keras集成学习三-分类问题
keras集成学习三-分类问题
- 数据描述
- keras普通实现
- 模型结构
- 模型输出
- 模型损失以及准确率曲线
- keras-scikit_learn集成学习
- 模型输出
- keras集成学习-学习法
- 模型结构
- 模型输出
- 模型损失以及准确率曲线
- 代码位置
文档完整位置:https://docs.nn.knowledge-precipitation.site/ji-chu-zhi-shi/guo-ni-he/jichengxuexi-ensemble/fenlei-keras
- keras集成学习一
- keras集成学习二-回归问题
- keras集成学习三-分类问题
数据描述
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:
- Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
- Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
- Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
- Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
keras普通实现
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
from sklearn.preprocessing import OneHotEncoder
def load_data():
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], 28 * 28)
x_test = x_test.reshape(x_test.shape[0], 28 * 28)
y_train = OneHotEncoder().fit_transform(y_train.reshape(-1,1))
y_test = OneHotEncoder().fit_transform(y_test.reshape(-1,1))
return (x_train, y_train), (x_test, y_test)
def build_model():
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=(784, )))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='Adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
#画出训练过程中训练和验证的精度与损失
def draw_train_history(history):
plt.figure(1)
# summarize history for accuracy
plt.subplot(211)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'])
# summarize history for loss
plt.subplot(212)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'])
plt.show()
if __name__ == '__main__':
(x_train, y_train), (x_test, y_test) = load_data()
model = build_model()
history = model.fit(x_train, y_train,
epochs=20,
batch_size=64,
validation_split=0.3)
draw_train_history(history)
model.save("classification.h5")
loss, accuracy = model.evaluate(x_test, y_test)
print("test loss: {}, test accuracy: {}".format(loss, accuracy))
weights = model.get_weights()
print("weights: ", weights)
模型结构

模型输出
test loss: 0.13618469612854534, test accuracy: 0.972000002861023
模型损失以及准确率曲线
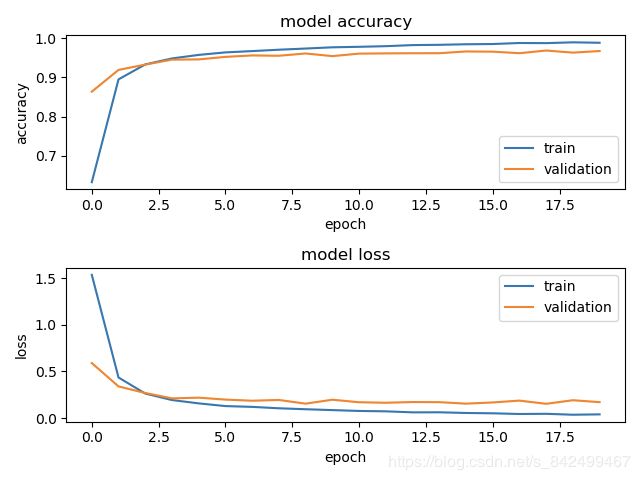
keras-scikit_learn集成学习
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.wrappers.scikit_learn import KerasClassifier
from keras.models import Sequential
from keras.layers import Dense
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import VotingClassifier
from sklearn.model_selection import cross_val_score
from pathlib import Path
def load_data():
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], 28 * 28)
x_test = x_test.reshape(x_test.shape[0], 28 * 28)
y_train = LabelEncoder().fit_transform(y_train.reshape(-1,1))
y_test = LabelEncoder().fit_transform(y_test.reshape(-1,1))
return (x_train, y_train), (x_test, y_test)
#画出训练过程中训练和验证的精度与损失
def draw_train_history(history):
plt.figure(1)
# summarize history for accuracy
plt.subplot(211)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'])
# summarize history for loss
plt.subplot(212)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'])
plt.show()
def build_model(hidden_units):
model = Sequential()
for index, unit in enumerate(hidden_units):
if index == 0:
model.add(Dense(unit, activation='relu', input_shape=(784, )))
else:
model.add(Dense(unit, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='Adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
def build_model1():
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=(784, )))
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='Adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
def build_model2():
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(784, )))
model.add(Dense(32, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='Adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
def build_model3():
model = Sequential()
model.add(Dense(32, activation='relu', input_shape=(784, )))
model.add(Dense(16, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='Adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
if __name__ == '__main__':
(x_train, y_train), (x_test, y_test) = load_data()
model1 = KerasClassifier(build_fn=build_model1, epochs=20, batch_size=64)
model1._estimator_type = "classifier"
model2 = KerasClassifier(build_fn=build_model2, epochs=20, batch_size=64)
model2._estimator_type = "classifier"
model3 = KerasClassifier(build_fn=build_model3, epochs=20, batch_size=64)
model3._estimator_type = "classifier"
