大数据
大数据
- 一、大数据概述
- 0. 背景
- 1. 定义
- 2. 数据结构
- 3. 特征4V
- 4. 挑战
- 5. 解决
- 二、电信大数据应用
- 1. 挑战
- 2. 大数据的总体目标
- 三、应用场景
- 场景一、潜在离网用户维挽场景
- 场景二、综合网管分析平台-基站关联分析场景
- 场景三、数据变现场景:户外数字媒体/非数字媒体价值评估场景
- 四、企业级大数据平台架构
- 1. 总体介绍
- 2. 关键技术
- 3. 运营流程
- 五、Hadoop基础技术
- 1. 大数据处理技术发展趋势
- 2. 大数据主要存储技术
- 3. Hadoop典型应用场景
- 六、数据分析与数据挖掘基础
- 1. 数据挖掘背景
- 2. 数据挖掘常见算法
- 3. 数据挖掘建模方法论
一、大数据概述
0. 背景
基于海量数据的存储与处理面临挑战,TB级到PB级;
行业技术标准的日益形成,Hadoop;
趋势:
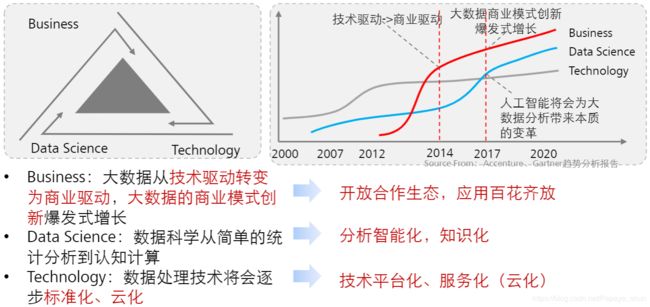
发展趋势:云计算(服务化)–> 大数据(管道化)–> AI(智能化)
1. 定义
指无法在可承受的时间内用软硬件进行捕捉、管理和处理的数据集合,需要新处理模式才能该数据集合成具有更强的决策力、洞察力和流程优化等能力的海量、多样化的信息资产。
关键:预测。
2. 数据结构
非结构化(音视频、文档)、结构化数据(可以存储在关系型数据库中,用二维表来逻辑表达)、半结构化数据(HTML)
3. 特征4V
体量大、样式多、处理快(及时性高)、价值大(价值密度低,大量不相关)
4. 挑战
传统网络架构:从垂直(南北向网络流量)访问到水平(东西向)访问
数据中心:同时访问子系统压力大
数据仓库:非结构化数据无法处理
5. 解决
大数据是需求,云计算是解决之道。云计算是平台,大数据是应用。
大数据在云计算平台支撑下,调度下层资源,进行数据源加载、计算和最终结果输出等动作。
二、电信大数据应用
1. 挑战
(1)运营商相关业务得发展更加依赖数据,如传统的语音、窄带、宽带数据,以及超宽带、数字经济等相关业务数据量越来越大;
