pyspark-Rdd-groupby-groupByKey-cogroup-groupWith用法
一、groupBy()
groupBy(f, numPartitions=None, partitionFunc=)
Return an RDD of grouped items.
代码:
rdd=sc.parallelize([1,42,3,4,5,1,4,5,0])
res=rdd.groupBy(lambda x:x%2).collect()
print(res)

拿到迭代器的具体值:
for x,y in res:
print(x)
print(y)
print(sorted(y))
print("*"*44)

a=sorted([(x,sorted(y)) for (x,y) in res])
print(a)
a=sorted([(x,y) for (x,y) in res])
print(a)
a=[(x,sorted(y)) for (x,y) in res]
print(a)

二、groupByKey(numPartitions=None, partitionFunc=)
Group the values for each key in the RDD into a single sequence. Hash-partitions the resulting RDD with numPartitions partitions.
根据k分组
rdd=sc.parallelize([('a',1),('b',100),('a',200)])
a=rdd.groupByKey().collect()
print(a)

for i,j in a:
print(i)
print(sorted(j))

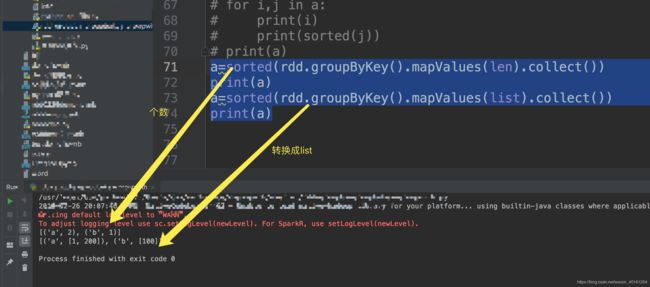
a=sorted(rdd.groupByKey().mapValues(len).collect())
print(a)
a=sorted(rdd.groupByKey().mapValues(list).collect())
print(a)
三、groupWith(other, *others)
Alias for cogroup but with support for multiple RDDs.
多个RDD group 类似cogroup
w = sc.parallelize([("a", 5), ("b", 6)])
x = sc.parallelize([("a", 1), ("b", 4)])
y = sc.parallelize([("a", 2)])
z = sc.parallelize([("b", 42)])
a=w.groupWith(x,y,z).collect()
print(a)

w = sc.parallelize([("a", 5), ("b", 6),('a',100)])
x = sc.parallelize([("a", 1), ("b", 4)])
y = sc.parallelize([("a", 2)])
z = sc.parallelize([("b", 42)])
a=w.groupWith(x,y,z).collect()
for i,j in a:
print(i)
for l in j:
print(l)
print(sorted(l))
print("*"*55)

b=[(x,tuple(map(list,y))) for x,y in sorted(list(a))]
print(b)
结果:
[('a', ([5, 100], [1], [2], [])), ('b', ([6], [4], [], [42]))]
四、cogroup(other, numPartitions=None)
For each key k in self or other, return a resulting RDD that contains a tuple with the list of values for that key in self as well as other.
x=sc.parallelize([('a',100),('b',4),('a',300)])
y=sc.parallelize([('a',65)])
a=[(x, tuple(map(list, y))) for x, y in sorted(list(x.cogroup(y).collect()))]
print(a)
结果:
[('a', ([100, 300], [65])), ('b', ([4], []))]