Hadoop系列文章SpringBoot编程实现HDFS读写文件、MapReduce程序
Hadoop系列文章 SpringBoot编程实现HDFS读写文件、MapReduce程序实现
- HDFS操作
- 引入依赖
- winutils
- 码代码
- 读取HDFS中的文件
- 写内容到文件中
- MapReduce操作
- MapReduce工作过程详解
- Mapper映射器
- Input的map
- map的output
- map的数量
- Reducer
- shuffle
- Sort(排序)
- 二次排序
- reduce
- Partitioner
- Counter
- 码代码
- 将程序放到服务器中运行
在Apache Hadoop 2中。Apache已经将资源管理功能剥离到Apache Hadoop
YARN中,这是一个通用的分布式应用管理框架,而Apache Hadoop
MapReduce(又名MRv2)仍然是一个纯粹的分布式计算框架。
一般来说,以前的MapReduce运行时(又称MRv1)已经被重用,并且没有对其进行重大的操作。因此,MRv2能够确保与MRv1应用程序的兼容性。然而,由于一些改进和代码重构,一些api被呈现为向后不兼容的。
首先hadoop运行程序要以jar包为主体,我用的是springboot项目,在生成jar包时用jar命令,用bootJar命令生成的jar包会有各种问题。
示例代码仓库
HDFS操作
引入依赖
// ========== HADOOP 相关
// https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common
compile group: 'org.apache.hadoop', name: 'hadoop-common', version: '3.2.1'
// https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs
compile group: 'org.apache.hadoop', name: 'hadoop-hdfs', version: '3.2.1'
// https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client
compile group: 'org.apache.hadoop', name: 'hadoop-client', version: '3.2.1'
compile group: 'org.apache.hadoop', name: 'hadoop-mapreduce-client-core', version: '3.2.1'
winutils
winutils是在windows平台使用hadoop的必要组件!
winutils仓库
码代码
读取HDFS中的文件
@Test
public void testProc() throws IOException {
log.info("hello lombok and hdfs");
// 设置winutils目录
System.setProperty("hadoop.home.dir", "F:\\hadoop\\hadoop-3.0.0");
// 读取hdfs中的配置文件 : org.apache.hadoop.conf.Configuration
Configuration configuration = new Configuration();
// org.apache.hadoop.hdfs.DFSUtil
configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
//设置使用hdfs分布式文件系统,指定hdfs实现类,不然将会出现访问错误
// 设置hdfs uri
configuration.set("fs.defaultFS", "hdfs://192.168.84.132:9000");
// org.apache.hadoop.fs.FileSystem 获取文件系统
org.apache.hadoop.fs.FileSystem fileSystem = org.apache.hadoop.fs.FileSystem.get(configuration);
// 读取文件 , try-with-resources 自动关闭资源
try (FSDataInputStream fsDataInputStream = fileSystem.open(new Path("/root/test/index.html"))) {
// IOUtils.copyBytes(fsDataInputStream, System.out, 4096, true); , 读取并写到控制台
IOUtils.copyBytes(fsDataInputStream, System.out, 4096, true);
}
}
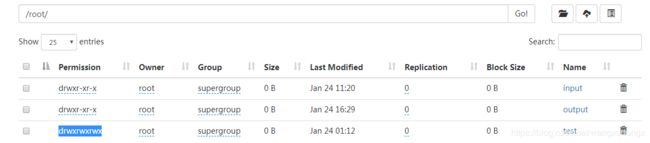
写内容到文件中
要确保将操作的目录“其它”用户有权限操作哦,可以使用hdfs dfs -chmod 777 /root/test开放某个目录的权限。
@Test
public void testProc2() throws IOException {
log.info("hello lombok and hdfs 写一些东西到hdfs文件中");
// 设置winutils目录
System.setProperty("hadoop.home.dir", "F:\\hadoop\\hadoop-3.0.0");
// 读取hdfs中的配置文件 : org.apache.hadoop.conf.Configuration
Configuration configuration = new Configuration();
configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
//设置使用hdfs分布式文件系统 设置使用hdfs分布式文件系统,指定hdfs实现类,不然将会出现访问错误
// 获取配置