(2)OTT,虚拟运营商的介入使得运营商竞争环境更加的复杂和激烈;
(3)客户消费模式的改变,需要大数据分析深入洞察用户的需求,进行定制化的服务,改善客户体验;
(4)提供精细化的管理水平,以数据为中心的运营支撑一体化、精细化,数据将成为企业的核心资产。
2. 大数据的总体目标
构建统一的数据采集与整合能力、大数据分析处理能力、计算及数据服务能力、大数据应用能力和互联网化的数据开放能力,支撑业务创新与商业成功。
(1)延长用户生命周期,大数据建模支撑用户全生命周期的营销和维系;
(2)提升业务使用量,基于大数据的营销体系有效运作,支撑多批次、小群体、高成功率、多用户触点的营销;(通信收入)
(3)实现对外合作,MR数字轨迹形成商业价值,用户行为轨迹成为商业价值。(非通信收入)
三、应用场景
场景一、潜在离网用户维挽场景
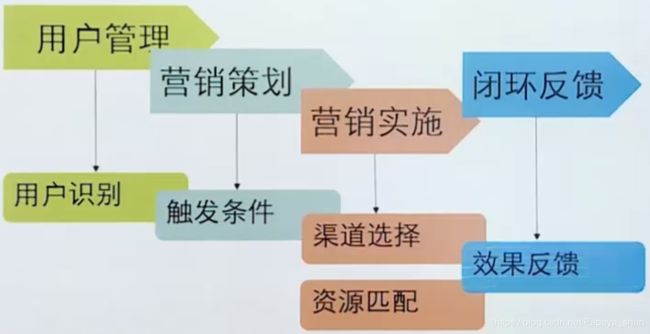
通过大数据的用户管理,对潜在的离网用户进行数据分析,通过大数据实现用户管理、营销策划、营销实施和闭环反馈的拉通。
当海量的用户数量来了之后,用大数据平台对所有用户进行分类、识别和管理,如常见的后付费、预付费。用户识别之后,根据用户的大数据分析结果触发营销策略,如用户的余额不足、签约到期、体验不好投诉或者用户流量溢出时,对其进行分析。对用户在内部进行渠道选择,匹配相应的资源套餐,通过用户的选择来进行效果的反馈。
场景二、综合网管分析平台-基站关联分析场景
根据已离网用户的位置轨迹、用户的业务行为、基站地图以及基站网络质量KPI获得数据源,然后进行大数据的建模分析,判断离网用户是否与其常出没的基站存在关联。进而输出质差基站列表、基站供需平衡度、经常出没已识别质差以及基站的未离网用户列表。最后确定客服务的商用场景,如预付费、后付费维挽场景、网络优化以及4G基站选址等等。
场景三、数据变现场景:户外数字媒体/非数字媒体价值评估场景
现阶段户外媒体行业缺乏受众测量的方法,行业交易混乱,进行户外广告价值的评估。
