python中使用BeautifulSoup模块爬取中彩网福彩3D的开奖数据
在上一篇博客中,介绍了网络爬虫的基本流程,然后以“使用BeautifulSoup爬取盗版小说网站”的例子对上述流程加以实现。最近看到微信公众号“程序人生”中的一篇文章:点击打开网页,在这篇文章中作者爬取了中彩网福彩3D的开奖数据并对其进行了简单分析。打开福彩3D开奖数据所在的网页,谷歌浏览器F12+F5可以看到这个网站的结构很简单,很适合初学者练手,所以写了这篇博客。建议读者自己先尝试实现本篇博客要实现的功能,然后再阅读本篇博客或者下篇博客看看能否有所收获,这样才能加深自己对网络爬虫的理解,增强自己的实现能力。
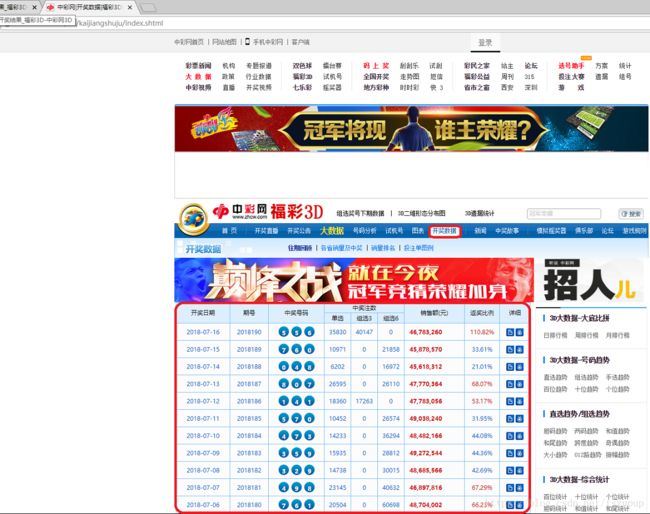
这里我们可以看到网页的结构是比较简单的,开奖数据都存放在tr标签下。
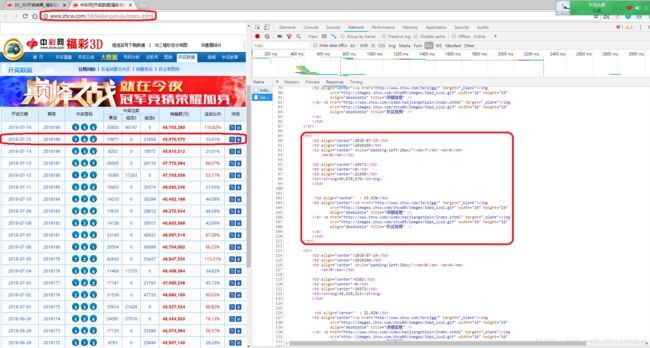
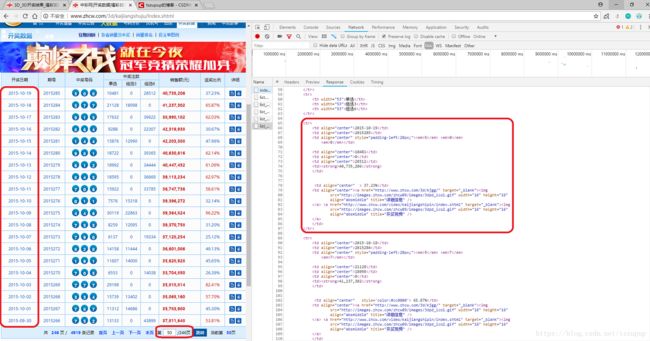
还是上篇博客介绍的 网络爬虫的基本思路:给定url,获取并解析url对应的页面的内容,从而获取所需要的数据或新的url。首先,我们要从首页出发,获取所有页面对应的url。先F12+F5分析页面的真实请求地址:
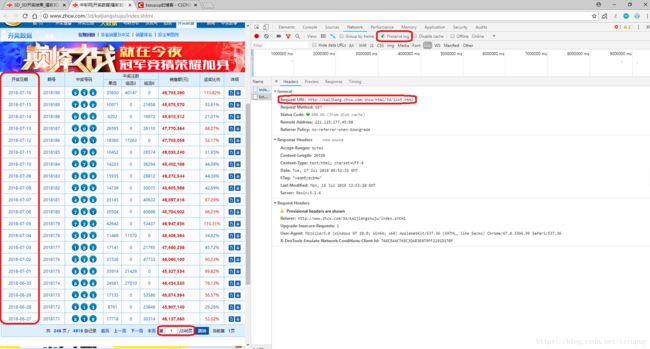


从上图可以看出,每个页面的真实请求地址具有明显的规律性,第k个页面的真实请求地址为:
” http://kaijiang.zhcw.com/zhcw/html/3d/list_k.html”
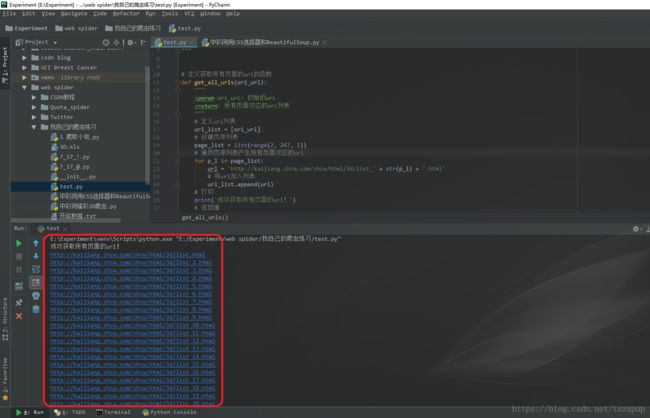
于是我们可以 1 定义获取所有页面对应的url的函数,代码和测试效果如下:
#-*-coding:utf-8-*-
"""
@author:taoshouzheng
@time:2018/7/16 15:34
@email:[email protected]
"""
# 定义获取所有页面的url的函数
def get_all_urls(ori_url):
"""
:param ori_url: 初始的url
:return: 所有页面对应的url列表
"""
# 定义url列表
url_list = [ori_url]
# 创建页序列表
page_list = list(range(2, 247, 1))
# 遍历页序列表产生所有页面对应的url
for p_l in page_list:
url = 'http://kaijiang.zhcw.com/zhcw/html/3d/list_' + str(p_l) + '.html'
# 将url加入列表
url_list.append(url)
# 打印
print('成功获取所有页面的url!')
# 返回值
return url_list
# 主模块
if __name__ == "__main__":
# 调用函数
all_url_list = get_all_urls('http://kaijiang.zhcw.com/zhcw/html/3d/list.html')
# 遍历url列表
for url in all_url_list:
# 打印
print(url)