# if ‘hard’, uses predicted class labels for majority rule voting.
# if ‘soft’, predicts the class label based on the argmax of the
# sums of the predicted probabilities,
# which is recommended for an ensemble of well-calibrated classifiers.
cls = VotingClassifier(estimators=(['model1', model1],
['model2', model2],
['model3', model3]),
voting='hard')
cls.fit(x_train, y_train)
print("score: ", cls.score(x_test, y_test))
这里需要注意VotingClassifier中的voting参数:
- hard:少数服从多数
- soft:通过预测概率和的最大位置作为预测标签,也是比较推荐的方式
而且这里我们使用的是VotingClassifier,在scikit_learn中,也就代表将每个基学习器的结果通过不同的投票策略生成最终的输出,我们来看一下在sklearn文档中的描述
Soft Voting/Majority Rule classifier for unfitted estimators.
如果我们使用StackingClassifier的话,就是接下来要实现的学习法,我们来看一下sklearn文档中的描述
Stacked generalization consists in stacking the output of individual estimator and use a classifier to compute the final prediction. Stacking allows to use the strength of each individual estimator by using their output as input of a final estimator.
模型输出
score: 0.9711
keras集成学习-学习法
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.models import Model
from keras.layers import Input, Dense, concatenate
from sklearn.preprocessing import OneHotEncoder
def load_data():
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], 28 * 28)
x_test = x_test.reshape(x_test.shape[0], 28 * 28)
y_train = OneHotEncoder().fit_transform(y_train.reshape(-1,1))
y_test = OneHotEncoder().fit_transform(y_test.reshape(-1,1))
return (x_train, y_train), (x_test, y_test)
#画出训练过程中训练和验证的精度与损失
def draw_train_history(history):
plt.figure(1)
# summarize history for accuracy
plt.subplot(211)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'])
# summarize history for loss
plt.subplot(212)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'])
plt.show()
def build_model():
inputs = Input(shape=(784, ))
model1_1 = Dense(64, activation='relu')(inputs)
model2_1 = Dense(128, activation='relu')(inputs)
model3_1 = Dense(32, activation='relu')(inputs)
model1_2 = Dense(32, activation='relu')(model1_1)
model2_2 = Dense(64, activation='relu')(model2_1)
model3_2 = Dense(16, activation='relu')(model3_1)
model1_3 = Dense(16, activation='relu')(model1_2)
model2_3 = Dense(32, activation='relu')(model2_2)
model3_3 = Dense(8, activation='relu')(model3_2)
con = concatenate([model1_3, model2_3, model3_3])
output = Dense(10, activation='softmax')(con)
model = Model(inputs=inputs, outputs=output)
model.compile(optimizer='Adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
if __name__ == '__main__':
(x_train, y_train), (x_test, y_test) = load_data()
model = build_model()
history = model.fit(x_train, y_train,
epochs=20,
batch_size=64,
validation_split=0.3)
draw_train_history(history)
model.save("classification-learning-ensemble.h5")
loss, accuracy = model.evaluate(x_test, y_test)
print("test loss: {}, test accuracy: {}".format(loss, accuracy))
模型结构

模型输出
test loss: 0.14912846596296658, test accuracy: 0.9682000279426575
模型损失以及准确率曲线
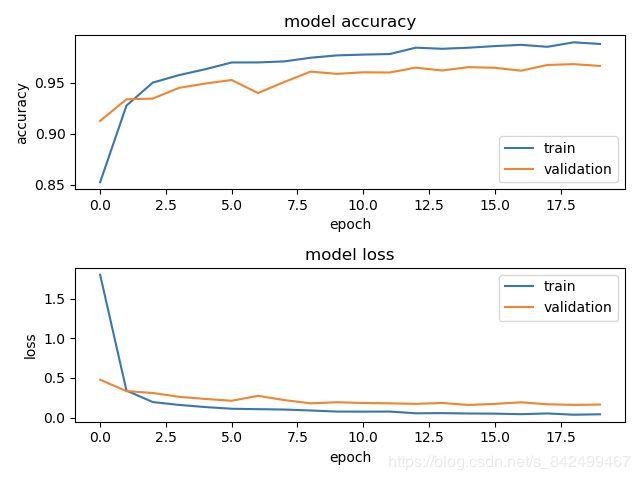
代码位置
https://github.com/Knowledge-Precipitation-Tribe/Neural-network/tree/master/code/Ensemble-Learning