可以通过大数据平台去分析人流量、车流量、覆盖率等相关信息,根据所得的信息进行统一的管理。获得相应的需求描述,得到目标人群的属性、MR、工参、用户行为、RNC信令、地图等相关数据,同时结合户外的LED广告屏、公交站的广告屏,进而整合所有的数据,得出最终的广告资源价值评估、广告投放效果检测、广告投放时段和内容规划以及精准的营销策划。
未来将进入数字化的服务收入时代,所以就需要建设这样的大数据平台,来支撑自有业务收入提升和支撑非通信价值变现,进而使运营商的业务数字化。
四、企业级大数据平台架构
1. 总体介绍
O域(operation 运营域)、B域(business 业务域)、M域(manage 管理域)
域有用户数据和业务数据,比如用户的消费习惯、终端信息、ARPU的分组、业务内容,业务受众人群等。O域有网络数据,比如信令、告警、故障、网络资源等。M域有位置信息,比如人群流动轨迹、地图信息等。
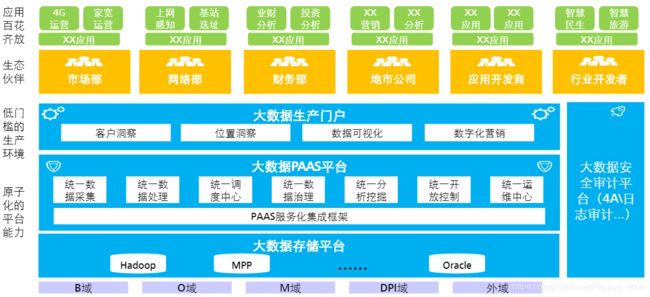
2. 关键技术
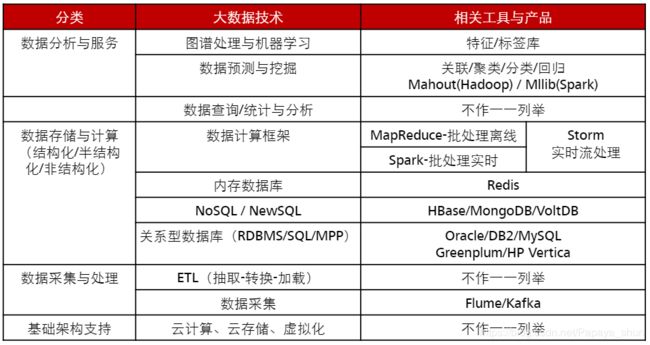
3. 运营流程
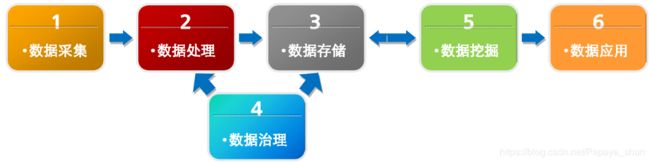
3.1 数据采集
ETL(数据抽取、转换、加载)、Crawler(爬虫)、流处理(Streaming,实时数据)
数据分类:离线数据、实时数据
3.2 数据处理
批处理模式(规模大,常见)、流处理模式(实时性强)
处理方式由库内计算转变为库外计算(Hadoop集群)
3.3 数据存储
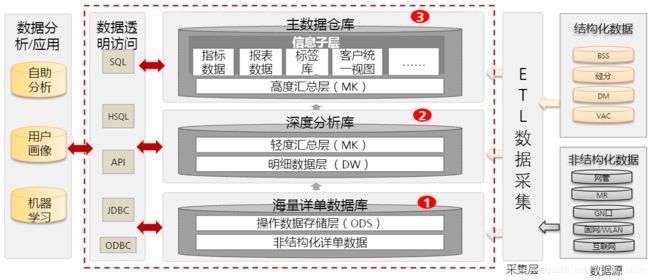
Hadoop:
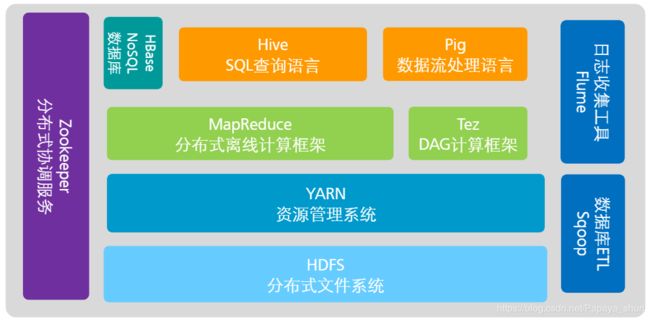
3.4 数据治理
通过数据集成来实现数据的组织和生成,而其关键在于数据治理。
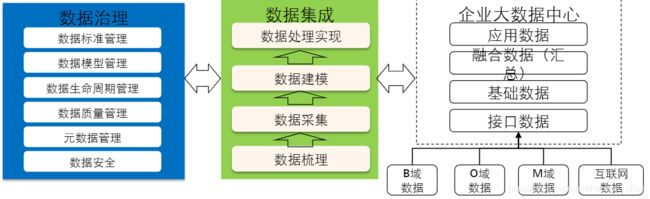
3.5 数据分析与挖掘
输入数据 --> 训练数据 --> 生成模型(预测、评估等)
3.6 数据应用
用户画像,生成用户全景视图