2 针对一个具体的页面,定义解析该页面的函数
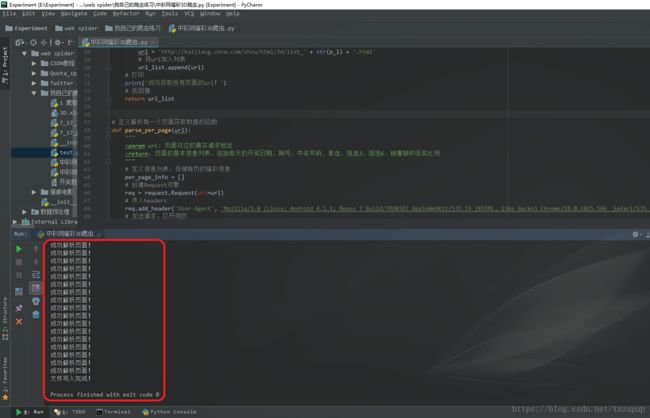
这里使用了BeautifulSoup模块对页面内容进行解析,并将每天的福彩数据存放在一维列表中,将每页的福彩数据存放在二维数组中,代码和测试效果如下:
#-*-coding:utf-8-*-
"""
@author:taoshouzheng
@time:2018/7/16 15:34
@email:[email protected]
"""
from urllib import request
from bs4 import BeautifulSoup
import numpy as np
# 定义解析每一个页面获取数据的函数
def parse_per_page(url):
"""
:param url: 页面对应的真实请求地址
:return: 页面的基本信息列表,包括每天的开奖日期、期号、中奖号码、单选、组选3、组选6、销售额和返奖比例
"""
# 定义信息列表,存储每页的福彩信息
per_page_info = []
# 创建Request对象
req = request.Request(url=url)
# 传入headers
req.add_header('User-Agent', 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19')
# 发送请求,打开网页
response = request.urlopen(req, timeout=10) # 浏览器要在10个单位时间内获取响应
# 读取网页内容,重新编码
html = response.read().decode('utf-8')
# 创建BeautifulSoup对象,解析网页获取所需内容
html_soup = BeautifulSoup(html, 'html.parser')
# 找到网页中存放数据的表格所对应的标签
table_tag = html_soup.find_all(width='718', border='0', cellspacing='0', cellpadding='0', class_='wqhgt')
# 创建BeautifulSoup对象,解析网页获取所需内容
table_soup = BeautifulSoup(str(table_tag), 'html.parser')
# 获取table标签的子标签列表
tr_list = table_soup.table.contents
# 剔除列表中的换行符
while '\n' in tr_list:
tr_list.remove('\n')
# 遍历列表
for tr in tr_list[2:-1]: # 过滤掉表头部分和页标部分所对应的标签
# 定义信息列表,存储每天的福彩信息
per_day_info = []
# 对于列表中的每一个标签,创建BeautifulSoup对象,获取所需内容
tr_soup = BeautifulSoup(str(tr), 'html.parser')
# 获取td标签列表
td_list = tr_soup.find_all('td')
# 遍历td列表
for td in td_list[:8]:
# 创建BeautifulSoup对象进行解析
td_soup = BeautifulSoup(str(td), 'html.parser')
# 某一个td标签在列表中的索引
td_index = td_list.index(td)
# 中奖号码标签
if td_index == 2: # 通过索引匹配
# 获取em标签
em_list = td_soup.find_all('em')
# 中奖号码字符串
em_string = ''
for em in em_list:
# 创建BeautifulSoup对象进行解析
em_soup = BeautifulSoup(str(em), 'html.parser')
em_string = em_string + str(em_soup.em.string)
# 将元素加入列表
per_day_info.append(em_string)
# 获取销售额(元)
elif td_index == 6:
# 将元素加入列表
per_day_info.append(td_soup.strong.string)
else:
per_day_info.append(td_soup.td.string)
# 将每日的福彩信息加入页信息列表
per_page_info.append(per_day_info)
# 打印消息
print('成功解析页面!')
# 返回值
return per_page_info
# 主模块
if __name__ == "__main__":
# 以第一页为例,调用函数,查看效果
page_data = parse_per_page('http://kaijiang.zhcw.com/zhcw/html/3d/list.html')
# 将列表转化为数组
page_data_array = np.array(page_data)
# 打印
print(page_data_array)

最后,遍历url列表中的url,针对每一个url,调用解析函数对相应页面进行解析,完整程序如下:
#-*-coding:utf-8-*-
"""
@author:taoshouzheng
@time:2018/7/16 15:34
@email:[email protected]
"""
from urllib import request
from bs4 import BeautifulSoup
import numpy as np
"""爬取中彩网福彩3D的开奖数据并将其以txt、excel和数据库的形式保存"""
# 定义获取所有页面的url的函数
def get_all_urls(ori_url):
"""
:param ori_url: 初始的url
:return: 所有页面对应的url列表
"""
# 定义url列表
url_list = [ori_url]
# 创建页序列表
page_list = list(range(2, 247, 1))
# 遍历页序列表产生所有页面对应的url
for p_l in page_list:
url = 'http://kaijiang.zhcw.com/zhcw/html/3d/list_' + str(p_l) + '.html'
# 将url加入列表
url_list.append(url)
# 打印
print('成功获取所有页面的url!')