configuration.set("fs.defaultFS", "hdfs://192.168.84.132:9000");
// org.apache.hadoop.fs.FileSystem
org.apache.hadoop.fs.FileSystem fileSystem = org.apache.hadoop.fs.FileSystem.get( configuration);
// 写文件 , try-with-resources 自动关闭资源
try (FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("/root/test/second.index") , false)) {
fsDataOutputStream.writeUTF("now everything is control");
fsDataOutputStream.writeUTF("now everything is control");
fsDataOutputStream.writeUTF("now everything is control");
}
}
![]()
MapReduce操作
MapReduce工作过程详解
应用程序通常实现Mapper和reduce接口来提供map和reduce方法。这些构成了工作的核心。
Mapper映射器
Input的map
Mapper将输入键/值对映射到一组中间键/值对。
映射是将输入记录转换为中间记录的单个任务。转换后的中间记录不需要与输入记录具有相同的类型。一个给定的输入对可以映射到零个或多个输出对。
Hadoop MapReduce框架为作业的InputFormat生成的每个InputSplit生成一个map任务。
总的来说,mapper实现是通过job . setmapperclass (Class)方法传递给作业的。然后,框架为该任务的InputSplit中的每个键/值对调用map(WritableComparable, Writable, Context)。然后,应用程序可以覆盖cleanup(上下文)方法来执行任何所需的清理。
map的output
输出对不需要与输入对具有相同的类型。一个给定的输入对可以映射到零个或多个输出对。通过调用context.write(WritableComparable, Writable).来收集输出对。
应用程序可以使用计数器报告其统计数据。
与给定输出键关联的所有中间值随后由框架进行分组,并传递给reducer以确定最终输出。用户可以通过Job.setGroupingComparatorClass(Class)指定一个比较器来控制分组。
对mapper输出进行排序,然后按reducer进行分区。分区的总数与任务的reduce任务数相同。用户可以通过实现自定义Partitioner来控制键(以及记录)到哪个reducer。
用户可以通过Job.setCombinerClass(Class)选择性地指定一个combiner(组合器)来执行中间输出的本地聚合,这有助于减少从mapper传输到reducer的数据量。
中间的、排序的输出总是以简单(key-len, key, value-len, value)格式存储。应用程序可以控制是否以及如何对中间输出进行压缩,并通过配置使用CompressionCodec。
map的数量
映射的数量通常由输入的总大小(即输入文件的块总数)决定。
映射的正确并行度似乎是每个节点大约10-100个映射,尽管它已经为非常轻cpu映射任务设置了300个映射。任务设置需要一段时间,所以最好是映射至少需要一分钟来执行。
因此,如果您期望10TB的输入数据,并且块大小为128MB,那么您将得到82,000个映射,除非Configuration.set(MRJobConfig.NUM_MAPS, int) (它只向框架提供一个提示)用于将其设置得更高。
Reducer
Reducer减少了一组中间值,这些中间值共享一个键到更小的一组值。
作业的reduce数量由用户通过Job.setNumReduceTasks(int)设置。
总的来说,reduce实现是通过Job. setreducerclass (Class)方法传递给作业的,并且可以覆盖它来初始化它们自己。然后,框架为分组输入中的每个
Reducer
有三个主要阶段:shuffle,sort和reduce。
shuffle
reducer的输入是经过排序的mapper的输出。在此阶段,框架通过HTTP获取所有映射器输出的相关分区。
Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据。
为什么MapReduce计算模型需要Shuffle过程?我们都知道MapReduce计算模型一般包括两个重要的阶段:Map是映射,负责数据的过滤分发;Reduce是规约,负责数据的计算归并。Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过Shuffle来获取数据。
从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。Shuffle横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和sort过程。

Sort(排序)
在这个阶段,框架根据键对减速器输入进行分组(因为不同的映射器可能输出相同的键)。
shuffle和sort阶段同时发生;当获取映射输出时,它们被合并。
二次排序
如果在约简之前需要对中间键进行分组的等价规则与对键进行分组的等价规则不同,那么可以通过Job.setSortComparatorClass(Class)指定一个比较器。由于Job.setGroupingComparatorClass(Class)可用于控制中间键的分组方式,因此可以将这些键与值结合使用来模拟次要排序。
reduce
在这个阶段,对分组输入中的每个对调用reduce (WritableComparable, Iterable, Context)方法。
reduce任务的输出通常通过上下文写入文件系统。Context.write(WritableComparable, Writable)。
应用程序可以使用计数器报告其统计数据。
reducer的输出是未排序的。
减少多少?