实时营销(发送短信、亚马逊预测配送)
实时监控及热力图
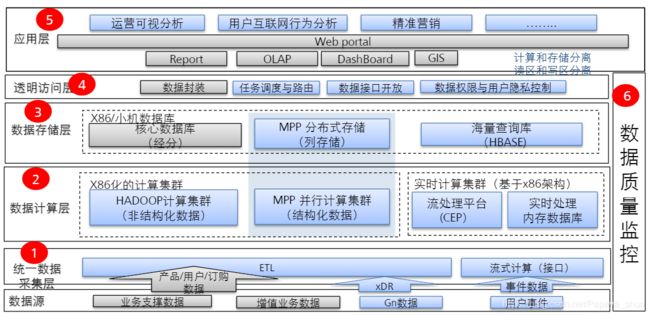
平台架构:
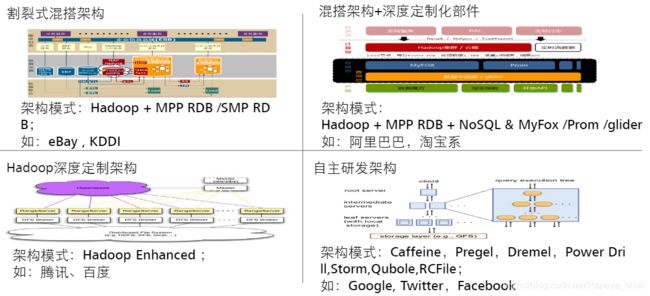
结合运营商需求的混搭架构:
五、Hadoop基础技术
1. 大数据处理技术发展趋势
传统数据处理系统面临的问题:
海量数据的存储成本、有限的扩展能力、数据资产对外增值、大数据处理能力不足、单一数据源、流式数据处理缺失
演变:集群化、实时性、分布式
2. 大数据主要存储技术
-
HDFS
Hadoop Distributed File System 分布式文件系统。
特性:具有高容错、高吞吐量、大文件存储的特性(TB-PB级)。
适合:大文件存储、流式数据访问,一次写入,多次读写;不适合:大量小文件处理、随机写入、低延迟读写。 -
YARN
Hadoop 2.0中的资源管理系统,可为各类应用程序进行资源管理和调度,支持MapReduce离线处理、Spark迭代计算、Storm实时处理等框架。
优势:资源利用率高、运维成本低、数据共享方便。 -
MapReduce
特性:易于编程、良好的扩展性、高容错性。
适合:大规模数据离线批处理、子任务相对独立;不适合:实时交互计算、流式计算、实时分析、子任务相互依赖。 -
Hive
提供数据ETL功能,并可用类似于SQL的语法,对HDFS海量数据库中的数据进行查询统计等操作。 -
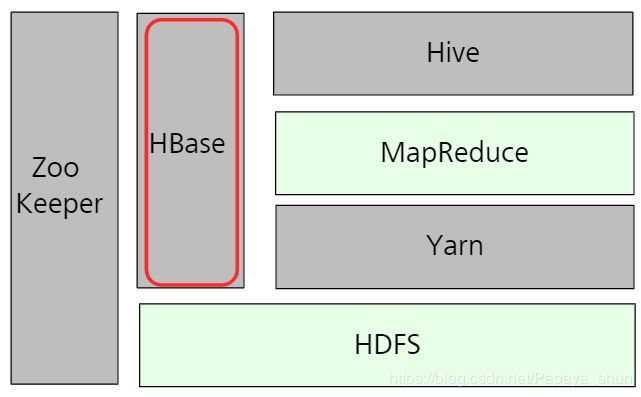
HBase
Hadoop Database,是一个高可用性、高性能、面向列、可伸缩的分布式存储系统,可在廉价PC Server上搭建起大规模结构化存储集群。
-
Spark
分布式批处理系统和分析挖掘引擎,用来快速处理数据,并支持迭代计算,有效对多步的数据处理逻辑。 -
其他技术
Flume是Cloudera的开源日志系统,是一个分布式、可靠、高可用的海量日志聚合系统,支持在系统中定制各类数据发送放,用于收集数据,也提供了对数据进行简单处理和可定制的能力。Kafka是Linkedin开源的分布式的、基于发布/订阅的日志系统,可以在消息队列中保存大量的开销很小的数据,并支持大量的消费者订阅。
