Hadoop中的MapReduce
一、课程概述
依赖jar包
$HADOOP_HOME/share/hadoop/common
$HADOOP_HOME/share/hadoop/common/lib
$HADOOP_HOME/share/hadoop/mapreduce
$HADOOP_HOME/share/hadoop/mapreducel/lib
二、MapReduce编程基础
案例一
案例二:员工表
三、MapReduce的特性
1、序列化:接口Writable
一个类实现了这个接口,该类的对象就可以作为key value(Map和Reduce的输入和输出)
注意:序列化的顺序,一定要跟反序列的顺序一样
复习:Java序列化:接口
如果一个类实现了Serializable接口,该类的对象可以作为InputStream(反序列化)和OutputStream对象(序列化)
2、排序: 复习:SQL的排序: order by语句
(*) order by 后面 + 列名、表达式、别名、序号
select * from emp order by sal;
select empno,ename,sal,sal*12 from emp order by sal*12;
select empno,ename,sal,sal*12 annlsal from emp order by annlsal;
select empno,ename,sal,sal*12 annlsal from emp order by 4;
(*)order by + 多个列
select * from emp order by deptno desc,sal desc;
order by 作用后面所有的列
desc 离他最近的列
(*)补充一点:查询员工信息,按照奖金排序
降序排序,一定要把null值排在最后
select * from emp order by comm desc nulls last;
(*)问题:order by后得到的表,是原来的表吗?(不是,order by执行后,会产生一张临时表)
MapReduce排序:重要:按照key2(数字、字符串、对象)进行排序
(1)基本数据类型:数字 : 升序
举例:查询员工的薪水,按照升序排序
降序:重写一个比较器
字符串 : 字典顺序
举例:WordCount单词计数
(2)对象的排序: 实现一个接口:WritableComparable
Demo 1:一个列的排序
Demo 2:多个列排序
按照员工的部门号、薪水排序
select * from emp order by deptno,sal;
3、分区:(1)什么分区: partition

(2)MapReduce的分区(输出文件)
(*) 默认情况下,MapReduce只有一个分区
(*) 如果自定义分区,根据Map的输出来建立分区
Demo:按照员工的部门号进行分区
4、合并(Combiner): 是一种特殊Reducer
在Mapper端,先执行一次Reducer -----> 提高效率
减少Mapper输出到Reduce的数据量
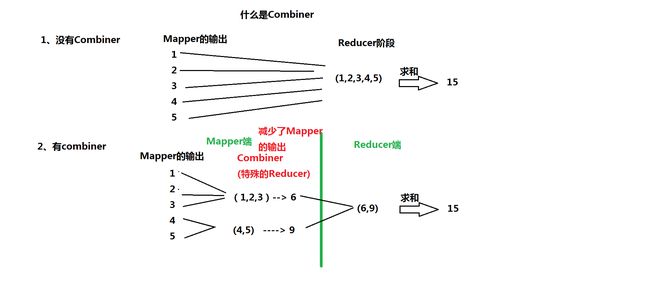

需要注意的问题:一定要谨慎使用Combiner
Error: java.io.IOException: wrong value class: class org.apache.hadoop.io.DoubleWritable is not class org.apache.hadoop.io.IntWritable
留个问题:如何保证Combiner的引入不改变原来的逻辑? ---> 使用MapReduce实现倒排索引
四、MapReduce的核心: shuffle 洗牌
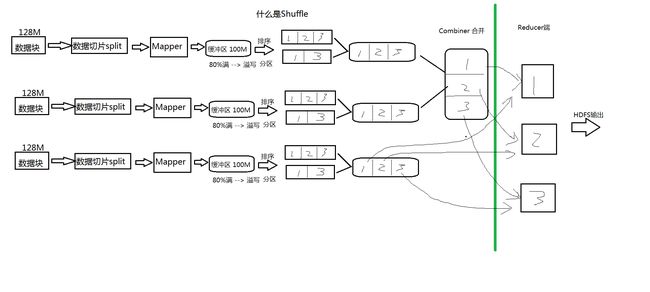
五、MapReduce编程案例-------> 更重要:一套方法(授人予鱼 不如授人予渔)
1、数据去重:distinct
复习:distinct 作用于后面所有的列
2、多表查询:部门表、员工表
select d.dname,e.ename
from emp e,dept d
where e.deptno=d.deptno

(3)自连接: 通过表的别名,将同一张表看成多张表
(*)什么是自连接?
查询员工信息:显示:老板的名字 员工的名字

select 老板姓名,员工的姓名
from b,e
where 老板的员工号=员工的老板号
select b.ename "Boss",e.ename "Employee"
from emp b,emp e
where b.empno=e.mgr;
如何得到跟MR一样的结果呢? 提示:组函数(多行函数) wm_concat 行转列
问题:思考自连接操作存在什么问题吗? ----> 不适合操作大表 ---> 层次查询(数据满足是一棵树的时候)
3、使用MapReduce实现倒排索引
(*)复习:倒排索引
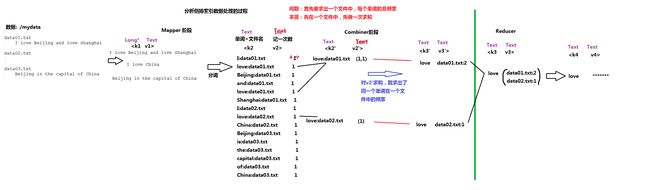
4、使用MRUnit进行单元测试: 注意:(1)需要把mockito-all-1.8.5.jar从Build Path中去掉
(2)需要windows的工具
Eclipse使用Hadoop的插件
2、数据仓库:就是一个数据库
3、Google三篇论文:GFS、MapReduce、BigTable
4、搭建Hadoop的环境
(1)免密码登录:不对称加密
(2)Hadoop的目录结构
(3)本地模式:没有HDFS、只能测试MapReduce程序
(4)伪分布模式:具备Hadoop所有功能
(5)全分布模式:至少3台
5、HDFS
(1)体系结构:NameNode、DataNode、SecondaryNameNode
(2)fsimage、edits文件
(3)原理:上传、下载过程
(4)操作:命令行、Java API、Web Console(50070、50090)
(5)功能:回收站、快照、配额(名称、空间)、安全模式
(6)底层原理:RPC、代理对象
6、MapReduce
(1)重要:数据处理的过程
(2)序列化、排序、分区、合并
(3)核心:Shuffle
(4)举例:去重、多表查询、倒排索引
(5)MR单元测试
依赖jar包
$HADOOP_HOME/share/hadoop/common
$HADOOP_HOME/share/hadoop/common/lib
$HADOOP_HOME/share/hadoop/mapreduce
$HADOOP_HOME/share/hadoop/mapreducel/lib
二、MapReduce编程基础
案例一
1、分析WordCount的数据处理的过程(流程 P28) ----> 重要
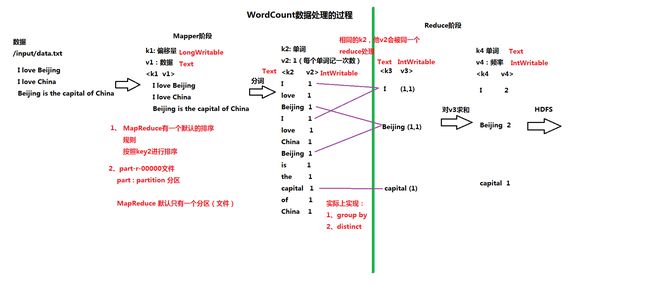
案例二:员工表
3、分析:求每个部门的工资总额数据的处理过程 SQL: select deptno,sum(sal) from emp group by deptno;
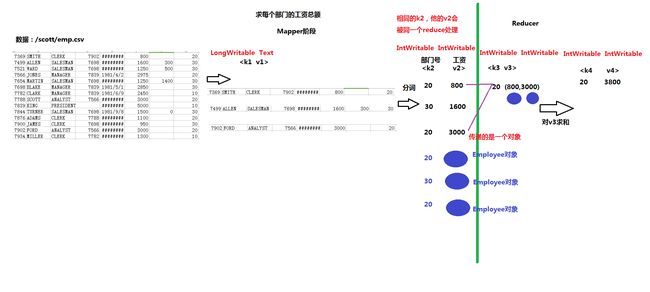
三、MapReduce的特性
1、序列化:接口Writable
一个类实现了这个接口,该类的对象就可以作为key value(Map和Reduce的输入和输出)
注意:序列化的顺序,一定要跟反序列的顺序一样
复习:Java序列化:接口
如果一个类实现了Serializable接口,该类的对象可以作为InputStream(反序列化)和OutputStream对象(序列化)
2、排序: 复习:SQL的排序: order by语句
(*) order by 后面 + 列名、表达式、别名、序号
select * from emp order by sal;
select empno,ename,sal,sal*12 from emp order by sal*12;
select empno,ename,sal,sal*12 annlsal from emp order by annlsal;
select empno,ename,sal,sal*12 annlsal from emp order by 4;
(*)order by + 多个列
select * from emp order by deptno desc,sal desc;
order by 作用后面所有的列
desc 离他最近的列
(*)补充一点:查询员工信息,按照奖金排序
降序排序,一定要把null值排在最后
select * from emp order by comm desc nulls last;
(*)问题:order by后得到的表,是原来的表吗?(不是,order by执行后,会产生一张临时表)
MapReduce排序:重要:按照key2(数字、字符串、对象)进行排序
(1)基本数据类型:数字 : 升序
举例:查询员工的薪水,按照升序排序
降序:重写一个比较器
字符串 : 字典顺序
举例:WordCount单词计数
(2)对象的排序: 实现一个接口:WritableComparable
Demo 1:一个列的排序
Demo 2:多个列排序
按照员工的部门号、薪水排序
select * from emp order by deptno,sal;
3、分区:(1)什么分区: partition
(*) 以Oracle数据库为例,解释什么是分区

(2)MapReduce的分区(输出文件)
(*) 默认情况下,MapReduce只有一个分区
(*) 如果自定义分区,根据Map的输出
Demo:按照员工的部门号进行分区
4、合并(Combiner): 是一种特殊Reducer
在Mapper端,先执行一次Reducer -----> 提高效率
减少Mapper输出到Reduce的数据量
需要注意的问题:一定要谨慎使用Combiner
(*)有些情况不能使用Combiner ----> 举例:求平均值
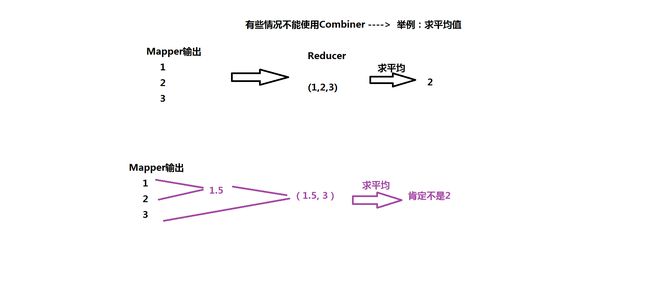
Error: java.io.IOException: wrong value class: class org.apache.hadoop.io.DoubleWritable is not class org.apache.hadoop.io.IntWritable
留个问题:如何保证Combiner的引入不改变原来的逻辑? ---> 使用MapReduce实现倒排索引
四、MapReduce的核心: shuffle 洗牌
五、MapReduce编程案例-------> 更重要:一套方法(授人予鱼 不如授人予渔)
1、数据去重:distinct
复习:distinct 作用于后面所有的列
2、多表查询:部门表、员工表
(1)复习:笛卡尔积

select d.dname,e.ename
from emp e,dept d
where e.deptno=d.deptno
(3)自连接: 通过表的别名,将同一张表看成多张表
(*)什么是自连接?
查询员工信息:显示:老板的名字 员工的名字
select 老板姓名,员工的姓名
from b,e
where 老板的员工号=员工的老板号
select b.ename "Boss",e.ename "Employee"
from emp b,emp e
where b.empno=e.mgr;
如何得到跟MR一样的结果呢? 提示:组函数(多行函数) wm_concat 行转列
问题:思考自连接操作存在什么问题吗? ----> 不适合操作大表 ---> 层次查询(数据满足是一棵树的时候)
3、使用MapReduce实现倒排索引
(*)复习:倒排索引
4、使用MRUnit进行单元测试: 注意:(1)需要把mockito-all-1.8.5.jar从Build Path中去掉
(2)需要windows的工具
Eclipse使用Hadoop的插件
六、第一个阶段小结:HDFS、MapReduce
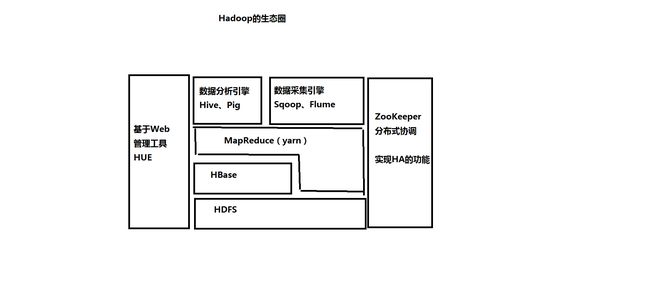
2、数据仓库:就是一个数据库
3、Google三篇论文:GFS、MapReduce、BigTable
4、搭建Hadoop的环境
(1)免密码登录:不对称加密
(2)Hadoop的目录结构
(3)本地模式:没有HDFS、只能测试MapReduce程序
(4)伪分布模式:具备Hadoop所有功能
(5)全分布模式:至少3台
5、HDFS
(1)体系结构:NameNode、DataNode、SecondaryNameNode
(2)fsimage、edits文件
(3)原理:上传、下载过程
(4)操作:命令行、Java API、Web Console(50070、50090)
(5)功能:回收站、快照、配额(名称、空间)、安全模式
(6)底层原理:RPC、代理对象
6、MapReduce
(1)重要:数据处理的过程
(2)序列化、排序、分区、合并
(3)核心:Shuffle
(4)举例:去重、多表查询、倒排索引
(5)MR单元测试