正确的减少数似乎是0.95或1.75乘以(
使用0.95,所有的reduce都可以立即启动,并在映射完成时开始传输映射输出。使用1.75,更快的节点将完成第一轮reduce,并启动第二轮reduce,从而更好地实现负载平衡。
增加reduce的数量会增加框架开销,但是会增加负载平衡并降低失败的成本。
上面的比例因子略小于整数,以便在框架中为推测任务和失败任务保留几个reduce槽。
Reducer NONE
如果不希望减少任务,则将减少任务的数量设置为零是合法的。
在这种情况下,map-tasks的输出直接进入FileSystem,进入FileOutputFormat.setOutputPath(Job, Path)设置的输出路径。在将映射输出写入FileSystem之前,框架不会对它们进行排序。
Partitioner
Partitioner将键空间分区。
分区程序控制中间映射输出键的分区。键(或键的子集)用于派生分区,通常由散列函数派生。分区的总数与任务的reduce任务数相同。因此,这控制了中间键(以及记录)被发送到m reduce任务中的哪个任务进行reduce。
HashPartitioner是默认的Partitioner。
Counter
Counter是MapReduce应用程序报告其统计数据的工具。
Mapper和reduce实现可以使用计数器来报告统计数据。
Hadoop MapReduce附带了一个通常有用的映射器、简化器和分区器库。
让我们先通过一个示例MapReduce应用程序来了解它们是如何工作的。
WordCount是一个简单的应用程序,它计算给定输入集中每个单词出现的次数。
这适用于本地独立、伪分布式或全分布式的Hadoop安装(单节点设置)。
码代码
package cn.MapReduce;
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 词频程序
*/
@Slf4j
public class WordCountT {
public static Text k = new Text();
public static IntWritable v = new IntWritable();
/**
* map阶段实现类
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* input中的每一行会调用一次map方法
* value是每一行的数据
* context是MapReduce的上下文
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
log.info("进入map阶段"+key);
//
// super.map(key, value, context);
// 将input文件中的一行行的数据进行处理
String line = value.toString();
String[] words = line.split(" ");
for (String word : words) {
k.set(word);
v.set(1);
// 将每一行的每一个单词放入上下文中,给reduce处理。
context.write(k,v);
}
}
}
/**
* 从map到reduce的过程中MapReduce会对数据进行一些处理,合并key,将key-value对中的value做成一个value迭代器集合
*/
/**
* reduce阶段的输入key、value类型必须要与map阶段的输出key、value类型一致
*/
public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
*
* @param key 是在map阶段处理完的数据key
* @param values 在map阶段处理完的value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
log.info("进入reduce阶段");
// super.reduce(key, values, context);
int counter = 0;
for (IntWritable value : values) {
counter += value.get();
}
log.info(" --------- key:"+key+" count:"+counter);
context.write(key ,new IntWritable(counter));
}
}
/**
* 驱动类
* @param args
* args[0] 为输入文件的路径
* args[1] 为结果输出的路径
* @throws IOException
* @throws ClassNotFoundException
* @throws InterruptedException
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// System.setProperty("hadoop.home.dir", "F:\\hadoop\\hadoop-3.0.0");
// 读取hdfs中的配置文件 : org.apache.hadoop.conf.Configuration
org.apache.hadoop.conf.Configuration configuration = new Configuration();
configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
//设置使用hdfs分布式文件系统 设置使用hdfs分布式文件系统,指定hdfs实现类,不然将会出现访问错误
// 获取配置 , 连接到hdfs
configuration.set("fs.defaultFS", "hdfs://192.168.84.132:9000");
// ========================================================
// 设置Job实例的各个参数
// job名字
Job job = Job.getInstance(configuration, "mywordcountT");
// 指定job类
job.setJarByClass(WordCountT.class);
// 指定map类
job.setMapperClass(MyMapper.class);
// 指定map输出key、value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 指定数据输入路径
org.apache.hadoop.mapreduce.lib.input.FileInputFormat.addInputPath(job,new Path(args[0]));
// 指定reduce类及输出key、value类型
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 指定输出路径
FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 等待job完成
int isok = job.waitForCompletion(true) ? 0 : 1;
log.info("词频程序运行结束。");
System.exit(isok);
}
}
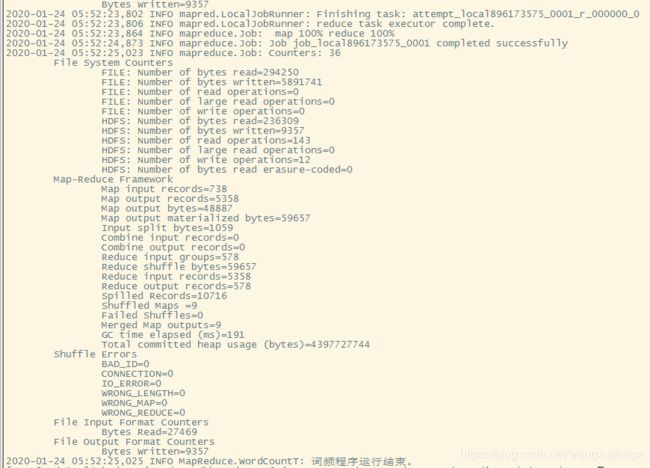
将程序放到服务器中运行
# hadoop jar /root/hhwordcount6.jar cn.MapReduce.WordCountT /root/input/ /root/output
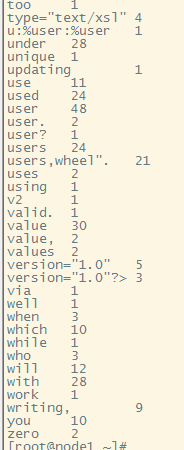
# hdfs dfs -cat /root/output/part-r-00000