3. Hadoop典型应用场景
-
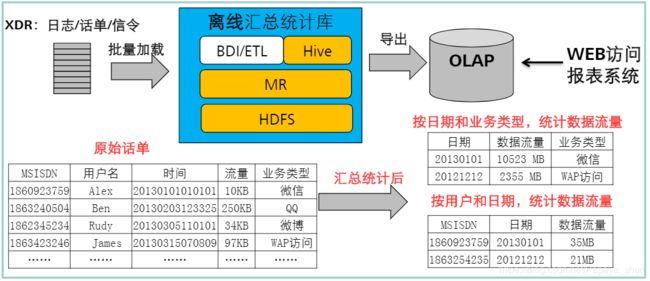
离线统计分析
将海量的原始数据存储到HDFS中,定期离线做汇总统计,按分钟、手机号、地域、业务类型等维度导出到OLAP(联机分析处理)系统用于分析或报表。
-
订单查询
将海量数据的原始XDR(外部数据表示法),加载入库并转换为半结构化的格式,用于低时延查询。

-
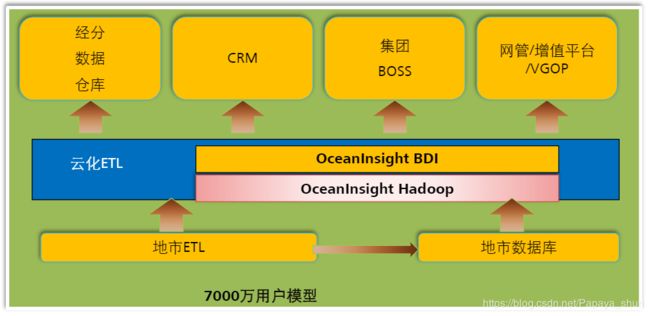
云化ETL
将海量数据存储在分布式存储且能够进行汇总等计算。
六、数据分析与数据挖掘基础
1. 数据挖掘背景
定义:在数据中(半)自动发现隐含的,以前未知的和有价值的信息。
挑战:应用周期长、缺乏实时分析能力、模型设计与优化缺乏辅助工具、使用门槛高。
常用的挖掘软件:HUAWEI Universe SmartMiner、SAS、R、IBM MODELER。
2. 数据挖掘常见算法
| 监督学习 | 无监督学习 |
|---|---|
| Regression(回归) | Clustering(聚类) |
| Classification(分类) | Association(关联) |
| … | Recommendation(推荐) |
| … | … |
关联算法:关联规则;
数值预测:线性回归、时间序列;
分类算法:朴素贝叶斯、随机森林、梯度回归决策树、决策树、逻辑回归;
聚类算法:均值聚类、混合高斯聚类、最小哈希聚类;
降维算法:主成分分析、隐含狄克雷分布;
推荐算法:协同过滤、概率传播、热度传播、相似特征;
社交分析:影响力传播、相似邻近点、全连接子图、页面分级(PageRank);
集成学习:投票、步进优化。
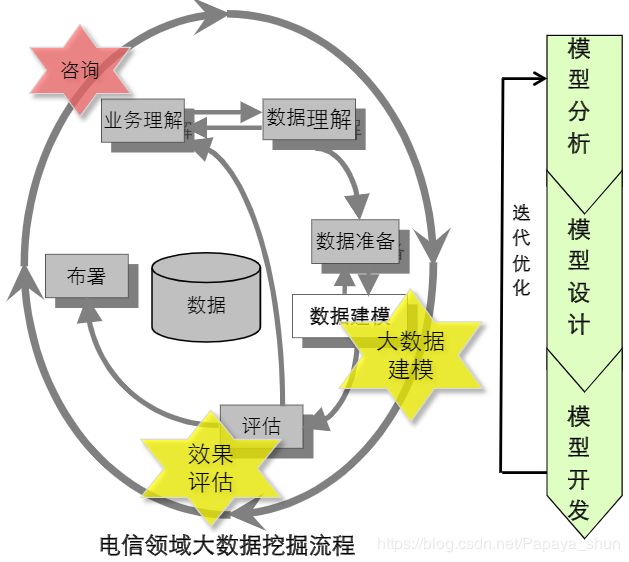
3. 数据挖掘建模方法论
-
总体介绍
-
标准化流程
CRISP-DM定义: