Redis数据库学习
文章目录
- Redis是什么?它的优点有哪些?
- Redis在Java Web中的应用
- 缓存
- 高速读/写场合
- Redis基本安装和使用
- Window 下安装
- Linux 下安装
- Ubuntu 下安装
- 在Java程序中使用Redis
- 在Spring中使用Redis
- SessionCallback
- Redis的6种数据类型
- NoSQL和传统数据库有什么区别?NoSQL能取代传统数据库吗?
- Redis字符串数据结构和常用命令
- Redis哈希数据结构和常用命令
- Redis链表(linked-list)数据结构和常用命令
- Redis集合数据结构和常用命令
- Redis有序集合(sorted set)串数据结构和常用命令
- Redis HyperLogLog常用命令
- Redis的基础事务和常用操作
- 探索Redis事务回滚
- Redis watch命令——监控事务
- 使用流水线(pipelined)提高Redis的命令性能
- Redis发布订阅模式
- Redis的超时命令和垃圾回收策略
- Redis中使用Lua语言
- Redis的两种备份(持久化)方式:RDB和AOF
- Redis内存回收策略
- Redis主从复制的配置方法和执行过程
- Redis哨兵(Sentinel)模式的配置方法及其在Java中的用法
- Redis和数据库的结合
- Spring整合Redis详细步骤
- 从RedisTemplate中获得Jedis实例
- 互联网系统应用架构基础分析
- 高并发系统的分析和设计
- 有效请求和无效请求
- 系统设计
- 数据库设计
- 动静分离技术
- 锁和高并发
- 使用Redis和SSM(Spring+Spring MVC+MyBatis)搭建抢红包开发环境和超发
- Redis悲观锁解决高并发抢红包的问题
- Redis乐观锁解决高并发抢红包的问题
- 使用Redis和Lua的原子性实现抢红包功能
- Redis悲观锁、乐观锁和调用Lua脚本三种方式的优缺点
- 内容出处

Redis 是一个由 Salvatore Sanfilippo 写的 key-value 存储系统,是当前互联网世界最为流行的 NoSQL 数据库。
Redis 开源免费,提供了 Java,C/C++,C#,PHP 等客户端,使用方便。主要应用于内容缓存和处理大量数据的高访问负载。
Redis是什么?它的优点有哪些?
Redis 具备一定持久层的功能,也可以作为一种缓存工具。对于 NoSQL 数据库而言,作为持久层,它存储的数据是半结构化的,这就意味着计算机在读入内存中有更少的规则,读入速度更快。
对于那些结构化、多范式规则的数据库系统而言,它更具性能优势。作为缓存,它可以支持大数据存入内存中,只要命中率高,它就能快速响应,因为在内存中的数据读/写比数据库读/写磁盘的速度快几十到上百倍,其作用如图 1 所示。
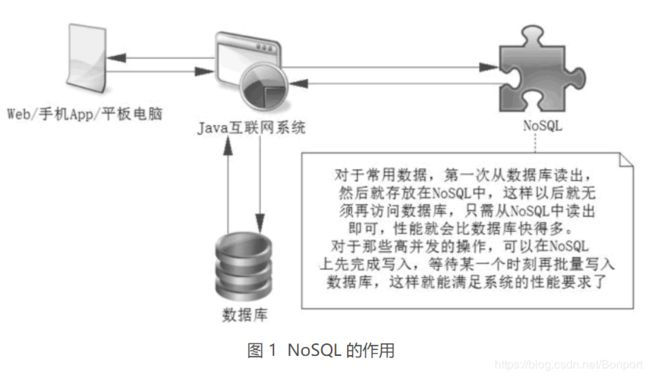
数据库系统有更好的规范性和数据完整性,功能更强大,作为持久层更为完善,安全性更高。而 NoSQL 结构松散、不完整,功能有限,目前尚不具备取代数据库的实力,但是作为缓存工具,它的高性能、高响应等功能,使它成为一个很重要的工具。
当前 Redis 已经成为了主要的 NoSQL 工具,其原因如下。
1)响应快速
Redis 响应非常快,每秒可以执行大约 110 000 个写入操作,或者 81 000 个读操作,其速度远超数据库。如果存入一些常用的数据,就能有效提高系统的性能。
2)支持 6 种数据类型
它们是字符串、哈希结构、列表、集合、可排序集合和基数。比如对于字符串可以存入一些 Java 基础数据类型,哈希可以存储对象,列表可以存储 List 对象等。这使得在应用中很容易根据自己的需要选择存储的数据类型,方便开发。
对于 Redis 而言,虽然只有 6 种数据类型,但是有两大好处:一方面可以满足存储各种数据结构体的需要;另外一方面数据类型少,使得规则就少,需要的判断和逻辑就少,这样读/写的速度就更快。
3)操作都是原子的
所有 Redis 的操作都是原子的,从而确保当两个客户同时访问 Redis 服务器时,得到的是更新后的值(最新值)。在需要高并发的场合可以考虑使用 Redis 的事务,处理一些需要锁的业务。
4)MultiUtility 工具
Redis 可以在如缓存、消息传递队列中使用(Redis 支持“发布+订阅”的消息模式),在应用程序如 Web 应用程序会话、网站页面点击数等任何短暂的数据中使用。
正是因为 Redis 具备这些优点,使得它成为了目前主流的 NoSQL 技术,在 Java 互联网中得到了广泛使用。
一方面,使用 NoSQL 从数据库中读取数据进行缓存,就可以从内存中读取数据了,而不像数据库一样读磁盘。现实是读操作远比写操作要多得多,所以缓存很多常用的数据,提高其命中率有助于整体性能的提高,并且能减缓数据库的压力,对互联网系统架构是十分有利的。
另一方面,它也能满足互联网高并发需要高速处理数据的场合,比如抢红包、商品秒杀等场景,这些场合需要高速处理,并保证并发数据安全和一致性。
Redis在Java Web中的应用
一般而言 Redis 在 Java Web 应用中存在两个主要的场景,一个是缓存常用的数据,另一个是在需要高速读/写的场合使用它快速读/写,比如一些需要进行商品抢购和抢红包的场合。
由于在高并发的情况下,需要对数据进行高速读/写的场景,一个最为核心的问题是数据一致性和访问控制。
缓存
在对数据库的读/写操作中,现实的情况是读操作的次数远超写操作,一般是 1:9 到 3:7 的比例,所以需要读的可能性是比写的可能性多得多。
当发送 SQL 去数据库进行读取时,数据库就会去磁盘把对应的数据索引回来,而索引磁盘是一个相对缓慢的过程。如果把数据直接放在运行在内存中的 Redis 服务器上,那么不需要去读/写磁盘了,而是直接读取内存,显然速度会快得多,并且会极大减轻数据库的压力。
而使用内存进行存储数据开销也是比较大的,因为磁盘可以是 TGB 级别,而且十分廉价,内存一般是几百个 GB 就相当了不起了,所以内存虽然高效但空间有限,价格也比磁盘高许多,因此使用内存代价较高,并不是想存什么就存什么,因此我们应该考虑有条件的存储数据。
一般而言,存储一些常用的数据,比如用户登录的信息;一些主要的业务信息,比如银行会存储一些客户基础信息、银行卡信息、最近交易信息等。一般而言在使用 Redis 存储的时候,需要从 3 个方面进行考虑。
- 业务数据常用吗?命中率如何?如果命中率很低,就没有必要写入缓存。
- 该业务数据是读操作多,还是写操作多,如果写操作多,频繁需要写入数据库,也没有必要使用缓存。
- 业务数据大小如何?如果要存储几百兆字节的文件,会给缓存带来很大的压力,有没有必要?