# 返回值
return url_list
# 定义解析每一个页面获取数据的函数
def parse_per_page(url):
"""
:param url: 页面对应的真实请求地址
:return: 页面的基本信息列表,包括每天的开奖日期、期号、中奖号码、单选、组选3、组选6、销售额和返奖比例
"""
# 定义信息列表,存储每页的福彩信息
per_page_info = []
# 创建Request对象
req = request.Request(url=url)
# 传入headers
req.add_header('User-Agent', 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19')
# 发送请求,打开网页
response = request.urlopen(req, timeout=10) # 浏览器要在10个单位时间内获取响应
# 读取网页内容,重新编码
html = response.read().decode('utf-8')
# 创建BeautifulSoup对象,解析网页获取所需内容
html_soup = BeautifulSoup(html, 'html.parser')
# 找到网页中存放数据的表格所对应的标签
table_tag = html_soup.find_all(width='718', border='0', cellspacing='0', cellpadding='0', class_='wqhgt')
# 创建BeautifulSoup对象,解析网页获取所需内容
table_soup = BeautifulSoup(str(table_tag), 'html.parser')
# 获取table标签的子标签列表
tr_list = table_soup.table.contents
# 剔除列表中的换行符
while '\n' in tr_list:
tr_list.remove('\n')
# 遍历列表
for tr in tr_list[2:-1]: # 过滤掉表头部分和页标部分所对应的标签
# 定义信息列表,存储每天的福彩信息
per_day_info = []
# 对于列表中的每一个标签,创建BeautifulSoup对象,获取所需内容
tr_soup = BeautifulSoup(str(tr), 'html.parser')
# 获取td标签列表
td_list = tr_soup.find_all('td')
# 遍历td列表
for td in td_list[:8]:
# 创建BeautifulSoup对象进行解析
td_soup = BeautifulSoup(str(td), 'html.parser')
# 某一个td标签在列表中的索引
td_index = td_list.index(td)
# 中奖号码标签
if td_index == 2: # 通过索引匹配
# 获取em标签
em_list = td_soup.find_all('em')
