支持向量机(SVM) SMO算法详解
1.寻找最大间隔
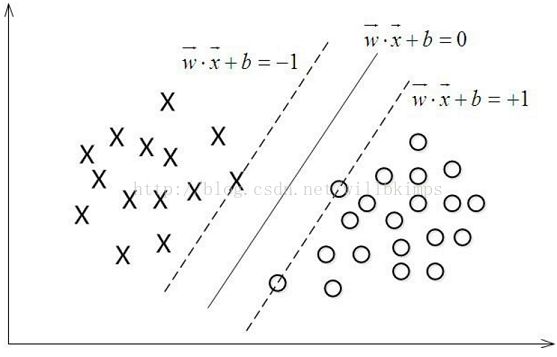
训练样本集:D = { (x1, y1) , (x2, y2) , ... ,(xm, ym) } , yi ϵ { -1, +1}
划分超平面的线性方程:wTx + b = 0(1)
样本空间中任一点x到超平面(w, b)的距离为:
 (2)
(2)
假设超平面(w, b)能将训练样本正确分类,对于(xi, yi) ϵ D, 有:
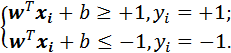 (3)
(3)
间隔为:
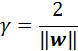 (4)
(4)
欲求最大间隔,即使得ϒ最大,等价于求解:
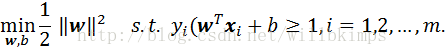 (5)
(5)
2.对偶问题
大间隔划分超平面所对应的模型为:
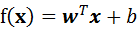 (6)
(6)
式(5)是一个凸二次规划问题,能直接用现代计算包求解,但我们有一个更高效的办法,即拉格朗日乘子法。
对式(5)使用拉格朗日乘子法得到其“对偶问题”。具体来说,对式(5)的每条约束添加拉格朗日乘子αi ≥ 0,该问题的拉格朗日函数可写为:
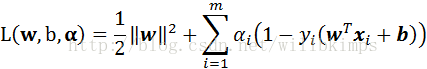 (7)
(7)
其中α = ( α1; α2; ... ; αm )。令L(w,b, α)对w和b的偏导为零可得:
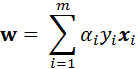 (8)
(8)
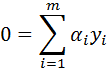 (9)
(9)
将式(8)代入式(7),即可将L(w, b, α)中的α和b消去,再考虑式(9)的约束,就得到对偶问题:
 (10)
(10)
K(xi , xj)为xi和 xj两个向量的内积。约束条件C≥αi≥0,是通过引入松弛变量,来允许有些数据点可以处于分隔面的错误一侧。
解出α后,求出w和b即可得到:
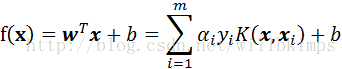 (11)
(11)
3.SMO高效优化算法
现在,我们的问题转变成求解式(10)。这是一个二次规划问题,可以使用通用的二次规划算法来求解。这里可以使用更高效的算法,SMO算法。
SMO的基本思路是先固定αi之外的所有参数,然后求αi上的极值。由于存在约束![]() ,若固定αi之外的其他参数,则αi可由其他变量导出。于是,SMO每次选择两个变量αi和αj,并固定其他参数。这样,在参数初始化后,SMO不断执行如下两个步骤直至收敛:
,若固定αi之外的其他参数,则αi可由其他变量导出。于是,SMO每次选择两个变量αi和αj,并固定其他参数。这样,在参数初始化后,SMO不断执行如下两个步骤直至收敛:
- 选取一对需要更新的变量αi和αj
- 固定αi和αj以外的参数,求解式(10)获得更新后的αi和αj
接下来介绍两个拉格朗日乘子的优化问题。
在这里我们假设正在优化的两个拉格朗日乘子对应的样本正好是第一个和第二个,两个拉格朗日乘子分别为α1和α2,他们满足的约束可以写为:
![]() (12)
(12)
其中
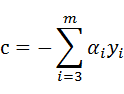 (13)
(13)
c是常量,这样就固定了αi,i≥3。我们可以用α2表示α1,这样问题就转化成为关于α2 的一元二次函数优化问题,然后对α2求极值。α2确定下来了,α1也就确定了。现在,我们先求α2 的上下限。
y1和y2 的值为+1或者-1。α1和α2 的约束条件式(12)可以用下图表示,横轴为α1,纵轴为α2:

从图中可以看出α2的约束条件:
当y1≠y2时,L=max(0, α2-α1),H=min(C, C+α2-α1 )
当y1=y2时,L=max(0, α1+α2),H=min(C, α1+α2-C)
因此有:
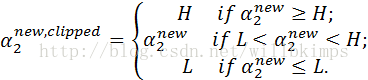
将α1和α2代入式(10),求最大值。
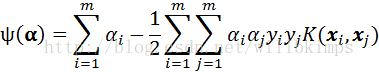
![]()

下图为αiαjyiyjK(xi, xj)的每一项,用Kij表示K(xi, xj)。

所以
![]()
![]()

 和④都是常量,因此记ψconstant =
和④都是常量,因此记ψconstant =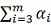 + ④
+ ④
将式(11)变形得:
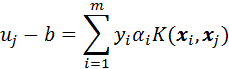
记
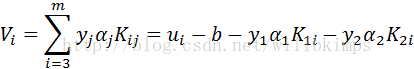
![]() ,
,![]()
因此
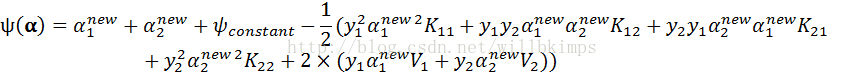

又因为

两边同时乘以y1,得
记
那么
![]()
代入ψ(α ),因此有
对α2new求偏导有:
如果二阶导数小于0,当一阶导数为0时有极大值。令上式等于0,有:
![]()
将h和Vi代入继续推导:

即有:
![]()
记
![]() ,
,![]()
有
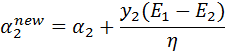
b的更新
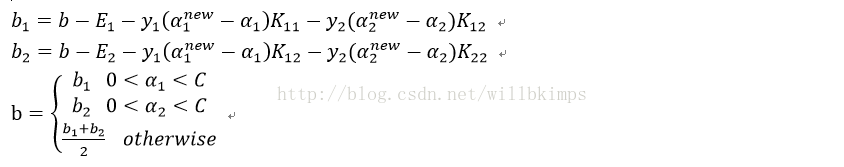
4.简化版SMO算法代码实现
SMO算法:在每次循环中选择两个合适的α进行优化处理。一旦找到一对合适的α,那么就增大其中一个同时减小另一个。SMO算法的外循环确定要优化的最佳α对。而简化版SMO代码中会跳过这一部分,首先在数据集上遍历每一个α,然后再剩下的α集合中随机选择另一个α,从而构成α对。
python代码如下:
SMO算法的辅助函数
from numpy import *
from time import sleep
#加载文本文件中的数据,返回数据矩阵和类标签
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
#随机选择不等于i的值。i是第一个α的下表,m是α的数量
def selectJrand(i,m):
j=i #we want to select any J not equal to i
while (j==i):
j = int(random.uniform(0,m))
return j
#调整大于H或小于L的α值
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
简化版SMO算法
伪代码大致如下:
创建一个α向量并向其初始化为0向量
当迭代次数小于最大迭代次数时(外循环)
对数据集中的每个数据向量(内循环):
如果该向量可以被优化:
随机选择另一个数据向量
同时优化这两个向量
如果两个向量都不能被优化,推出内循环
如果所有向量都没被优化,增加迭代次数,继续下一次循环
from numpy import *
from time import sleep
#dataMatIn, classLabels, C, toler, maxIter分别为数据集、类标签、常数C、容错率和最大迭代次数
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose()
b = 0; m,n = shape(dataMatrix)
alphas = mat(zeros((m,1)))
iter = 0
while (iter < maxIter):
alphaPairsChanged = 0
for i in range(m):
fXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b
Ei = fXi - float(labelMat[i])
#if checks if an example violates KKT conditions
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i,m)
fXj = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
Ej = fXj - float(labelMat[j])
alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy();
#将α的值调整到区间[0,C]
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L==H: print "L==H"; continue
eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T
if eta >= 0: print "eta>=0"; continue
#对αi和αj进行修改,αi的修改量和αj相同,但方向相反
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
alphas[j] = clipAlpha(alphas[j],H,L)
if (abs(alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; continue
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])#update i by the same amount as j
#the update is in the oppostie direction
#b的更新
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
if (0 < alphas[i]) and (C > alphas[i]): b = b1
elif (0 < alphas[j]) and (C > alphas[j]): b = b2
else: b = (b1 + b2)/2.0
alphaPairsChanged += 1
print "iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
if (alphaPairsChanged == 0): iter += 1
else: iter = 0
print "iteration number: %d" % iter
return b,alphas