在考虑过这些问题后,如果觉得有必要使用缓存,那么就使用它。使用 Redis 作为缓存的读取逻辑如图 1 所示。
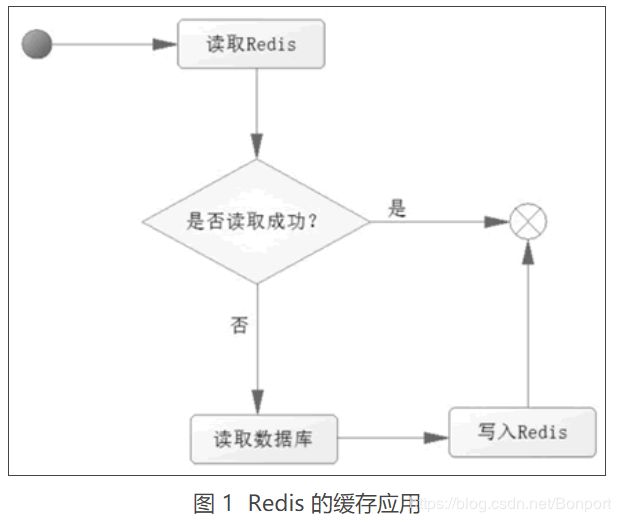
从图 1 中可以知道以下两点。
当第一次读取数据的时候,读取 Redis 的数据就会失败,此时会触发程序读取数据库,把数据读取出来,并且写入 Redis。
当第二次及以后读取数据时,就直接读取 Redis,读到数据后就结束了流程,这样速度就大大提高了。
从上面的分析可知,大部分的操作是读操作,使用 Redis 应对读操作,速度就会十分迅速,同时也降低了对数据库的依赖,大大降低了数据库的负担。
分析了读操作的逻辑后,下面再来分析写操作的流程,如图 2 所示。

从流程可以看出,更新或者写入的操作,需要多个 Redis 的操作。如果业务数据写次数远大于读次数没有必要使用 Redis。如果是读次数远大于写次数,则使用 Redis 就有其价值了,因为写入 Redis 虽然要消耗一定的代价,但是其性能良好,相对数据库而言,几乎可以忽略不计。
高速读/写场合
在互联网的应用中,往往存在一些需要高速读/写的场合,比如商品的秒杀,抢红包,淘宝、京东的双十一活动或者春运抢票等。
以上这类场合在一个瞬间成千上万的请求就会达到服务器,如果使用的是数据库,一个瞬间数据库就需要执行成千上万的 SQL,很容易造成数据库的瓶颈,严重的会导致数据库瘫痪,造成 Java Web 系统服务崩溃。
在这样的场合的应对办法往往是考虑异步写入数据库,而在高速读/写的场合中单单使用 Redis 去应对,把这些需要高速读/写的数据,缓存到 Redis 中,而在满足一定的条件下,触发这些缓存的数据写入数据库中。先看看一次请求操作的流程图,如图 3 所示。
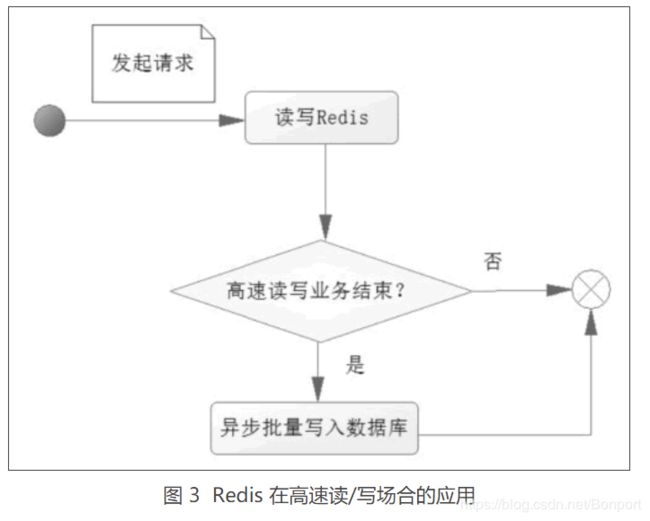
进一步论述这个过程:
当一个请求达到服务器,只是把业务数据先在 Redis 读/写,而没有进行任何对数据库的操作,换句话说系统仅仅是操作 Redis 缓存,而没有操作数据库,这个速度就比操作数据库要快得多,从而达到需要高速响应的效果。
但是一般缓存不能持久化,或者所持久化的数据不太规范,因此需要把这些数据存入数据库,所以在一个请求操作完 Redis 的读/写后,会去判断该高速读/写的业务是否结束。
这个判断的条件往往就是秒杀商品剩余个数为 0,抢红包金额为 0,如果不成立,则不会操作数据库;如果成立,则触发事件将 Redis 缓存的数据以批量的形式一次性写入数据库,从而完成持久化的工作。
假设面对的是一个商品秒杀的场景,从上面的流程看,一个用户抢购商品,绝大部分的场合都是在操作内存数据库 Redis,而不是磁盘数据库,所以其性能更为优越。只有在商品被抢购一空后才会触发系统把 Redis 缓存的数据写入数据库磁盘中,这样系统大部分的操作基于内存,就能够在秒杀的场合高速响应用户的请求,达到快速应答。
而现实中这种需要高速响应的系统会比上面的分析更复杂,因为这里没有讨论高并发下的数据安全和一致性问题,没有讨论有效请求和无效请求、事务一致性等诸多问题,这些将会在未来以独立教程讨论它。
Redis基本安装和使用
Window 下安装
下载地址:https://github.com/tporadowski/redis/releases。
Redis 支持 32 位和 64 位。这个需要根据你系统平台的实际情况选择,这里我们下载 Redis-x64-xxx.zip压缩包到 C 盘,解压后,将文件夹重新命名为 redis。

打开一个 cmd 窗口 使用 cd 命令切换目录到 C:\redis 运行:
redis-server.exe redis.windows.conf
为了方便,我们在这个目录新建一个文件 startup.cmd,用记事本或者其他文本编辑工具打开(要是打不开,可以先写入内容在重命名),然后写入以下内容。
redis-server redis.windows.conf
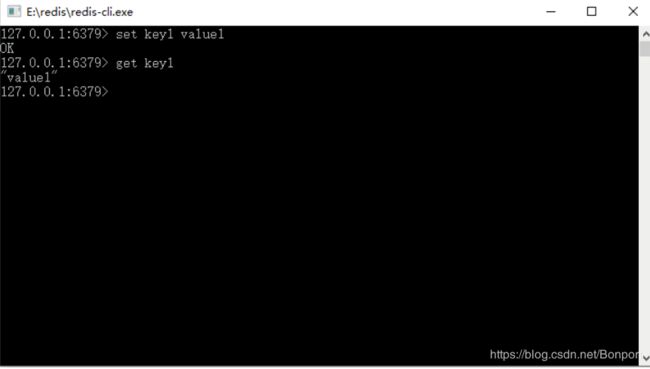
这个命令调用 redis-server.exe 的命令读取 redis.window.conf 的内容,用来启动 redis,保存好了 startup.cmd 文件,双击它就可以看到 Redis 启动的信息了,会显示如下界面:
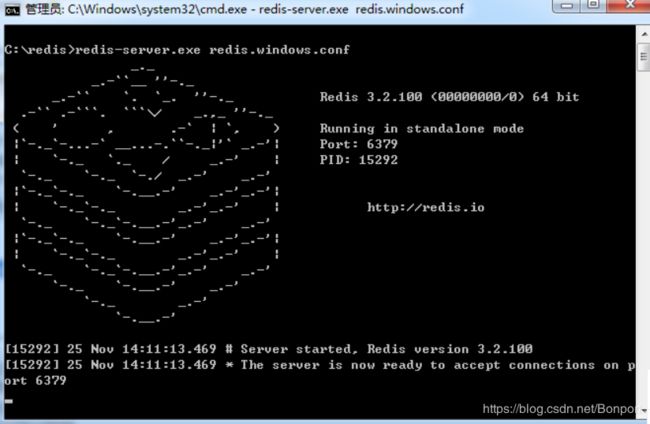
这时候另启一个 cmd 窗口,原来的不要关闭,不然就无法访问服务端了。切换到 redis 目录下运行:
redis-cli.exe -h 127.0.0.1 -p 6379
也可以双击放在同一个文件夹下的文件 redis-cli.exe,它是一个 Redis 自带的客户端工具,这样就可以连接到 Redis 服务器了,如图 所示。
Linux 下安装
下载地址:http://redis.io/download,下载最新稳定版本。
本教程使用的最新文档版本为 2.8.17,下载并安装:
$ wget http://download.redis.io/releases/redis-2.8.17.tar.gz
$ tar xzf redis-2.8.17.tar.gz
$ cd redis-2.8.17
$ make
make完后 redis-2.8.17目录下会出现编译后的redis服务程序redis-server,还有用于测试的客户端程序redis-cli,两个程序位于安装目录 src 目录下:
下面启动redis服务.
$ cd src
$ ./redis-server
注意这种方式启动redis 使用的是默认配置。也可以通过启动参数告诉redis使用指定配置文件使用下面命令启动。
$ cd src
$ ./redis-server ../redis.conf
redis.conf 是一个默认的配置文件。我们可以根据需要使用自己的配置文件。
启动redis服务进程后,就可以使用测试客户端程序redis-cli和redis服务交互了。 比如:
$ cd src
$ ./redis-cli
redis> set foo bar
OK
redis> get foo
"bar"
Ubuntu 下安装
在 Ubuntu 系统安装 Redis 可以使用以下命令:
$sudo apt-get update
$sudo apt-get install redis-server
启动 Redis
$ redis-server
查看 redis 是否启动?
$ redis-cli
以上命令将打开以下终端:
redis 127.0.0.1:6379>
127.0.0.1 是本机 IP ,6379 是 redis 服务端口。现在我们输入 PING 命令。
redis 127.0.0.1:6379> ping
PONG
以上说明我们已经成功安装了redis。
在Java程序中使用Redis