# 中奖号码字符串
em_string = ''
for em in em_list:
# 创建BeautifulSoup对象进行解析
em_soup = BeautifulSoup(str(em), 'html.parser')
em_string = em_string + str(em_soup.em.string)
# 将元素加入列表
per_day_info.append(em_string)
# 获取销售额(元)
elif td_index == 6:
# 将元素加入列表
per_day_info.append(td_soup.strong.string)
else:
per_day_info.append(td_soup.td.string)
# 将每日的福彩信息加入页信息列表
per_page_info.append(per_day_info)
# 打印消息
print('成功解析页面!')
# 返回值
return per_page_info
# 主模块
if __name__ == "__main__":
# 创建列表用于存放所有信息
all_data = []
# 调用函数,获取所有页面对应的url列表
all_url_list = get_all_urls('http://kaijiang.zhcw.com/zhcw/html/3d/list.html')
# 遍历url列表
for url in all_url_list:
# 调用函数,获取每一个页面的数据
per_page_data = parse_per_page(url=url)
# 将每页的数据放入总的二维数据列表中
all_data.extend(per_page_data)
# 将列表转化为数组
all_data_array = np.array(all_data)
# 表头信息
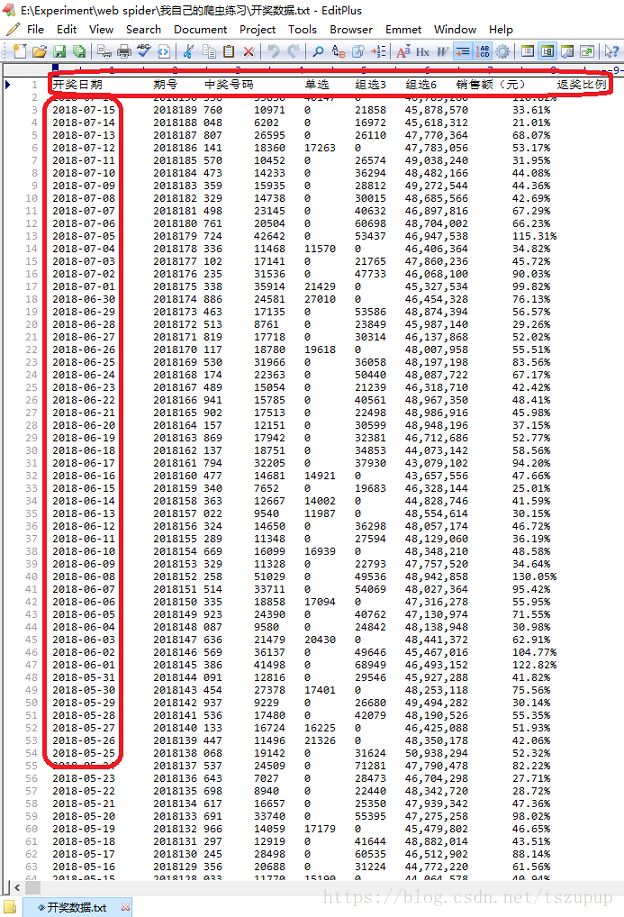
header = '开奖日期' + '\t' + '期号' + '\t' + '中奖号码' + '\t' + '单选' + '\t' + '组选3' + '\t' + '组选6' + '\t' + '销售额(元)' + '\t' + '返奖比例'
# 将数组中元素写入txt文件中
np.savetxt('开奖数据.txt', all_data_array, fmt='%s', delimiter='\t', header=header, comments='', encoding='utf-8')
# 打印
print('文件写入完成!')
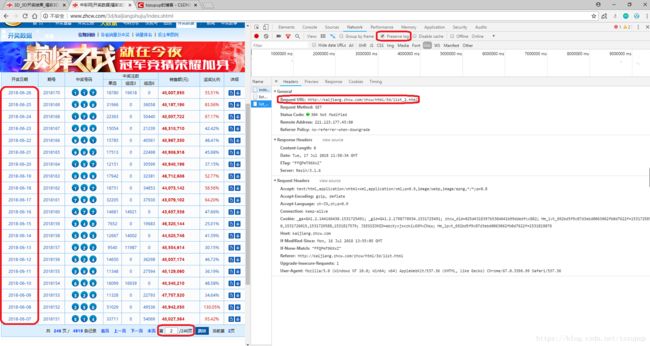
以前50个页面为例对以上程序进行测试,效果如下:
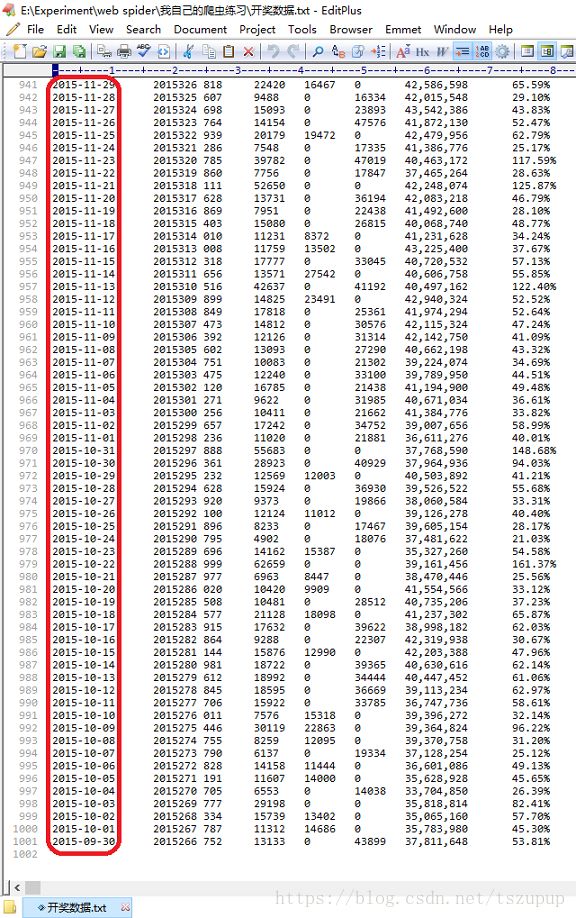
一点体会:
写爬虫程序的时候一定要有耐心;
学习模块和方法时一定要搞明白方法的输入输出是什么样的、有哪些参数可以用;
养成注释代码的习惯,遇到bug时要敢去调。
欢迎交流! QQ:3408649893