, K.-F.; and Cha, M. 2016. Detecting rumors from microblogs with recurrent neural networks. In Ijcai, 3818–3824.
[2] Ma, J.; Gao, W.; and Wong, K.-F. 2017. Detect rumors in microblog posts using propagation structure via kernel learning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 708–717.
[3] Tausczik, Y. R., and Pennebaker, J. W. 2009. The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods. Journal of Language and Social Psychology 29(1):24–54.
[4] Stone, P. J.; Bales, R. F.; Namenwirth, J. Z.; and Ogilvie, D. M. 1962. The general inquirer: A computer system for content analysis and retrieval based on the sentence as a unit of information. Behavioral Science 7(4):484–498.
[5] Sonia Castelo, Thais Almeida, Anas Elghafari, Aécio Santos, Kien Pham, Eduardo Nakamura, and Juliana Freire. 2019. A Topic-Agnostic Approach for Identifying Fake News Pages. In Companion Proceedings of The 2019 World Wide Web Conference (San Francisco, USA) (WWW ’19). ACM, New York, NY, USA, 975–980. https://doi.org/10.1145/3308560.3316739
[6] Kai Shu, Deepak Mahudeswaran, Suhang Wang, Dongwon Lee, and Huan Liu. 2018. FakeNewsNet: A Data Repository with News Content, Social Context and Dynamic Information for Studying Fake News on Social Media. arXiv preprint arXiv:1809.01286 (2018).
[7] Kai Shu, Amy Sliva, Suhang Wang, Jiliang Tang, and Huan Liu. 2017. Fake News Detection on Social Media: A Data Mining Perspective. KDD exploration newsletter (2017).