在 Java 中使用 Redis 工具,要先下载 jedis.Jar 包,把它加载到工程的路径中
<!-- redis包 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
添加到maven项目就可以了,可以使用如下代码进行测试:
package org.在Java中使用redis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* 测试redis每秒写入性能
*
*/
public class Test
{
public static void main( String[] args )
{
JedisPoolConfig poolConfig=new JedisPoolConfig();
poolConfig.setMaxIdle(50);//最大空闲数;
poolConfig.setMaxTotal(100);//最大连接数
poolConfig.setMaxWaitMillis(200000);//最大等待毫秒数
//使用连接池配置创建连接池
JedisPool jedisPool=new JedisPool(poolConfig,"localhost");
//从连接池获取单个连接
Jedis jedis=jedisPool.getResource();
//jedis.auth("password");//如果需要密码
// Jedis jedis=new Jedis("localhost",6379);//连接Redis
int i=0;
long start=System.currentTimeMillis();
while (true){
long end=System.currentTimeMillis();
if(end-start>=1000){
break;
}
i++;
jedis.set("test"+i,i+"");
}
jedis.close();
System.out.println("redis每秒操作"+i+"次");
}
}
Java Redis 的连接池提供了类 redis.clients.jedis.JedisPool 用来创建 Redis 连接池对象。使用这个对象,需要使用类 redis.clients.jedis.JedisPoolConfig 对连接池进行配置。
由于 Redis 只能提供基于字符串型的操作,而在 Java 中使用的却以类对象为主,所以需要 Redis 存储的字符串和 Java 对象相互转换。
如果自己编写这些规则,工作量还是比较大的,比如一个角色对象,我们没有办法直接把对象存入 Redis 中,需要进一步进行转换,所以对操作对象而言,使用 Redis 还是比较难的。
好在 Spring 对这些进行了封装和支持,它提供了序列化的设计框架和一些序列化的类,使用后它可以通过序列化把 Java 对象转换,使得 Redis 能把它存储起来。
并且在读取的时候,再把由序列化过的字符串转化为 Java 对象,这样在 Java 环境中使用 Redis 就更加简单了,所以更多的时候可以使用 Spring 提供的 RedisTemplate 的机制来使用 Redis。
在Spring中使用Redis
在 Spring 中使用 Redis,除了需要 jedis.jar 外,还需要下载 spring-data-redis.jar,这里值得注意的是 jar 包和 Spring 版本兼容的问题。
<!-- redis包 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<!-- 使用 Spring 提供的 RedisTemplate 操作 Redis -->
<!--spring-data-redis跟jedis版本要对应-->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
<version>1.6.2.RELEASE</version>
</dependency>
完整的pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>Redis_stu</artifactId>
<version>1.0-SNAPSHOT</version>
<name>Redis_stu</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!-- redis包 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<!-- 使用 Spring 提供的 RedisTemplate 操作 Redis -->
<!--spring-data-redis跟jedis版本要对应-->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
<version>1.6.2.RELEASE</version>
</dependency>
<!--4:spring依赖-->
<!--1)spring核心依赖-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>4.1.7.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>4.1.7.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.1.7.RELEASE</version>
</dependency>
<!--2)spring dao层依赖-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>4.1.7.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>4.1.7.RELEASE</version>
</dependency>
<!--3)springweb相关依赖-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>4.1.7.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>4.1.7.RELEASE</version>
</dependency>
<!--4)spring test相关依赖-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>4.1.7.RELEASE</version>
</dependency>
</dependencies>
<build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle -->
<plugin>
<artifactId>maven-clean-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging -->
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.1</version>
</plugin>
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-install-plugin</artifactId>
<version>2.5.2</version>
</plugin>
<plugin>
<artifactId>maven-deploy-plugin</artifactId>
<version>2.8.2</version>
</plugin>
<!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle -->
<plugin>
<artifactId>maven-site-plugin</artifactId>
<version>3.7.1</version>
</plugin>
<plugin>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
在大部分情况下我们都会用到连接池,于是先用 Spring 配置一个 JedisPoolConfig 对象,这个配置相对而言比较简单,使用 Spring 配置 JedisPoolConfig 对象代码如下所示。
<bean id="poolConfig" class="redis.clients.jedis.JedisPoolConfig">
<!-- 最大空闲数 -->
<property name="maxIdle" value="50" />
<!-- 最大连接数 -->
<property name="maxTotal" value="100" />
<!-- 最大等待时间 -->
<property name="maxWaitMillis" value="20000" />
</bean>
这样就设置了一个连接池的配置,继续往下配置。
在使用 Spring 提供的 RedisTemplate 之前需要配置 Spring 所提供的连接工厂,在 Spring Data Redis 方案中它提供了 4 种工厂模型。
- JredisConnectionFactory。
- JedisConnectionFactory。
- LettuceConnectionFactory。
- SrpConnectionFactory。
虽然使用哪种实现工厂都是可以的,但是要根据环境进行测试,以验证使用哪个方案的性能是最佳的。无论如何它们都是接口 RedisConnectionFactory 的实现类,更多的时候我们都是通过接口定义去理解它们,所以它们是具有接口适用性特性的。本教程将以使用最为广泛的 JedisConnectionFactory 为例进行讲解。
例如,在 Spring 中配置一个 JedisConnectionFactory 对象,配置 JedisConnectionFactory 代码如下所示。
<bean id="connectionFactory"
class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory">
<property name="hostName" value="localhost" />
<property name="port" value="6379" />
<!--<property name="password" value="password"/> -->
<property name="poolConfig" ref="poolConfig" />
</bean>
解释一下它的属性配置。
- hostName,代表的是服务器,默认值是 localhost,所以如果是本机可以不配置它。
- port,代表的是接口端口,默认值是 6379,所以可以使用默认的 Redis 端口,也可以不配置它。
- password,代表的是密码,在需要密码连接 Redis 的场合需要配置它。
- poolConfig,是连接池配置对象,可以设置连接池的属性。
这样就完成了一个 Redis 连接工厂的配置。这里配置的是 JedisConnectionFactory,如果需要的是 LettuceConnectionFactory,可以把使用 Spring 配置 JedisPoolConfig 对象代码中的 Bean 元素的 class 属性修改为 org.springframework.data.redis.connection.lettuce.LettuceConnectionFactor 即可,这取决于项目的需要和特殊性。有了 RedisConnectionFactory 工厂,就可以使用 RedisTemplate 了。
普通的连接使用没有办法把 Java 对象直接存入 Redis,而需要我们自己提供方案,这时往往就是将对象序列化,然后使用 Redis 进行存储,而取回序列化的内容后,在通过转换转变为 Java 对象,Spring 模板中提供了封装的方案,在它内部提供了 RedisSerializer 接口(org.springframework.data.redis.serializer.RedisSerializer)和一些实现类,其原理如图 1 所示。
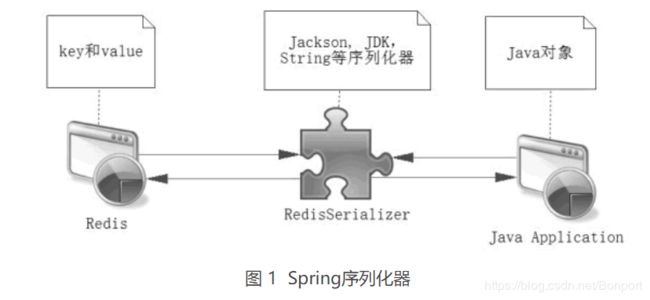
可以选择 Spring 提供的方案去处理序列化,当然也可以去实现在 spring data redis 中定义的 RedisSerializer 接口,在 Spring 中提供了以下几种实现 RedisSerializer 接口的序列化器。
- GenericJackson2JsonRedisSerializer,通用的使用 Json2.jar 的包,将 Redis 对象的序列化器。
- Jackson2JsonRedisSerializer,通过 Jackson2.jar 包提供的序列化进行转换(由于版本太旧,Spring 不推荐使用)。
- JdkSerializationRedisSerializer,使用 JDK 的序列化器进行转化。
- OxmSerializer,使用 Spring O/X 对象 Object 和 XML 相互转换。
- StringRedisSerializer,使用字符串进行序列化。
- GenericToStringSerializer,通过通用的字符串序列化进行相互转换。
使用它们就能够帮助我们把对象通过序列化存储到 Redis 中,也可以把 Redis 存储的内容转换为 Java 对象,为此 Spring 提供的 RedisTemplate 还有两个属性。
- keySerializer——键序列器。
- valueSerializer——值序列器。
有了上面的了解,就可以配置 RedisTemplate 了。假设选用 StringRedisSerializer 作为 Redis 的 key 的序列化器,而使用 JdkSerializationRedisSerializer 作为其 value 的序列化器,则可以以下代码的方法来配置 RedisTemplate。
spring-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!--用 Spring 配置一个 JedisPoolConfig 对象-->
<bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig">
<property name="maxIdle" value="50"/><!--最大空闲-->
<property name="maxTotal" value="100"/><!--最大连接-->
<property name="maxWaitMillis" value="20000"/>
</bean>
<!--使用 Spring 提供的 RedisTemplate 之前需要配置 Spring 所提供的连接工厂-->
<bean id="connectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory">
<property name="hostName" value="localhost"/>
<property name="port" value="6379"/>
<property name="poolConfig" ref="jedisPoolConfig"/>
</bean>
<!--选用 StringRedisSerializer 作为 Redis 的 key 的序列化器,
而使用 JdkSerializationRedisSerializer 作为其 value 的序列化器,则可以以下代码的方法来配置 RedisTemplate-->
<bean id="jdkSerializationRedisSerializer"
class="org.springframework.data.redis.serializer.JdkSerializationRedisSerializer"/>
<bean id="stringRedisSerializer"
class="org.springframework.data.redis.serializer.StringRedisSerializer"/>
<bean id="redisTemplate" class="org.springframework.data.redis.core.RedisTemplate">
<property name="connectionFactory" ref="connectionFactory"/>
<property name="keySerializer" ref="stringRedisSerializer"/>
<property name="valueSerializer" ref="jdkSerializationRedisSerializer"/>
</bean>
</beans>
这样就配置了一个 RedisTemplate 的对象,并且 spring data redis 知道会用对应的序列化器去转换 Redis 的键值。
举个例子,新建一个角色对象,使用 Redis 保存它的对象,使用 Redis 保存角色类对象如下所示。
package spring提供redisTemplate使用redis;
import java.io.Serializable;
public class Role implements Serializable {
/**
* 注意,对象要可序列化,需要实现Serializable接口,往往要重写serialVersionUID
*/
public static final long serialVersionUID=1L;
private long id;
private String roleName;
private String note;
@Override
public String toString() {
return "Role{" +
"id=" + id +
", roleName='" + roleName + '\'' +
", note='" + note + '\'' +
'}';
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getRoleName() {
return roleName;
}
public void setRoleName(String roleName) {
this.roleName = roleName;
}
public String getNote() {
return note;
}
public void setNote(String note) {
this.note = note;
}
}
因为要序列化对象,所以需要实现 Serializable 接口,表明它能够序列化,而 serialVersionUID 代表的是序列化的版本编号。
接下来就可以测试保存这个 Role 对象了,测试代码如下所示。
package spring提供redisTemplate使用redis;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.data.redis.core.RedisTemplate;
public class Test {
public static void main(String[] args) {
ApplicationContext applicationContext=new ClassPathXmlApplicationContext("spring-config.xml");
RedisTemplate redisTemplate = (RedisTemplate) applicationContext.getBean("redisTemplate");
Role role=new Role();
role.setId(1L);
role.setRoleName("name_1");
role.setNote("note_1");
redisTemplate.opsForValue().set("role_1", role);
Role role_1 = (Role) redisTemplate.opsForValue().get("role_1");
System.out.println(role_1.toString());
}
}
测试结果
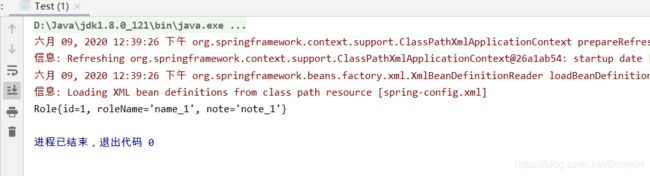
显然这里已经成功保存和获取了一个 Java 对象,这段代码演示的是如何使用 StringRedisSerializer 序列化 Redis 的 key,而使用 JdkSerializationRedisSerializer 序列化 Redis 的value,当然也可以根据需要去选择,甚至是自定义序列化器。
SessionCallback
注意,以上的使用都是基于 RedisTemplate、基于连接池的操作,换句话说,并不能保证每次使用 RedisTemplate 是操作同一个对 Redis 的连接,比如上面代码中的下面两行代码。set 和 get 方法看起来很简单,它可能就来自于同一个 Redis 连接池的不同 Redis 的连接。
为了使得所有的操作都来自于同一个连接,可以使用 SessionCallback 或者 RedisCallback 这两个接口,而 RedisCallback 是比较底层的封装,其使用不是很友好,所以更多的时候会使用 SessionCallback 这个接口,通过这个接口就可以把多个命令放入到同一个 Redis 连接中去执行,代码如下所示,它主要是实现了上面代码中的功能。
public static void main(String[] args) {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring-config.xml");
RedisTemplate<String,Role> redisTemplate= applicationContext.getBean(RedisTemplate.class);
final Role role=new Role();
role.setId(1L);
role.setRoleName("name_2");
role.setNote("note_2");
SessionCallback<Role> sessionCallback = new SessionCallback<Role>() {
@Override
public Role execute(RedisOperations redisOperations) throws DataAccessException {
redisOperations.boundValueOps("role_2").set(role);
return (Role) redisOperations.boundValueOps("role_2").get();
}
};
Role savedRole = redisTemplate.execute(sessionCallback);
System.out.println(savedRole.toString());
}
这样 set 和 get 命令就能够保证在同一个连接池的同一个 Redis 连接进行操作,这里向读者展示的是使用匿名类的形式,而事实上如果采用 Java 8 的 JDK 版本,也可以使用 Lambda 表达式进行编写 SessionCallback 的业务逻辑,这样逻辑会更为清晰明了。由于前后使用的都是同一个连接,因此对于资源损耗就比较小,在使用 Redis 操作多个命令或者使用事务时也会常常用到它。
Redis的6种数据类型
NoSQL和传统数据库有什么区别?NoSQL能取代传统数据库吗?
Redis字符串数据结构和常用命令
Redis哈希数据结构和常用命令
Redis链表(linked-list)数据结构和常用命令
Redis集合数据结构和常用命令
Redis有序集合(sorted set)串数据结构和常用命令
Redis HyperLogLog常用命令
Redis的基础事务和常用操作
探索Redis事务回滚
Redis watch命令——监控事务
使用流水线(pipelined)提高Redis的命令性能
Redis发布订阅模式
Redis的超时命令和垃圾回收策略
Redis中使用Lua语言
Redis的两种备份(持久化)方式:RDB和AOF
Redis内存回收策略
Redis主从复制的配置方法和执行过程
Redis哨兵(Sentinel)模式的配置方法及其在Java中的用法
Redis和数据库的结合
Spring整合Redis详细步骤
从RedisTemplate中获得Jedis实例
互联网系统应用架构基础分析
在互联网系统中包含许多的工具,每个企业都有自己的架构,正如没有完美的程序一样,也不会有完美的架构。本节分析的架构严格来说并不严谨,但是却包含了互联网的思想,互联网架构如图 1 所示。
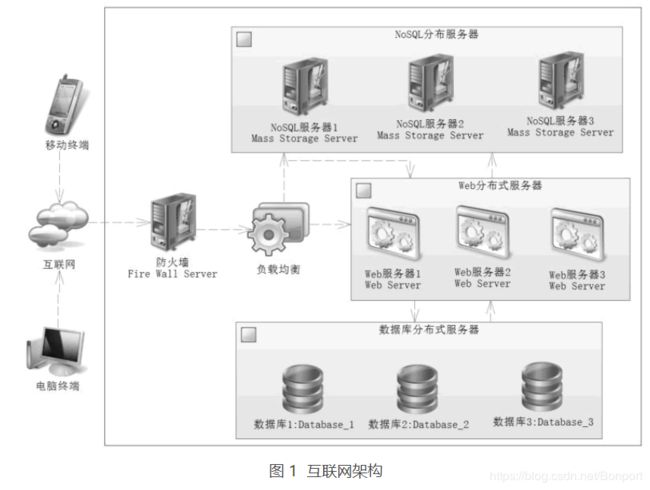
这不是一个严谨的架构,但是它包含了互联网的许多特性。对于防火墙,无非是防止互联网上的病毒和其他攻击,正常的请求通过防火墙后,最先到达的就是负载均衡器,这是关注的核心。
负载均衡器有以下几个功能:
1)对业务请求做初步的分析,决定分不分发请求到 Web 服务器,这就好比一个把控的关卡,常见的分发软件比如 Nginx 和 Apache 等反向代理服务器,它们在关卡处可以通过配置禁止一些无效的请求。
比如封禁经常作弊的 IP 地址,也可以使用 Lua、C 语言联合 NoSQL 缓存技术进行业务分析,这样就可以初步分析业务,决定是否需要分发到服务器。
2)提供路由算法,它可以提供一些负载均衡的算法,根据各个服务器的负载能力进行合理分发,每一个 Web 服务器得到比较均衡的请求,从而降低单个服务器的压力,提高系统的响应能力。
3)限流,对于一些高并发时刻,如双十一、新产品上线,需要通过限流来处理,因为可能某个时刻通过上述的算法让有效请求过多到达服务器,使得一些 Web 服务器或者数据库服务器产生宕机。
当某台机器宕机后,会使得其他服务器承受更大的请求量,这样就容易产生多台服务器连续宕机的可能性,持续下去就会引发服务器雪崩。
因此在这种情况下,负载均衡器有限流的算法,对于请求过多的时刻,可以告知用户系统繁忙,稍后再试,从而保证系统持续可用。
如果顺利通过了防火墙和负载均衡器的请求,那么负载均衡器就会通过设置的算法进行计算后,将请求分发到某一台 Web 服务器上,由 Web 服务器通过分布式的 NoSQL 和数据库提供服务,这样就能够高效响应客户端的请求了。
从上面的分析可以知道,系统完全可以在负载均衡器中进行初步鉴别业务请求,使得一些不合理的业务请求在进入 Web 服务器之前就被排除掉,而为了应对复杂的业务,可以把业务存储在 NoSQL(往往是 Redis)上,通过 C 语言或者 Lua 语言进行逻辑判断,它们的性能比 Web 服务器判断的性能要快速得多。
通过这些简单的判断就能够快速发现无效请求,并把它们排除在 Web 服务器之外,从而降低 Web 服务器的压力,提高互联网系统的响应速度,不过在进一步分析之前,我们还要鉴别无效请求,教程后面会讨论有效请求和无效请求。
高并发系统的分析和设计
任何系统都不是独立于业务进行开发的,真正的系统是为了实现业务而开发的,所以开发高并发网站抢购时,都应该先分析业务需求和实际的场景,在完善这些需求之后才能进入系统开发阶段。
没有对业务进行分析就贸然开发系统是开发者的大忌。对于业务分析,首先是有效请求和无效请求,有效请求是指真实的需求,而无效请求则是虚假的抢购请求。
有效请求和无效请求
无效请求有很多种类,比如通过脚本连续刷新网站首页,使得网站频繁访问数据库和其他资源,造成性能持续下降,还有一些为了得到抢购商品,使用刷票软件连续请求的行为。
鉴别有效请求和无效请求是获取有效请求的高并发网站业务分析的第一步,我们现在来分析哪些是无效请求的场景,以及应对方法。
首先,一个账号连续请求,对于一些懂技术或者使用作弊软件的用户,可以使用软件对请求的服务接口连续请求,使得后台压力变大,甚至在一秒内发送成百上千个请求到服务器。
这样的请求显然可以认为是无效请求,应对它的方法很多,常见的做法是加入验证码。一般而言,首次无验证码以便用户减少录入,第二次请求开始加入验证码,可以是图片验证码、等式运算等。
使用图片验证码可能存在识别图片作弊软件的攻击,所以在一些互联网网站中,图片验证码还会被加工成为东倒西歪的形式,这样增加了图片识别作弊软件的辨别难度,以压制作弊软件的使用。简单的等式运算,也会使图片识别作弊软件更加难以辨认。
其次,使用短信服务,把验证码发送到短信平台以规避部分作弊软件。
在企业应用中,这类问题的逻辑判断,不应该放在Web服务器中实现,而应放在负载均衡器上完成,即在进入 Web 服务器之前完成,做完这一步就能避免大量的无效请求,对保证高并发服务器可用性很有效果。
仅仅做这一步或许还不够,毕竟验证码或许还有其他作弊软件可以快速读取图片或者短信信息,从而发送大量的请求。进一步的限制请求,比如限制用户在单位时间的购买次数以压制其请求量,使得这些请求排除在服务器之外。判断验证码逻辑,如图 1 所示。
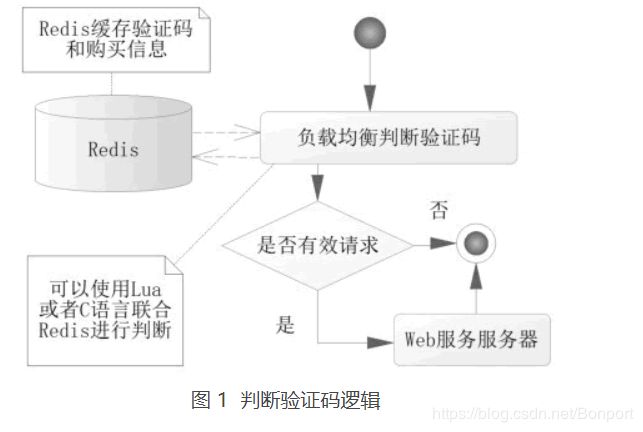
这里的判断是在负载均衡转发给 Web 服务器前,对验证码和单位时间单个账号请求数量进行判断。这里使用了 C 语言和 Redis 进行判断,那么显然这套方案会比 Java 语言和数据库机制的性能要高得多,通过这套体系,基本能够压制一个用户对系统的作弊,也提高了整个系统验证的性能。
这是对一个账号连续无效请求的压制,有时候有些用户可能申请多个账号来迷惑服务器,使得他可以避开对单个账户的验证,从而获得更多的服务器资源。
一个人多个账户的场景还是比较好应付的,可以通过提高账户的等级来压制多个请求,比如对于支付交易的网站,可以通过银行卡验证,实名制获取相关证件号码,从而使用证件号码使得多个账户归结为一人,通过这层关系来屏蔽多个账号的频繁请求,这样就有效地规避了一个人多个账号的频繁请求。
对于有组织的请求,则不是那么容易了,因为对于一些黄牛组织,可能通过多人的账号来发送请求,统一组织伪造有效请求,如图 2 所示。
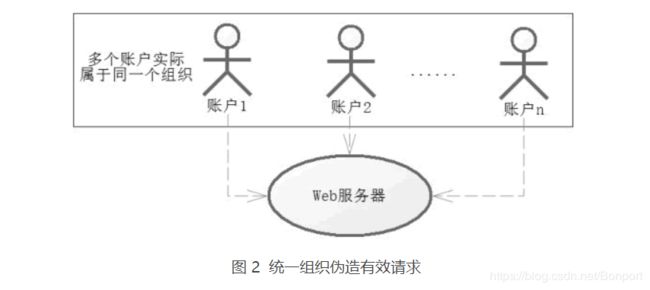
对于这样的请求,我们会考虑使用僵尸账号排除法对可交易的账号进行排除,所谓僵尸账号,是指那些平时没有任何交易的账号,只是在特殊的日子交易,比如春运期间进行大批量抢购的账号。
当请求达到服务器,我们通过僵尸账号,排除掉一些无效请求。当然还能使用 IP 封禁,尤其是通过同一 IP 或者网段频繁请求的,但是这样也许会误伤有效请求,所以使用 IP 封禁还是要慎重一些。
系统设计
高并发系统往往需要分布式的系统分摊请求的压力,这就需要使用负载均衡服务了,它进行简易判断后就会分发到具体 Web 服务器。
我们要尽量根据 Web 服务器的性能进行均衡分配请求,使得单个 Web 服务器压力不至于过大,导致服务瘫痪,这可以参考 Nginx 的请求分发,这样使得请求能够均衡发布到服务器中去,服务器可以按业务划分。
比如当前的购买分为产品维护、交易维护、资金维护、报表统计和用户维护等模块,按照功能模块进行区分,使得它们相互隔离,就可以降低数据的复杂性,图 3 就是一种典型的按业务划分,或者称为水平分法。
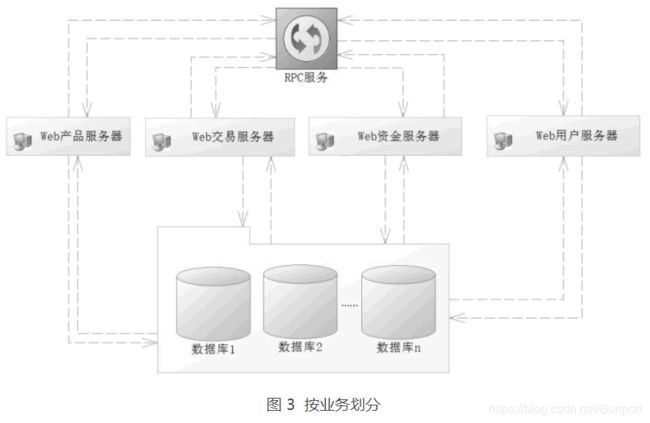
按照业务划分的好处是:首先,一个服务管理一种业务,业务简单了,提高了开发效率,其次,数据库的设计也方便许多,毕竟各管各的东西。
但是,这也会带来很多麻烦,比如由于各个系统业务存在着关联,还要通过 RPC(Remote Procedure Call Protoco,远程过程调用协议)处理这些关联信息。
比较流行的 RPC 有 Dubbo、Thrift 和 Hessian 等。其原理是,每一个服务都会暴露一些公共的接口给 RPC 服务,这样对于任何一个服务器都能够通过 RPC 服务获取其他服务器对应的接口去调度各个服务器的逻辑来完成功能,但是接口的相互调用也会造成一定的缓慢。
有了水平分法也会有垂直分法,所谓垂直分法就是将一个很大的请求量,不按子系统分,而是将它们按照互不相干的几个同样的系统分摊下去。
比如一台服务器的最大负荷为每秒 1 万个请求,而测得系统高峰为每秒 2 万个请求,如果我们把各个请求按照一定的算法合理分配到 4 台服务器上,那么 4 台服务器平均 5 千个请求就属于正常服务了,这样的路由算法被称为垂直分法,如图 4 所示。
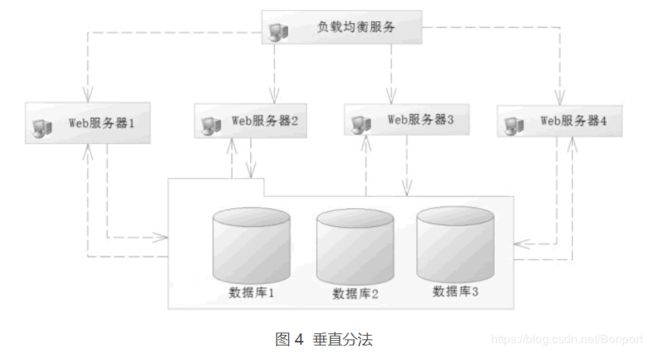
垂直分法不按业务分,对于负载均衡器的算法往往可以通过用户编号把路由分发到对应的服务器上。
每一个服务器处理自己独立的业务,互不干扰,但是每一个服务器都包含所有的业务逻辑功能,会造成开发上的业务困难,对于数据库设计而言也是如此。
对于大型网站还会有更细的分法,比如水平和垂直结合的分法,如图 5 所示。
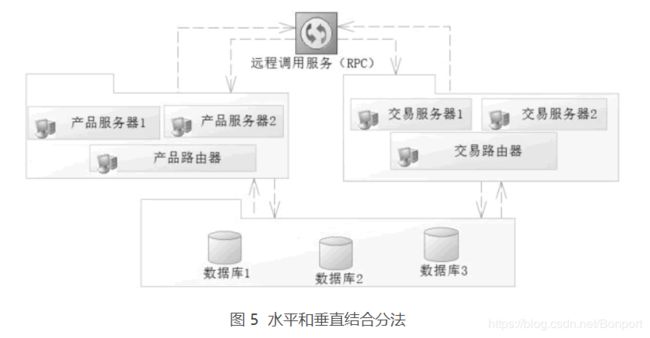
首先将系统按照业务区分为多个子系统,然后在每一个子系统下再分多个服务器,通过每一个子系统的路由器找到对应的子系统服务器提供服务。
分法是多样性的,每一个企业都会根据自己的需要而进行不同的设计,但是无论系统如何分,秉承的原则是不变的。
首先,服务器的负载均衡,要使得每一个服务器都能比较平均地得到请求数量,从而提高系统的吞吐和性能。其次,业务简化,按照模块划分可以使得系统划分为各个子系统,这样开发者的业务单一化,就更容易理解和开发了。
数据库设计
对于数据库的设计而言,为了得到高性能,可以使用分表或分库技术,从而提高系统的响应能力。
分表是指在一个数据库内本来一张表可以保存的数据,设计成多张表去保存,比如交易表 t_transaction。
由于存储数据多会造成查询和统计的缓慢,这个时候可以使用多个表存储,比如 2016 年的数据用表 t_transaction_2016 存储,2017 年的数据使用表 t_transaction_2017 存储,2018 年的数据则用表 t_transaction_2018 存储,依此类推,开发者只要根据查询的年份确定需要查找哪张表就可以了,如图 6 所示。

分库则不一样,它把表数据分配在不同的数据库中,比如上述的交易表 t_transaction 可以存放在多个数据库中,如图 7 所示。
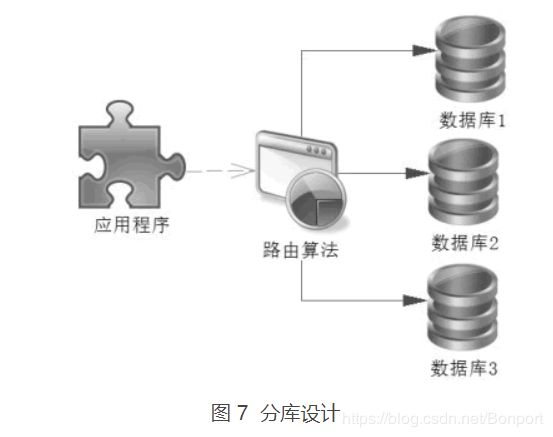
分库数据库首先需要一个路由算法确定数据在哪个数据库上,然后才能进行查询,比如我们可以把用户和对应业务的数据库的信息缓存到 Redis 中,这样路由算法就可以通过 Redis 读取的数据来决定使用哪个数据库进行查询了。
一些会员很多的网站还可以区分活跃会员和非活跃会员。活跃会员可以通过数据迁徙的手段,也就是先记录在某个时间段(比如一个月的月底)会员的活跃度,然后通过数据迁徙,将活跃会员较平均分摊到各个数据库中,以避免某个库过多的集中活跃会员,而导致个别数据库被访问过多,从而达到数据库的负载均衡。
做完这些还可以考虑优化 SQL,建立索引等优化,提高数据库的性能。性能低下的 SQL 对于高并发网站的影响是很大的,这些对开发者提出了更高的要求。
在开发网站中使用更新语句和复杂查询语句要时刻记住更新是表锁定还是行锁定,比如 id 是主键,而 user_name 是用户名称,也是唯一索引,更新用户的生日,可以使用以下两条SQL中的任何一条:
update t_user set birthday = #{birthday} where id = #{id};
update t_user set birthday = #{birthday} where user_name = #{userName};
上述逻辑都是正确的,但是优选使用主键更新,其原因是在 MySQL 的运行过程中,第二句 SQL 会锁表,即不仅锁定更新的数据,而且锁定其他表的数据,从而影响并发,而使用主键的更新则是行锁定。
对于 SQL 的优化还有很多细节,比如可以使用连接查询代替子查询。查询一个没有分配角色的用户 id,可能有人使用这样的一个 SQL:
select u.id from t_user u
where u.id not in (select ur.user_id from t_user_role ur);
这是一个 not in 语句,性能低下,对于这样的 not in 和 not exists 语句,应该全部修改为连接语句去执行,从而极大地提高 SQL 的性能,比如这条 not in 语句可以修改为:
select u.id from t_user u left join t_user_role ur
on u.id = ur.user_id
where ur.user_id is null;
not in 语句消失了,使用了连接查询,大大提高了 SQL 的执行性能。
此外还可以通过读/写分离等技术,进行进一步的优化,这样就可以有一台主机主要负责写业务,一台或者多台备机负责读业务,有助于性能的提高。
对于分布式数据库而言,还会有另外一个麻烦,就是事务的一致性,事务的一致性比较复杂,目前流行的有两段提交协议,即 XA 协议、Paxos 协议。
动静分离技术
动静分离技术是目前互联网的主流技术,对于互联网而言大部分数据都是静态数据,只有少数使用动态数据,动态数据的数据包很小,不会造成网络瓶颈。
而静态的数据则不一样,静态数据包含图片、CSS(样式)、JavaScript(脚本)和视频等互联网的应用,尤其是图片和视频占据的流量很大,如果都从动态服务器(比如 Tomcat、WildFly 和 WebLogic 等)获取,那么动态服务器的带宽压力会很大,这个时候应该考虑使用动静分离技术。
对于一些有条件的企业也可以考虑使用 CDN(Content Delivery Network,即内容分发网络)技术,它允许企业将自己的静态数据缓存到网络 CDN 的节点中。比如企业将数据缓存在北京的节点上,当在天津的客户发送请求时,通过一定的算法,会找到北京 CDN 节点,从而把 CDN 缓存的数据发送给天津的客户,完成请求。
对于深圳的客户,如果企业将数据缓存到广州 CDN 节点上,那么它也可以从广州的 CDN 节点上取出数据,由于就近取出缓存节点的数据,所以速度会很快,如图 8 所示。

一些企业也许需要自己的静态 HTTP 服务器,将静态数据分离到静态 HTTP 服务器上。其原理大同小异,就是将资源分配到静态服务器上,这样图片、HTML、脚本等资源都可以从静态服务器上获取,尽量使用 Cookie 等技术,让客户端缓存能够缓存数据,避免多次请求,降低服务器的压力。
对于动态数据,则需要根据会员登录来获取后台数据,这样的动态数据是高并发网站关注的重点。
锁和高并发
无论区分有效请求和无效请求,水平划分和垂直划分,动静分离技术,还是数据库分表、分库等技术的应用,都无法避免动态数据,而动态数据的请求最终也会落在一台 Web 服务器上。
对于一台 Web 服务器而言,如果是 Java 服务器,它极有可能采用 SSM 框架结合数据库和 Redis 等技术提供服务,那么它会面临何种困难呢?高并发系统存在的一个麻烦是并发数据不一致问题。
以抢红包为例,发放了一个总额为 20 万元的红包,它可以拆分为 2 万个可抢的小红包。假设每个小红包都是 10 元,供给网站会员抢夺,网站同时存在 3 万会员在线抢夺,这就是一个典型的高并发的场景。
以上会出现多个线程同时享有大红包数据的场景,在高并发的场景中,由于线程每一步完成的顺序不一样,这样会导致数据的一致性问题,比如在最后的一个红包,就可能出现如表 1 所示的场景。
注意表 1 中加粗的文字,由此可见,在高并发的场景下可能出现错扣红包的情况,这样就会导致数据错误。由于在一个瞬间产生很高的并发,因此除了保证数据一致性,我们还要尽可能地保证系统的性能,加锁会影响并发,而不加锁就难以保证数据的一致性,这就是高并发和锁的矛盾。

为了解决这对矛盾,在当前互联网系统中,大部分企业提出了悲观锁和乐观锁的概念,而对于数据库而言,如果在那么短的时间内需要执行大量 SQL,对于服务器的压力可想而知,需要优化数据库的表设计、索引、SQL 语句等。
有些企业提出了使用 Redis 事务和 Lua 语言所提供的原子性来取代现有的数据库的技术,从而提高数据的存储响应,以应对高并发场景,严格来说它也属于乐观锁的概念。教程后面会讨论关于数据不一致的方案,悲观锁、乐观锁和 Redis 实现的场景。
使用Redis和SSM(Spring+Spring MVC+MyBatis)搭建抢红包开发环境和超发
Redis悲观锁解决高并发抢红包的问题
Redis乐观锁解决高并发抢红包的问题
使用Redis和Lua的原子性实现抢红包功能
Redis悲观锁、乐观锁和调用Lua脚本三种方式的优缺点
内容出处
http://c.biancheng.net/